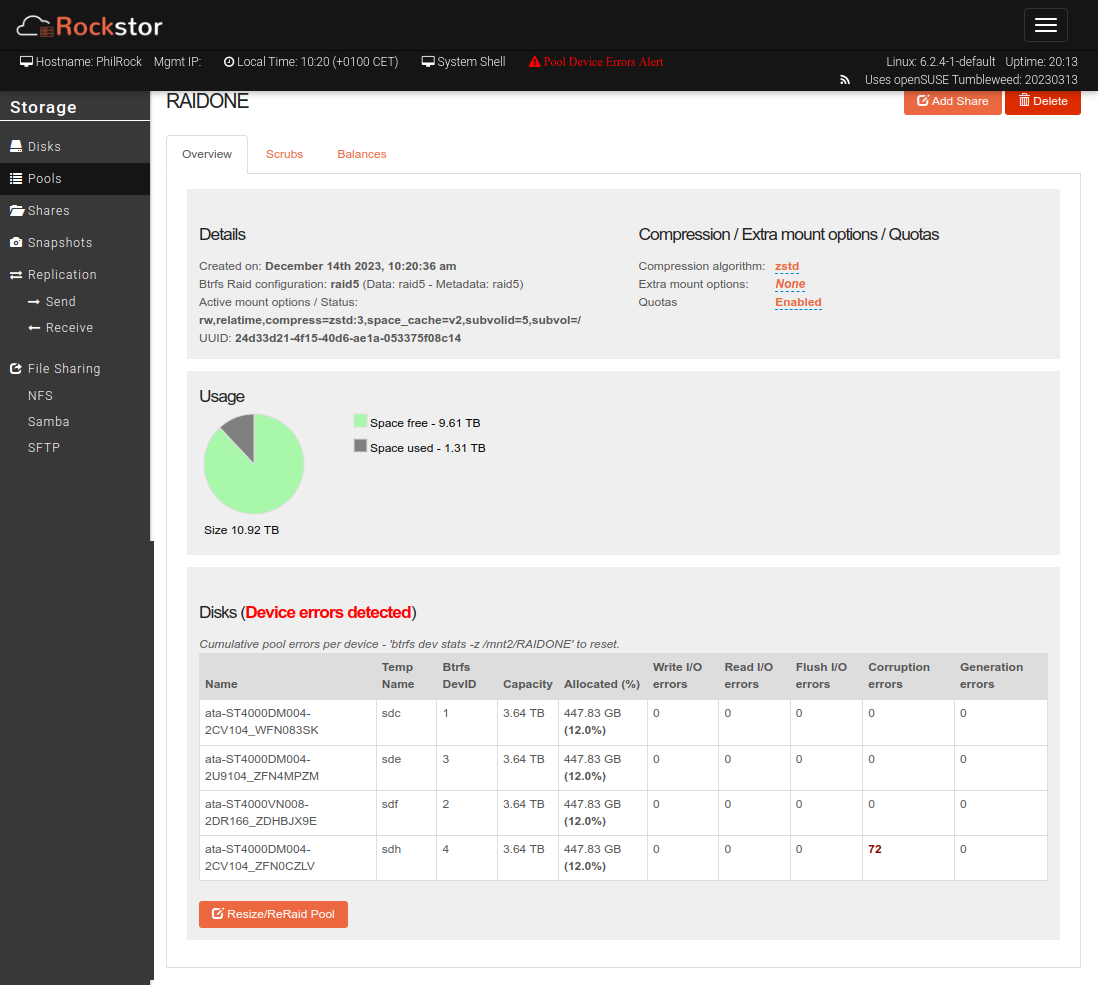
From my workstation, I ran an rsync command to synchronize my home directory to Rockstor storage. I had previously executed this request without any problems. However, on the last run, my rsync command seemed to freeze completely.
