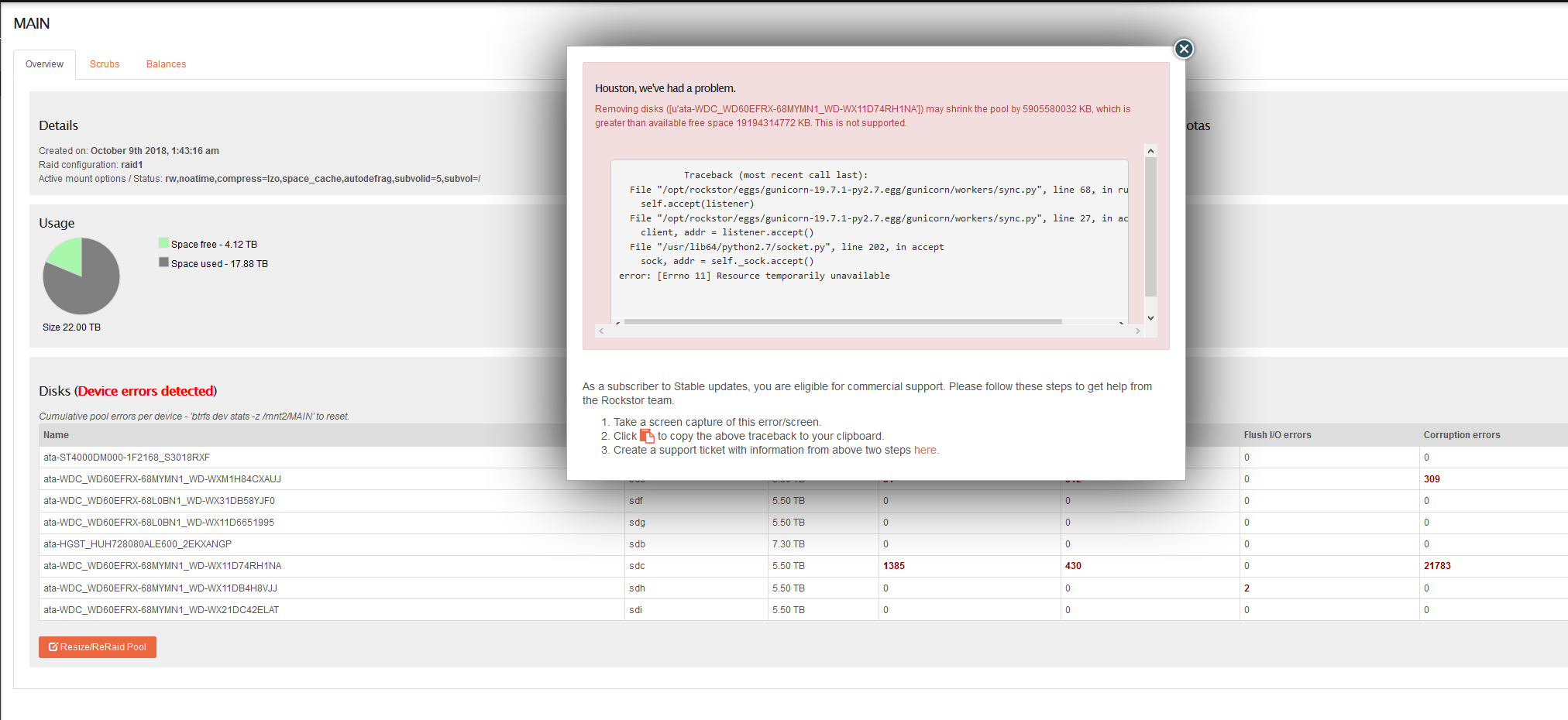
Hi, I’m trying to remove a failing disk from my storage array (RAID 1), but I keep getting the error below:
Traceback (most recent call last):
File “/opt/rockstor/eggs/gunicorn-19.7.1-py2.7.egg/gunicorn/workers/sync.py”, line 68, in run_for_one
self.accept(listener)
File “/opt/rockstor/eggs/gunicorn-19.7.1-py2.7.egg/gunicorn/workers/sync.py”, line 27, in accept
client, addr = listener.accept()
File “/usr/lib64/python2.7/socket.py”, line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
The error states that I don’t have enough room to remove a drive, but it looks like I do. Here’s the error text:
_Removing disks ([u’ata-WDC_WD60EFRX-68MYMN1_WD-WX11D74RH1NA’]) may shrink the pool by 5905580032 KB, which is greater than available free space 19137753968 KB. This is not supported. _
From your screen grab you look to be running the latest stable channel, always best to give the version you are running however, just in case we cant’ see it.
