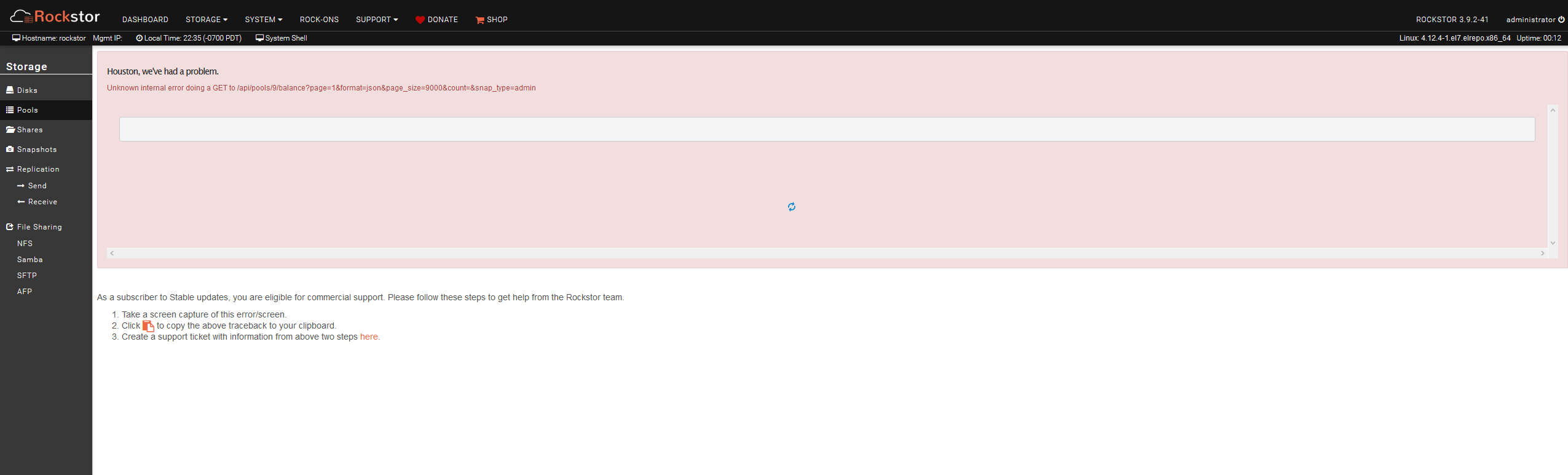
Update: The web gui refuses to show the “Disks” or “Pools” pages and just threw an unknown error. Not sure whether something is going on in the background, but this post from 2017 seems to indicate that this is normal. I would’ve thought that this issue would have been taken care of sooner rather than later, but maybe that’s not the case?