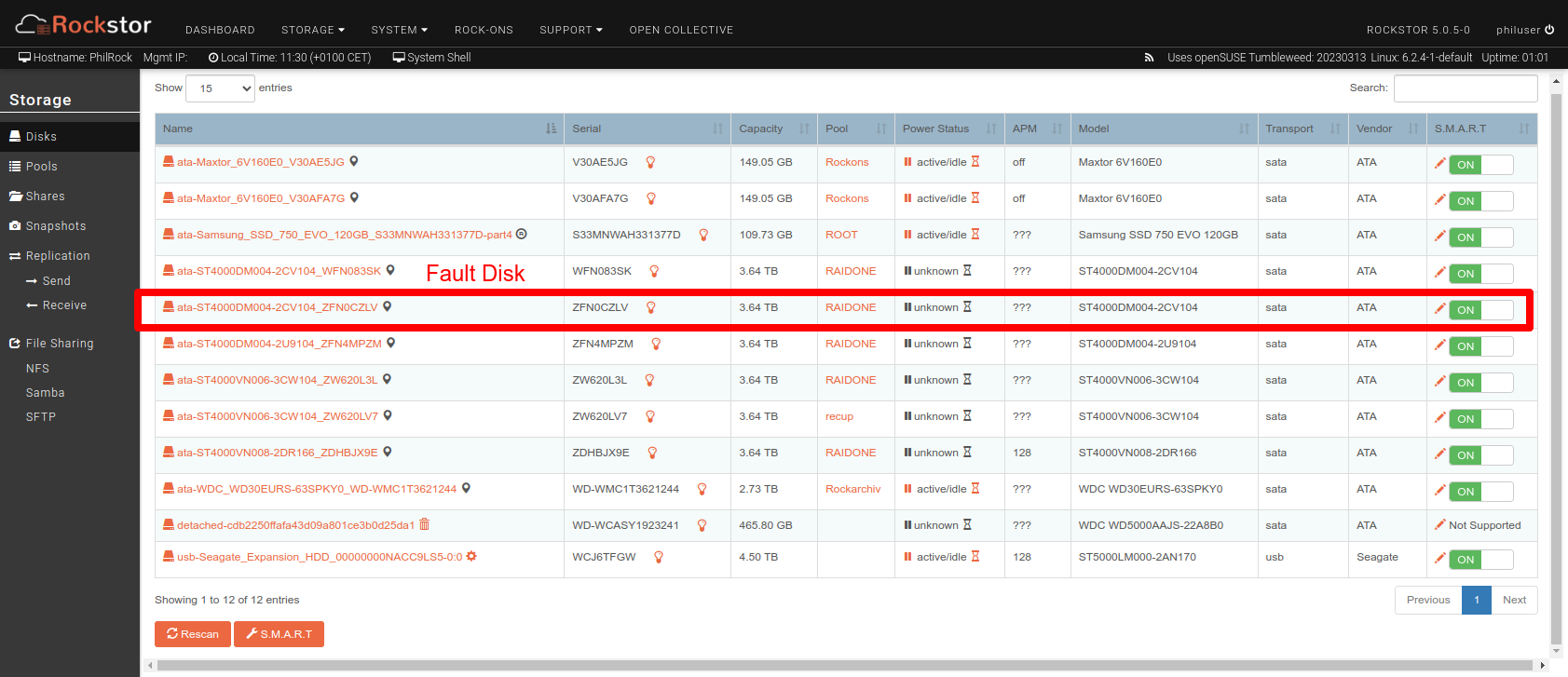
After noticing Disks (Devive errors detected) errors, which are certainly the cause of my frozen rsync
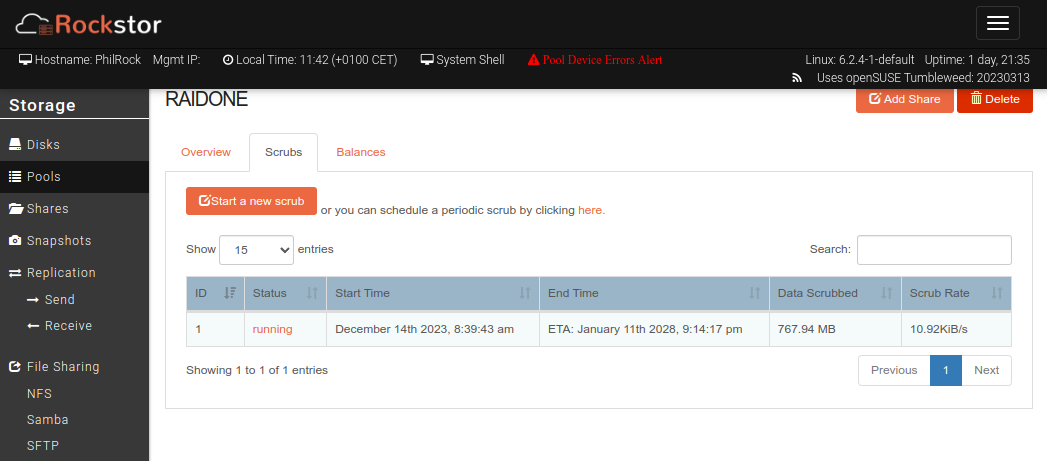
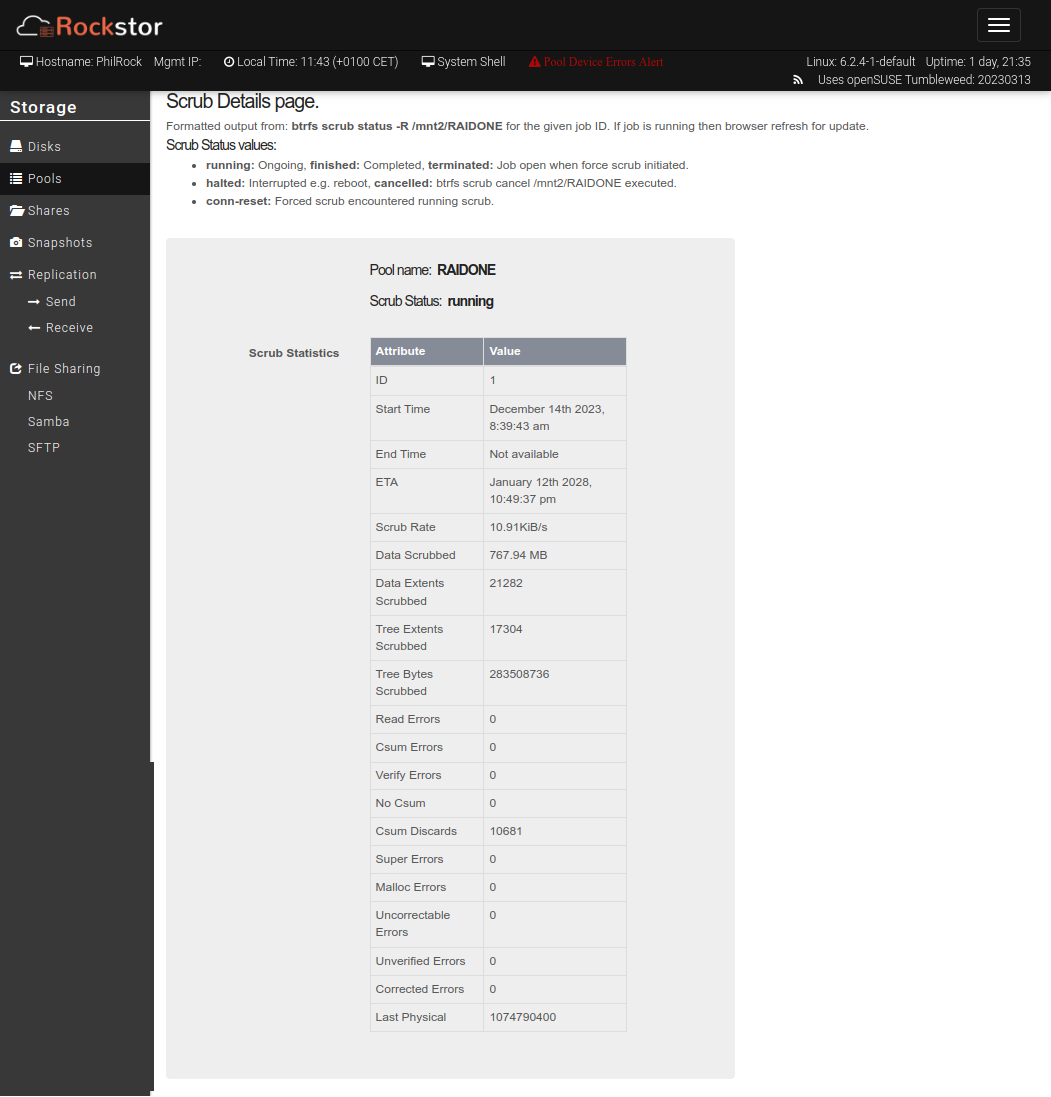
I resolve to run a scrub, which should allow the underlying btrfs system to correct these errors. But it’s been over a day since the scrub was launched, and to my horror Rockstor announces that the process will end in 2028!
