[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
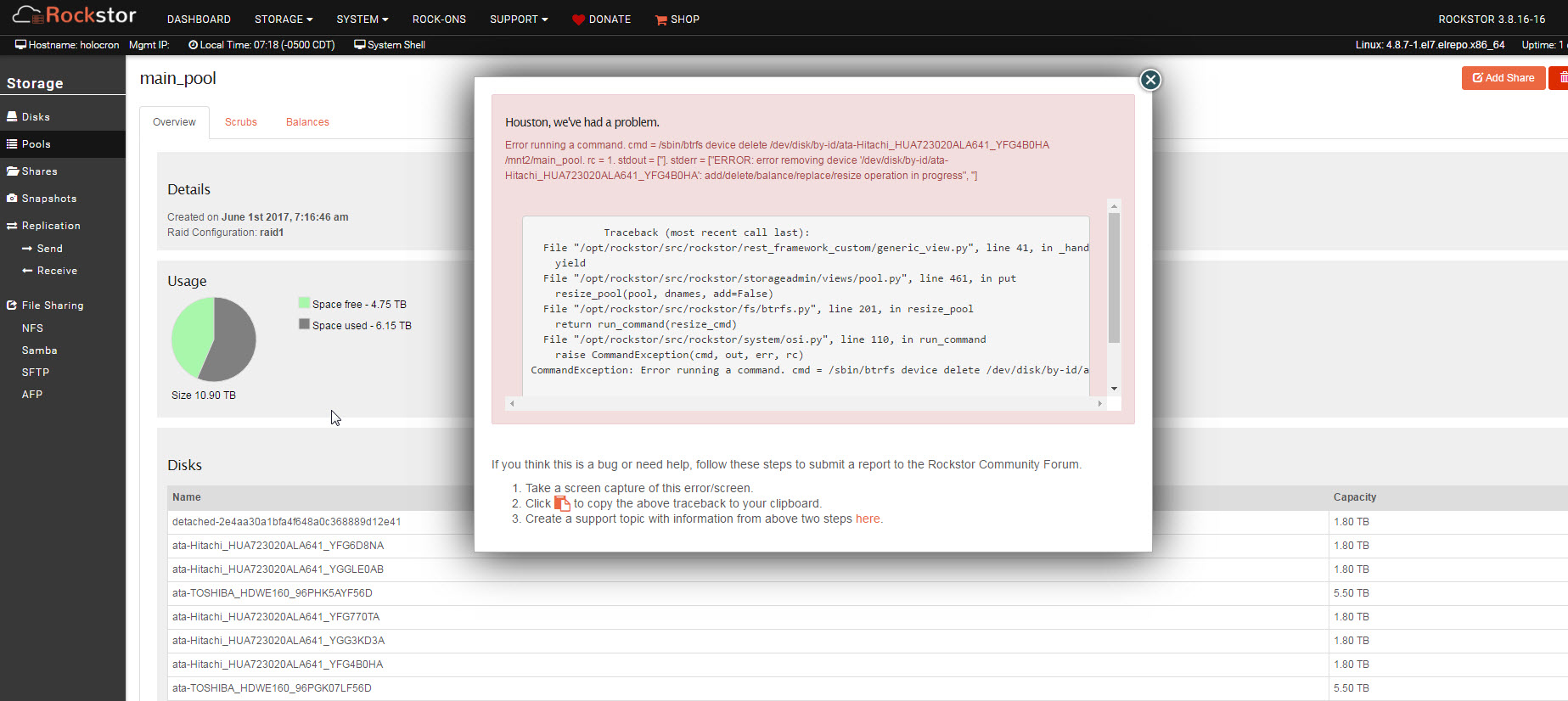
Can’t remove a device from the pool due to a rebalance in progress, but I don’t think a rebalance is actually in progress.
One of my hard drives has failed. I have a RAID 1 setup containing 6x2TB and 2x6TB drives. I’m attempting to remove 2 of the 2TB drives, the failed one and one other one to keep the RAID configuration happy. When I attempt to do that, I get the error message shown below. However, if I run “btrfs balance status /mnt2/main_pool” at bash, I see “No balance found on ‘/mnt2/main_pool’”
My pool has been mounted using the command “mount -t btrfs -o degraded /dev/sdb /mnt2/main_pool”
From the last time I performed a balance, I recall that it didn’t handle progress indication well. however, I think it just said it was at 0% progress until it was completed and then it jumped to 100%. So this doesn’t match what I recall happening in the past.
Should I unmount and remount the pool and try again? Should I reboot? I’m just worried about interrupting a rebalance and causing everything to fail.
Detailed step by step instructions to reproduce the problem
@Noggin Hello again.
This is something that need to be improved, but is known behaviour. When you remove a disk it can look like a balance is in progress and in effect it is but more accurately it’s a ‘btrfs disk delete’ and yes the ‘btrfs balance status’ indicates no balance. However I think if you execute the following command:
btrfs fi show
you will hopefully see that the size of the removed disks is 0 and the used is decreasing from one run of the command to another (if given enough time between runs).