We do have an outstanding issue on this ‘play safe’ calculation and although the message indicates one space value the pie chart is giving 4.12 TB free. It may be that this message is keying from one free space value and displaying another. The issue for reference is:
Where we plan to move to space used on the device rather than the entire size of the device, ie currently 5.5 TB device when only (from pie chart) 4.2 TB free).
The issue references the code concerned but it’s essentially here:
You could, for the time being, carefully alter that code so that it doesn’t trigger if you are certain you have enough free space to perform this action. I.e. you could just comment out (adding a “#” to each of those lines) being careful to maintain the indentation (Python is very fussy that way) and then the check will not be performed at all: after a reboot or rockstor service restart to pick up the code change.
I’ve added your report to that issue and hopefully someone will step up to that one soon.
I’d also make sure of the reported usage; given the conflicting values of the pie chart and the error dialog on the actual pool usage:
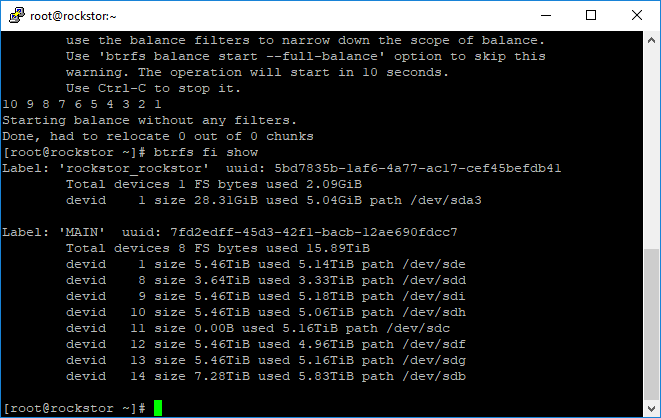
btrfs fi usage /mnt2/MAIN
Hope that helps and do post your usage figures as we may be looking at a different issue / bug here.
Thanks again for the report and let us know how it goes.
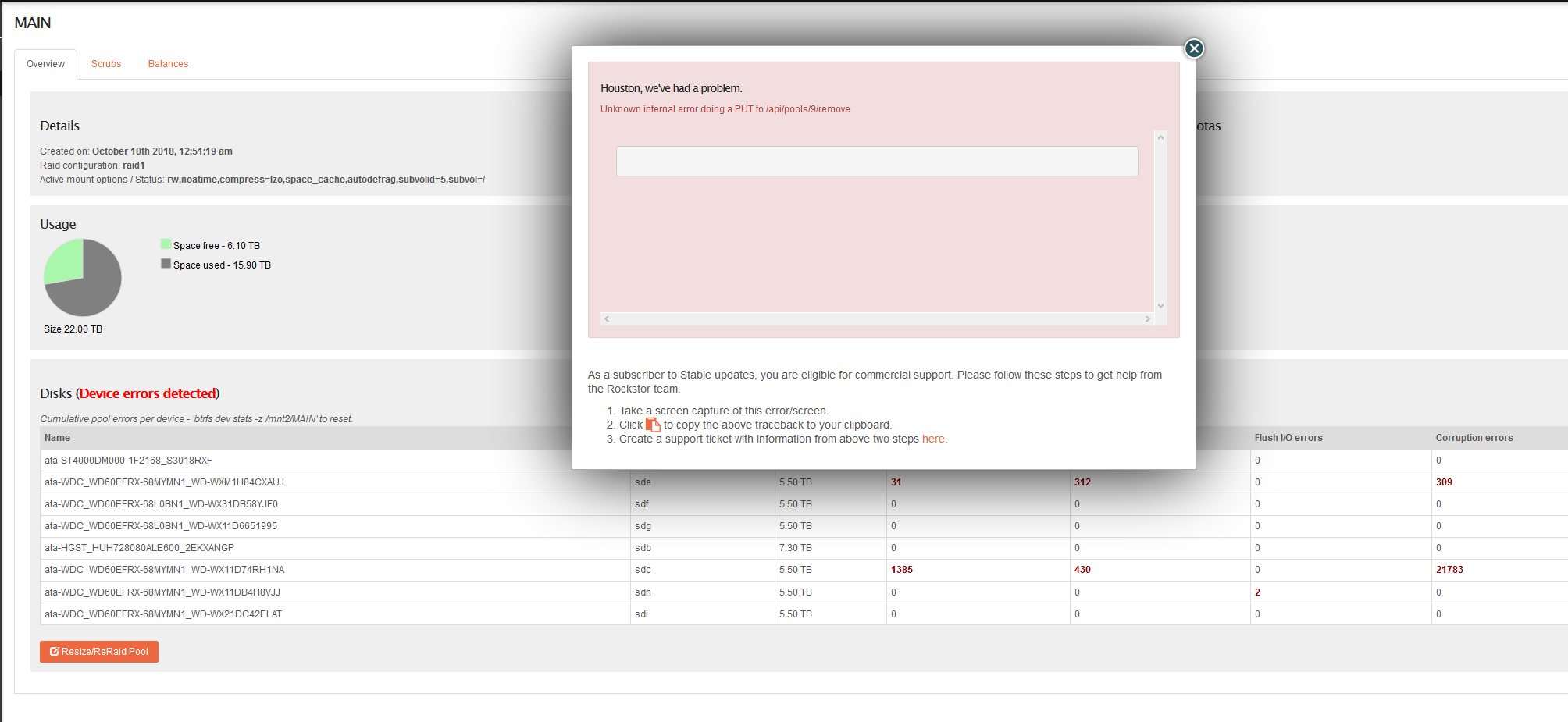
Thanks for the info Phil, but it looks like we’ve gone from bad to worse (see error below). I should add that I opted to clear out more space instead of modifying files:
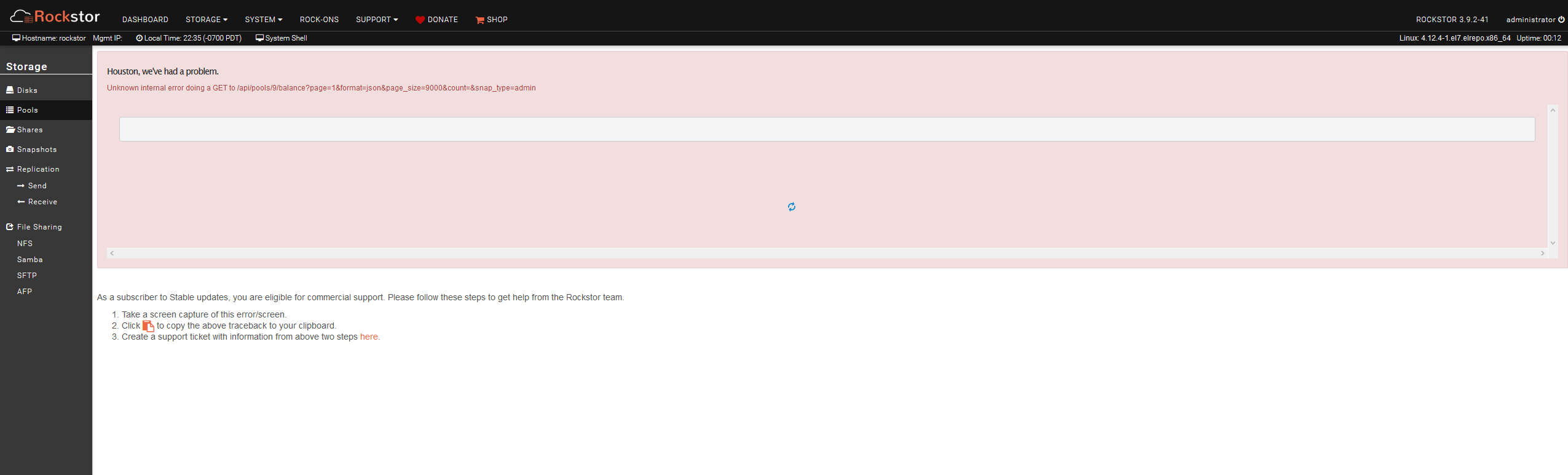
Update: The web gui refuses to show the “Disks” or “Pools” pages and just threw an unknown error. Not sure whether something is going on in the background, but this post from 2017 seems to indicate that this is normal. I would’ve thought that this issue would have been taken care of sooner rather than later, but maybe that’s not the case?