Not sure about the wisdom bit, but i might be best to confirm first our interpretation/parsing of the underlying info here, as a first step: i.e. check as the root user the output of the command indicated in the text. If we are parsing correctly, you may have a drive that has failed in such a way that it has slowed to a crawl. Ergo estimate correct but untenable - without a lot of patience and belief that it won’t get any worse in the proceeding 5 years :).
So if this is a massive slow-down failure, i.e. drive is re-trying many many times and still failing to store/retrieve what was asked of it; leading to yet more slow-downs as as btrfs has retried to reestablish a correct copy, you should take a different approach here and start by cancelling this scrub.
Once cancelled, given the suspected very poorly nature/performance of the suspect drive, you may want to attempt a pool repair via CLI removal from pool of the suspect drive. I suggest CLI here as we don’t yet implement a no write disk replace function:
Note the Note/Warning coloured sections in that doc sub-section:
Note
An important function of ´btrfs replace´ is its ability, via an optional switch “-r”, to only read from the to-be-replaced drive if no other zero-defect mirror exists. This is particularly noteworthy in a data recovery scenario. Failing drives often have read errors or are very slow to achieve error free reads. See our dedicated Replacing a failing but still working drive section which uses this options.
Warning
In some cases a Btrfs replace operation can leave a pool between redundancy levels. This presents a risk to data integrity. Please see our Re-establish redundancy section for details.
Given you have currently only 4 drives in a raid5 data raid5 metadata pool you may not want to reduce that to the practical minimum of 3, but you do still have a single drive removal (or even disconnect) option here with subsequent degraded remount/repair. But the parity raids are not favourite on the repair and speed front.
So maybe the dedicated linked doc section in the above notes/warnings is your go-to here:
In the case of a failing disk the ‘replace’ work-around of disk add/remove or remove/add, referenced in our sub-section header Btrfs replace, is far from optimal. The extreme reads/writes associated with these steps could fully fail an otherwise borderline functional device. Potentially failing the entire pool. After adding a disk Rockstor automatically does a full balance, to enhance ease of use; at the cost of performance. And btrfs itself does an internal balances to effect a drive removal.
For whatever reason, it can sometimes be preferred to do an in-place direct drive replacement. Depending on the btrfs-raid level used, this may also be your only option.
So when a direct disk replacement is required, the command line is also required.
Note from above doc section:
Note the use of the “-r” option. This is precautionary: only read from the to-be-replaced drive if no other zero-defect mirror exists. An optimal arrangement for a failing disk. If you are just after the fastest command line disk replacement, and all disks are known good, this option can be removed for improved performance.
Note the doc section has an example command where one can follow the status/progress of a requested replace. Hopefully it will take less than the next 5 years!
As always, refresh any back-ups if need be as these are large and thus risky operations.
Thanks phil for your quick reply
Just as I feared, I’ve been running a btrfs scrub cancel /mnt2/RAIDONE for several hours. In the list of Linux processes, it’s assigned a +D state “The process is in uninterruptible sleep mode (usually waiting for input/output).” and the initial brtfs scrub is still waiting for a Sl state in multithreaded sleep!
Anyway, I’ve just ordered 2 replacement disks, and I’ll be switching over this weekend.
Question: in this situation where I’m unable to stop the scrub via a normal process, what is the risk to the data in the raid5 pool when Rockstore is shut down? this will be necessary to add my new disks. Or what’s the best way to do this?