I came across this behaviour just recently and meant to open an issue but haven’t had time to pin down exactly what’s happening yet. It seems that sometimes (not sure how often) a pool resize involving removed devices is mis-interpreted as a balance, and I think the code actually tries to kick off a balance directly after the resize and sometimes it sticks and sometimes it doesn’t. Sorry to be so vague but I haven’t had time to look at exactly what happens. However it is definitely something I’ve seen.
Let us know if you also see this decreasing used on the 0 sized devices.
The example I noted for the issue I have yet to open on this behaviour were as follows:
Label: 'time_machine_pool' uuid: 8f363c7d-2546-4655-b81b-744e06336b07
Total devices 4 FS bytes used 31.57GiB
devid 3 size 149.05GiB used 17.03GiB path /dev/sdd
devid 4 size 0.00B used 5.00GiB path /dev/sda
devid 5 size 149.05GiB used 23.03GiB path /dev/mapper/luks-d36d39ea-c0b3-4355-b0c5-bd3248e6bbfe
devid 6 size 149.05GiB used 23.00GiB path /dev/mapper/luks-d7524e90-4d9e-4772-932f-d1407b6b5fe7
and then shortly after:
Label: 'time_machine_pool' uuid: 8f363c7d-2546-4655-b81b-744e06336b07
Total devices 4 FS bytes used 32.57GiB
devid 3 size 149.05GiB used 18.03GiB path /dev/sdd
devid 4 size 0.00B used 2.00GiB path /dev/sda
devid 5 size 149.05GiB used 24.03GiB path /dev/mapper/luks-d36d39ea-c0b3-4355-b0c5-bd3248e6bbfe
devid 6 size 149.05GiB used 24.00GiB path /dev/mapper/luks-d7524e90-4d9e-4772-932f-d1407b6b5fe7
Note devid 4 used value decreasing from used=5GB to used=3GB. Shortly after that the device was successfully removed. During which there was also no balance indicated.
Yes this has been improved some since then via pr:
There after the current balance state is reflected but not live, you still have to refresh the browser; so improvements to be had but at least it’s only a browser refresh currently. But of course this only works if the command line btrfs balance status also indicates a balance as that is what is run in the background to attain balance progress info.
If you try the above command and you see in progress removed (0 sized) devices having their used space decreasing then I think it’s definitely best to leave them to it until they are finally removed from the pool. Essentially all is well but we just don’t have an indication of this removal happening. Odd really but stick with it and let us know how it goes.
I’ll make the issue as I should have done previously and update this thread accordingly.
@Noggin I meant to ask, when you kicked off this disk removal via UI did you receive a UI error to the effect of a red message:
"Houston, we’ve had a problem.
“Unknown internal errro doing a PUT to /api/pools/pool-name/remove”
?
I DID receive an error, I don’t recall what it said though. Would it still be in the logs? I looked there, but I’m having another issue with Sonarr that is packing the logs with errors so I didn’t spend much time searching for it.
From memory, here’s what happened:
I attempted to remove the failed drive and another from the pool
Error reported that the failed drive didn’t exist
I found the thread where you suggested to someone else to rescan then try again
I rescanned and tried again
This time, if I remember correctly, it hung for a relatively long time showing me a white popup box containing a table. The left side of the table had the current state of the pool while the right side showed the pool after removing the disks. There was a “confirm” or a “next” button on the bottom right that initiated the procedure.
After hanging for maybe 3 minutes, I think I got an error? I don’t remember what it said, but it was NOT the same error as I posted about at the top of this thread.
I tried again.
It didn’t hang, but an error came back quickly. The Error message was blank. I got the “Houston, we’ve had a problem” prompt, but the actual error was blank.
I tried again and got the error listed in my initial post of this thread.
The above happened last night. I tried again this morning and got the same error as the initial post of this thread. We’ve since determined that although not ideal, this is the expected result at this time.
The errors presented in steps 6 and 8 above might be swapped. In other words, the error at step 6 might have been blank and the error in step 8 might have had text in it.
@Noggin OK yes I think this is consistent with my experience. I think your experience was complicated by the additional errors. No worries, I’ve documented what I’ve found and it very much looks like you have run into the same only with additional retries etc.
Linking to the issue I’ve opened up to at least address the disk removal time out / lack of UI representation whilst in progress:
This would definitely be a nice one to get sorted so thanks for reporting it and consequently reminding me of my prior notes to open an issue for it. I’ve made a note in the above issue to update this thread once it’s sorted.
@Noggin I’ve noticed that you are removing a single device from a pool that has 7 devices attached but thinks it should have 8. Hence your stated requirement to mount degraded. Once this single disk removal is done you should have a pool that has 6 disks attached but thinks it should have 7. Check once the current operation is over that it still thinks it has a missing disk, via “btrfs fi show” (which is my suspicion) in which case you will then need a:
btrfs device delete missing /mnt2/main_pool
In order to return things to a fully healthy state. Please see the outstanding issue for this:
as there is no UI way to accomplish this.