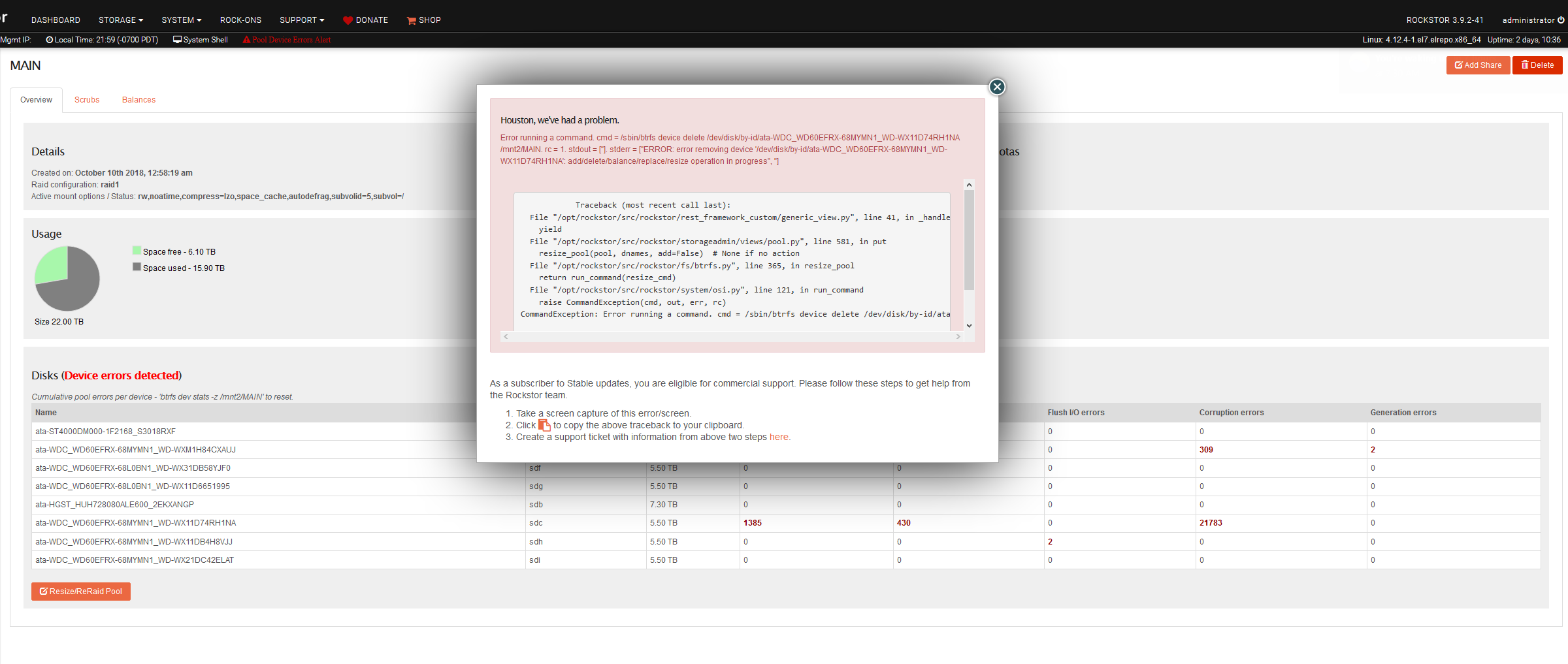
@juchong So it does look like you have progress on this one as:
and your sighted image containing the:
“Unknown internal error doing a PUT to /api/pools/9/remove”
is as you later surmised a known issue which has recently received some updates that pin down exactly why it’s happening (see the latest comments by me) in the following issue:
The code essentially times out when waiting for a device removal (missing or otherwise) and so ends up not being able to update the database appropriately; which in turn throws a bunch of stuff out. But the behaviour should self correct once you are able to refresh the disks / pools page but part of that database update was establishing the new state of affairs, but as you have also surmised later on, that is in flux (the pool can take hours for a drive to be removed).