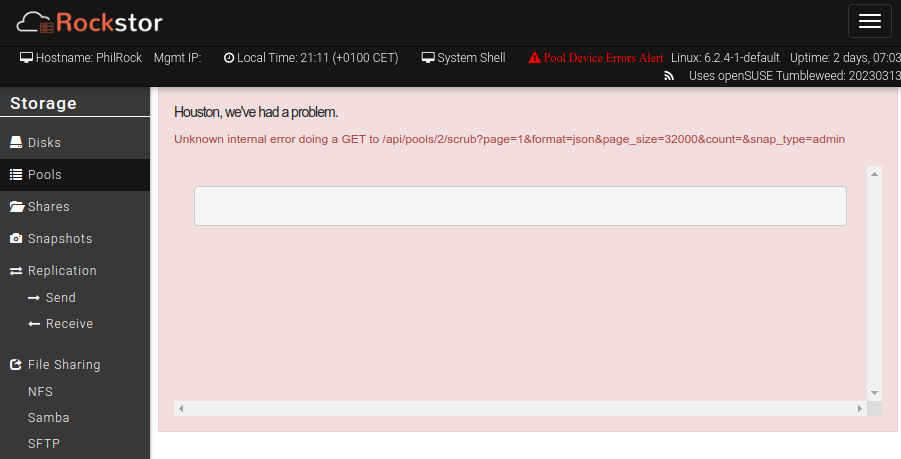
I don’t know what to do with this error. Unknown internal error doing a GET to /api/pools/2/scrub?page=1&format=json&page_size=32000&count=&snap_type=admin
if you query the scrub status using the command line, what are you getting back? Maybe that status cannot be interpreted correctly by the api/UI …
btrfs scrub status -R /mnt2/RAIDONE
Looking at your first screenshot, since you’re using Tumbleweed, I assume your btrfs --version comes back as 6.4.2 or something similar, correct? The version drives Rockstor’s behavior on how to format the returned status behavior (legacy below 5.1.2 vs. non-legacy above 5.1.2), since around that time the status output format changed.
Determined via this:
and the output is done via
which then decides whether the “raw output” can be used, or the newer “extra” format needs to be processed.
I’ve really been stuck for 5 days, due to the failure of a disk in a Raid5 pool, unable to remove or add a new disk to the pool. The steps in my restoration attempt:
After reporting a problem in the pool via the WEBUI interface, the detailed view of the pool showed me precisely the problematic disk, with a request to perform a scrub. This scrub was blocked, as I explained in my previous messages. So I killed the scrub! Even the command suggested by @Hooverdanbtrfs scrub status -R /mnt2/RAIDONE remained pending indefinitely. So I stopped Rockstor, ‘physically’ disassembled the failing disk, and reassembled it on a new workstation under a brtfs ARCH, for disk analysis. The smartctl -a, smartctl -x and smartctl -l farm tests revealed no anomalies. On the other hand, btrfs commands on the disk fail as follows: btrfs check --repair /dev/sda returns : enabling repair mode WARNING ... Starting repair. opening filesystem to check... warning, device 2 is missing warning, device 3 is missing warning, device 1 is missing bad tree block 3609219432448, bytenr mismatch, want=3609219432448, have=0 ERROR: cannot read chunk root ERROR: cannot open file system
For the command sudo btrfs rescue super-recover /dev/sda I get the return :
All supers are valid, no need to recover", so no need to worry about superblock integrity.