Tread carefully here as you may only have this one mount to get this pool into a healthy state.
The pool resize appears to have completed successfully. I deleted the detached drive from the UI before seeing your post here, but I then went to the CLI and issued the command as you specified. My SSH session was disconnected, but when I reconnected it looks like the delete is occurring. It appears to be working, just slowly.
I’m assuming that it might take a few hours to complete.
Is it expected to take this long to delete a detached drive? I’ve already removed the detached device as well as another 2TB drive. That took about 14 hours. Deletion of the detached drive has been going for 16 hours now. It seems like it should have already been pretty much removed at this point and that deleting it shouldn’t be much more than a little housekeeping.
If you are referring to a device named detached- within the UI and your removal was via the bin icon then this does nothing on the btrfs front but simply removed it from Rockstor’s db. Hence my suggestion and double check to do the delete missing command to bring things up to scratch again.
It could well take longer than removing an existing device as you did earlier. Is there evidence of progress, ie as before when you were removing an existing device, can you see the usage changing on the existing devices? Essentially it has to work backwards to find what was on the missing device and re-create it from the other copy on the remaining devices. Pretty sure this will make it slower than removing an existing device.
It’s a little more than that really as it has to return the appropriate redundancy to all chunks / blocks that were previously stored on the now missing device.
Interesting. I figured that since I removed it via the UI by resizing the pool that it had already done that.
btrfs fi show
[code]Every 10.0s: btrfs fi show Fri Jun 2 11:43:23 2017
Label: ‘rockstor_rockstor’ uuid: 5c2b67f2-9f3a-4e52-b979-32e9dc159423
Total devices 1 FS bytes used 1.67GiB
devid 1 size 51.57GiB used 4.04GiB path /dev/sda3
Label: ‘main_pool’ uuid: 07f188d4-44d6-49fd-86ac-0380734fe1d2
Total devices 7 FS bytes used 6.15TiB
devid 2 size 1.82TiB used 849.00GiB path /dev/sdb
devid 4 size 1.82TiB used 848.00GiB path /dev/sdd
devid 5 size 1.82TiB used 848.00GiB path /dev/sde
devid 6 size 1.82TiB used 771.03GiB path /dev/sdg
devid 7 size 5.46TiB used 4.47TiB path /dev/sdh
devid 8 size 5.46TiB used 4.47TiB path /dev/sdf
*** Some devices missing[/code]
The sizes aren’t changing, at least not significantly.
Yesterday, at around 5 PM I issued the command “btrfs device delete missing /mnt2/main_pool”, this was after resizing the pool from the UI to remove the detached device and another 2TB drive.
Just now, I issues the “btrfs device delete missing /mnt2/main_pool” command again and it started doing something based on the fact that it didn’t immediately return to the prompt. I opened a new SSH window and did the same command, and it gave me an error stating that a deletion was in progress. Yesterday, when I did the delete missing command, and did it again shortly thereafter, it gave me the same error message that a deletion was in progress.
Yes that was for the devid 3 device (at the time /dev/sdc) which has now gone so we are at:
and the delete missing is our attempt to address just the missing device which would appear to be devid 1 (of the main_pool) which has never featured in the btrfs fi show ouput here (presumably the fully dead drive).
Rockstor’s UI can’t do a removal of a device that is detached (or missing in btrfs fi show parlance). Hence the suggestion to use the delete missing. This I think is where we differ in what’s happened. Presumably you tried to re-size by removing a device called detached, and presumably this accounts for one of the errors you received. That operation essentially did nothing. Only the resize involving the devid 3 device was effective and kicked off the first and only resize to date. I’m also not quite sure what you meant by the
But that was already underway when this thread was started. Btrfs raid 1 can work with an odd number of drives!
Sizes shouldn’t change but hopefully the used column is as the copies that were on the missing device are re-created on the remaining attached devices. The size changed on the delete named device as it was there for it’s size to be reduced to 0 but we can’t see the size of a missing device from the command line.
Oh well it appears that we are getting there anyway (at least on the devid 3 removal). It may well be that an un-mount, rescan, and remount via reboot is going to be necessary; but we must make sure we do all that we can first to get thing in order. But 2 attempts to remove a missing device should be enough.
Given the difficulties and strangeness re delete missing here you might want to make sure you have this data elsewhere prior to the reboot though, just in case. Especially given you have a successful mount as is.
Once I get everything set up to my satisfaction, I’m going to buy a new license for Rockstore instead of restoring my old one as a way to say, “Thank you!”
I bought 2 8TB reds to replace all of my 2TB drives. I’ll copy all of my data over to it before I reboot. Most of it is backed up to a 5TB already anyway. Its also on ACD through rclone, but as you most likely, know that is pretty much gone.