Disk removal (existing or missing) kicks off an internal to btrfs balance where the data that was on that disk is re-distributed, accorting to the raid level, to the ‘to be remaining’ disks. But this is not a balance that, at least currently, can be read from a ‘btrfs balance status’ command. Hence one of the difficulties in this arrangement. I do have plans to abstract a status summary from the following command and surface that in the Web-UI:
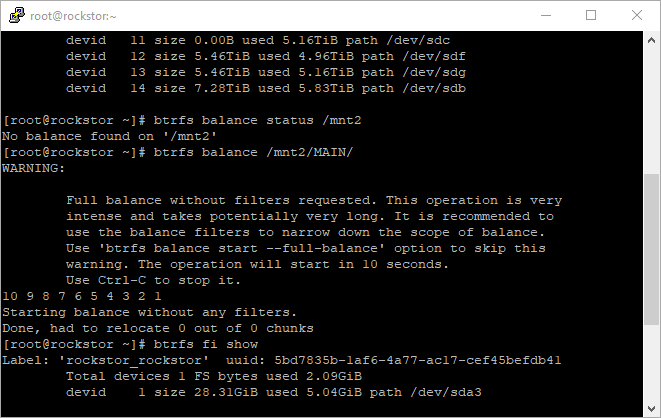
btrfs dev usage /mnt2/pool-name-here
And look for a negative Unallocated value that should change over time:
ie in the case of removing a missing device we have the following:
I.e. the Device size is update to 0.00B and it’s allocated data is, by the internal balance, redistributed bit by bit.
So we have 2 elements to this. Run our ‘btrfs device delete’ asynchronously (as we already do with balance operations): see the caveat in the recently merged code by way of the following pull request:
and secondly develop a way to surface the progress of these internal balance operations. To which there are also plans which include surfacing the usage of each device within a pool.
And from your second attempt to remove the device you see that it is actually in operation:
To that I would try the aforementioned:
btrfs dev usage /mnt2/pool-name-here
and then again a little while later to see what has changed. I suspect you will see the reduced negative Unallocated space against you ‘in progress’ resize / dev delete operation.
It’s a tricky one as one would expect this internal balance to show in a command line btrfs balance status command but it doesn’t. However if one tries:
Because there is one in progress, it’s just an internal one. Oh well, hopefully this will improve over time but in the mean time we should be able to surface the negative Allocated device ‘flag’ value and use that.
Give it time to complete that existing device delete / resize operation and then get back to us as the Web-UI should then be able to gather what it needs and correct itself.
And incidentally the sighted pool resize issue is in turn linked in the forum post you correctly sighted issue and in fact grew out of that and my own experience dealing with a disk management issue early on.
Hope that helps and yes this is a very rough edge but if you take a look at the sighed pull request #1700 above and it’s in turn sighed “Fixed” labels you will see that we are creeping up to these last rough edge bugs. But we have to prioritise carefully. For instance the pool devices table that informed you of you pool errors seemed like it should come first. Always a juggle as to what order to do things in but we are getting closer to managing the error states and providing guidance. This time out issue when removing devices is ‘in my queue’ but I have a couple of other more common place issues to address first. But we do at least know it’s cause and possible solution, however as stated the difficulty in identifying this internal balance / resize operation does complicate things as we now need an additional monitoring sub system to get around the fact that a btrfs balance status will not tell us it’s state, yet subsequent balance operations are blocked. We will see if this inconsistency is rectified going forward with our newer kernel once that is in place. And we are in the throws of re basing on a disto that has more of an interest in btrfs (mid term that one).
Thanks again for reporting your findings and do remember that the output requested for various commands can help to speed up the development of issues referenced, ie you didn’t post your prior pool usage command output that may have helped to identify if you were actually experiencing the same issue suspected as the cause or another one. We depend in part on user reports such as yours to make things better so do try and respond with the information requested as it should help to make Rockstor better for all users as we go.
I eventually did discover that the balance was happening in the background very slowly. I ended up stopping the balance operation and decided to move all of my data to external drives. I then killed the old array and created a new one using Rockstor’s default configuration. At the time, I had disk quotas and compression enabled which likely was the cause of my very slow balance. 24 hours into the balance process, Rockstor had only processed about 1TB worth of data (on a 22TB array) which is why I opted to lean the array as much as possible.
All is well after re-building the array and re-populating the data.
@juchong Thanks for the update and glad you got things sorted in the end.
Yes, it can slow things down quite considerably. Especially as snapshot / subvol count increases, and as the amount of data to track increases of course.
But there is constant work going on upstream for the quotas so hopefully things will only improve.
You could also have disabled quotas mid balance, as an option.