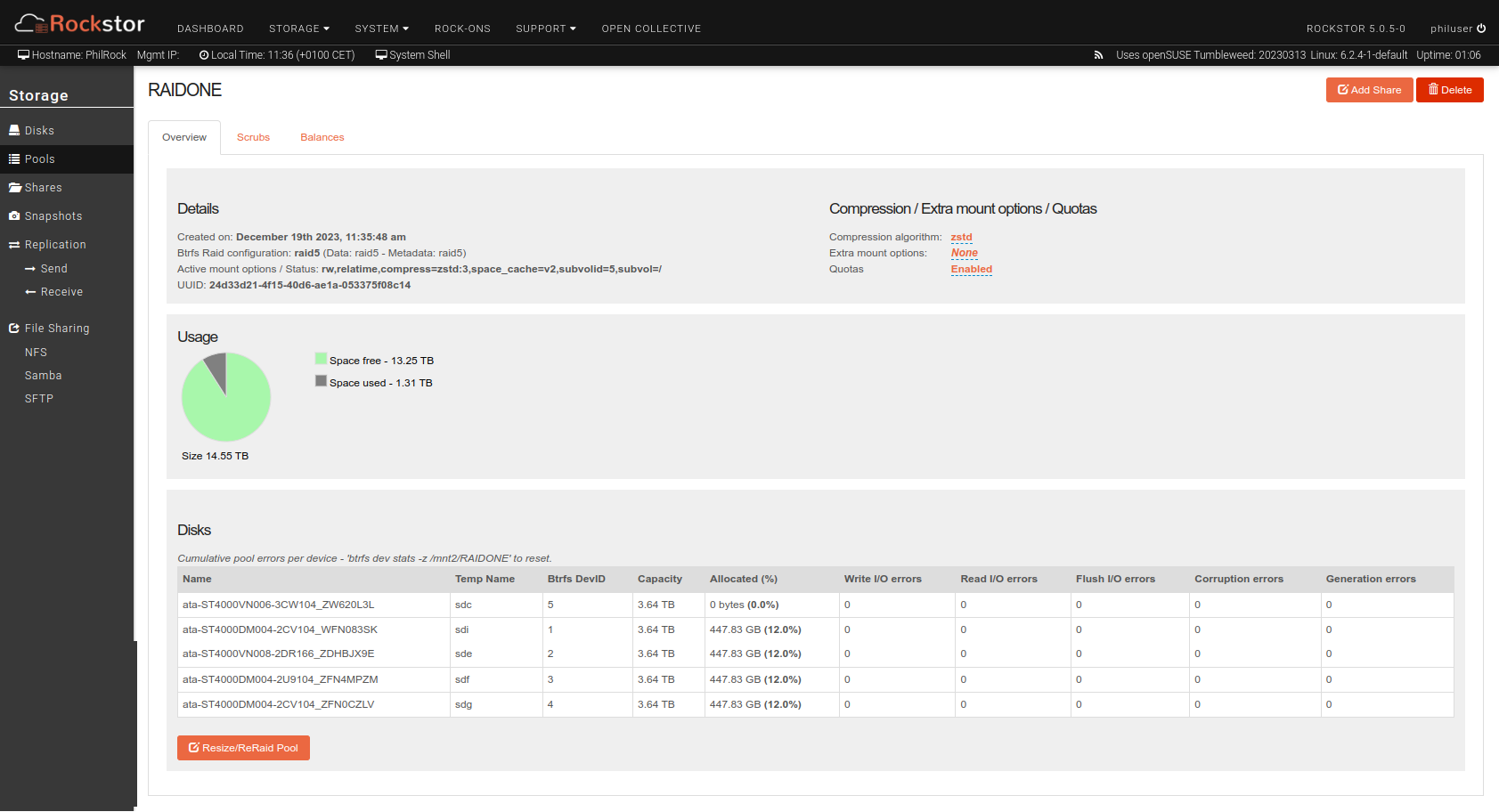
Meanwhile, on the Rockstor workstation, I’ve tried to add a new disk to the Raid5 pool, which seems to be accepted, but the data distribution in the pool is not working. In the pool detail view, the new disk remains Allocated (%) = 0 bytes (0.0%).
I can’t remove the failed disk from the raid5 pool and I can’t add a new disk.
I keep reading that the --repair option is always accompanied with the warning that it could make things worse, but in your case, you can’t even get it started.
To me, this one jumps out:
This seems to be usually associated with some metadata tree issues.
If you try to run btrfs rescue chunk-recover - though that is a slow process since it does a whole device scan
My concern is that currently any btrfs .. commands on the raid5 pool in question, i.e. /mnt2/RAIDONE immediately go into D+ mode, presumably waiting for the pool to go into degraded mode. I think this should be my pool’s current mode, and that’s my problem, as Rockstore persists in keeping it in normal mode. How can I make Rockstore understand to switch the pool to downgraded mode?
Problem solved, but I had to use the CLI interface and btrfs commands.
First I had to remove the replacement disk from the raid5 cluster RAIDONE with a command btrfs device remove /dev/sdg /mnt2/RAIDONE , then physically reinstall the faulty disk in the raid5 cluster
Finally, logically replace btrfs the faulty disk positioned as disk 4 in the raid5 cluster with the replacement disk now positioned as /dev/sdc but not mounted, via the command btrfs replace start 4 /dev/sdc /mnt2/RAIDONE.
To get an idea of how the integration of the new disk is progressing, use the command btrfs replace status /mnt2/RAIDONE.
Question: in this situation, what use is Rockstor’s WEBUI interface?
If I’ve understood it correctly, Rockstor is just a WEB interface that hides the btrfs commands.
At the very least, this makes me understand the great interest of the BTRFS file manager.
@philuser Glad you are finally getting this sorted. So frustrating when stuff just blocks. The btrfs parity raids profiles are not best pre-disposed this way just yet.
Re:
I see you didn’t go for the read-only option:
That would have been advisable I think. But from your report it looks to be working.
To clarify has the replace now finished successfully?
As for what the Web-UI makes of a replace: It will likely be a little confused while the process in ‘in-flight’ as we just haven’t yet made it aware of this state, see the sighted issue earlier in this thread. I’m eager to get this in however but it won’t be until after our next stable release as we are now on the next home-run towards the next stable release with the testing channel.
Yes, but we also simplify the options available. This makes for an easier experience/understanding, i.e we only support a set subvolume arrangement etc (depth wise) and we don’t support all features. But that is expanding over time; but so are the features from upstream. Likely we will never support all capabilities as some like seed devices just don’t have a place (at least just yet) in our application approach to the underlying fs capabilities. But we have recently expanded into the realm of mixed raid profiles, i.e for data & metadata, which was a nice addition.
Yes, it does have some amazing flexibility: which is super useful as we can then offer such things as the on-line rezise (our ReRaid). But we have quite a few restrictions of our own (renaming for example) that we have only part implemented. But all in good time.
But above all it’s the resumption of my backups with rsync on the RAIDONE cluster which is fully operational again with a speed in line with what they should be.
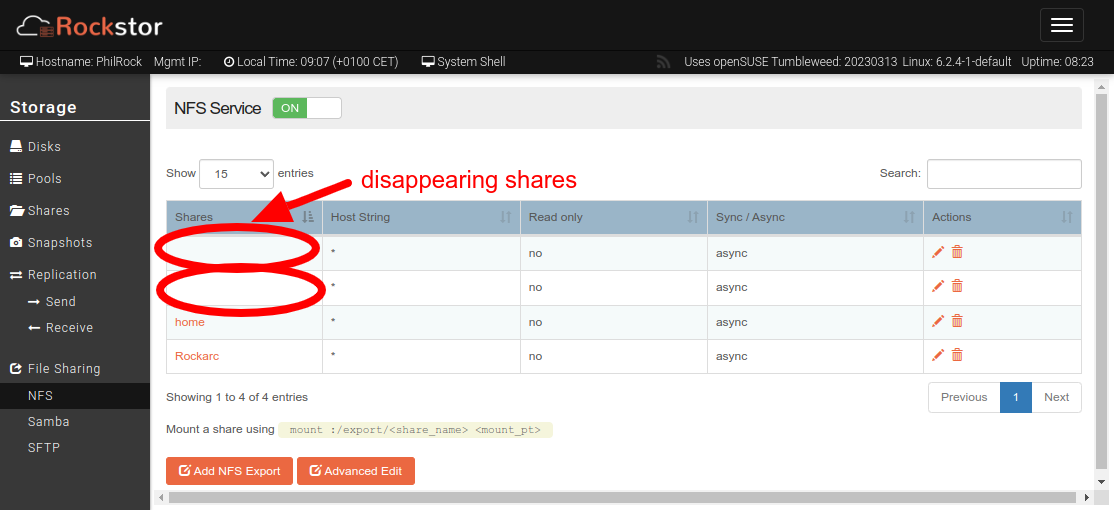
On returning to the WEBUI interface, I noticed a few small imperfections, particularly in the display of NFS shares as indicated.
Of course, this was also deleted in /etc/export, so deleting the shares in question and then regenerating them again quickly solved the problem. But that just goes to show that the consistency of the WEBUI interface still needs to be fine-tuned.
I’m sorry if I was a bit harsh in my previous message, but after five days of struggling, it’s understandable.
Thank you all for your extremely rapid feedback, which is helping me to find a solution to this incident.