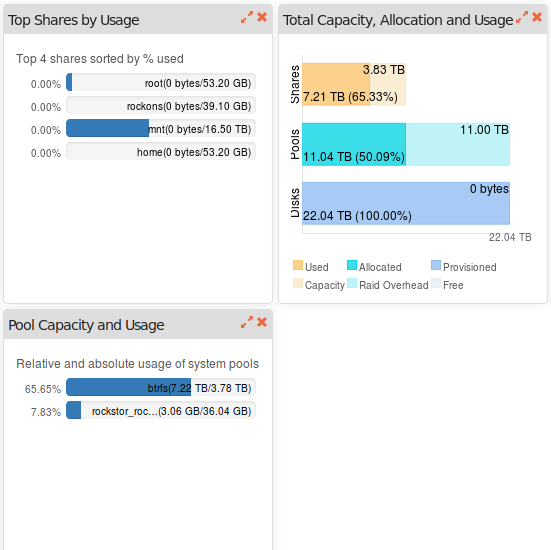
Today i faced a new problem after swaping 4x3TB to 4x6TB Raid5. The Raid size is as expected ~16.5TB. But the poolsize is still 7.5TB which is a quota thing i guess.
Never messed with quota on btrfs up to now since its almost considered broken by the kernel devs and bugs only get fixed slowly. but now seems to be the time start learning the concept btrfs uses here.
Is this a missing feature or a bug?
Sash
p.s. mnt is a samba share on the Raid5 pool called btrfs. while the poolsize of “btrfs” gets displayed with ~11TB (which is wrong), the share /mnt2/mnt shows ~16.5TB (which is correct).
The pool size is the size of the subvolume, it is not related to quotas.
I was under the impression resizing was implemented the UI, but alas it seems I was wrong.
I believe the operation you’re looking for is:
btrfs fi resize max /mnt2/mnt
Followed by a balance, preferably performed from the UI.
so IMHO the poolsize gets wrongly displayed in the GUI?
Sash
p.s. additionally now the “mnt” subvol on “btrfs” doesnt get mounted anymore. i guess tis is something related to the fact that poolsize and sharesize differ
Hi,
problem with unmounted devices/shares and display of 0 bytes should be corrected since 3.9.2-5 (actually we have 3.9.2-10). In my case I had to do a yum update rockstor, because my installation was still an older one. After rebooting everything works fine.
It’s likely that the current pool size is stored in the Rockstor DB somewhere, however I cannot advise where without further investigation.
What does the CLI say?
btrfs fi df /mnt2/<pool_name>
Regarding the second issue you’re seeing, is the pool mounted via CLI, is /mnt2/btrfs a share, because if it’s supposed to be the pool, it’s on the wrong mountpoint, as according to your UI, it should be /mnt2/mnt
Otherwise, we should probably check that the mountpoint exists, and whether the share is mounted:
[ -d /mnt2/mnt ] && echo "Directory exists" || "Directory does not exist"
mount | grep /mnt2/mnt
If the first fails, try re-creating the directory as root, then reboot.
mkdir /mnt2/mnt
If the second fails, try mounting manually:
mount /dev/sdd -o rw,relatime,space_cache,subvolid=5,subvol=/ /mnt2/mnt
Report results, we’ll see if we can work through this.
RE: the mount options - I was only specifying the default that RS uses.
I’d suggest a reboot, and then inspecting /opt/rockstor/var/log/rockstor.log (from memory) for any errors if the pool still fails to mount.
[root@nas ~]# tail /opt/rockstor/var/log/rockstor.log -n1111|grep mnt
[15/Jan/2018 16:46:10] ERROR [storageadmin.views.command:110] Exception while mounting a share(mnt) during bootstrap: Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_ZAD2QXM5-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 does not exist’, ‘’]
[15/Jan/2018 16:46:10] ERROR [storageadmin.views.command:111] Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 does not exist’, ‘’]
mount_share(share, mnt_pt)
return run_command(mnt_cmd)
CommandException: Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxx-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 does not exist’, ‘’]
[17/Jan/2018 13:31:21] ERROR [storageadmin.views.command:110] Exception while mounting a share(mnt) during bootstrap: Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 does not exist’, ‘’]
[17/Jan/2018 13:31:21] ERROR [storageadmin.views.command:111] Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxxx-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxxx-part1 does not exist’, ‘’]
mount_share(share, mnt_pt)
return run_command(mnt_cmd)
CommandException: Error running a command. cmd = /bin/mount -t btrfs -o subvol=mnt /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxx-part1 /mnt2/mnt. rc = 32. stdout = [‘’]. stderr = [‘mount: special device /dev/disk/by-id/ata-ST6000VN0033-2EE110_xxxxx-part1 does not exist’, ‘’]
The mount process searches for a partition based setup but as mentioned here i had some trouble with it on rockstor and Philip mentioned to switch to a volume based setup…which i did. I deleted and readded disk by disk to the pool and now i got an whole disk layout. How to get now Rockstor knowing the now layout ?
It may be that you ‘switched’ (ie via command line) to whole disk without changing your re-direct role entry for the given disk. That’s all I can think of currently as to why Rockstor would ‘entertain’ a partition.
Can we have a pic of the disk page as your last picture of this in the following post indicated a redirection role was in play back then?
I take it you have now sorted the disk that had both a whole disk and partition btrfs signature due to incomplete wipe between first a whole disk btrfs format followed by a partitioned variant? Ie I am assuming all disk members of that pool are now showing consistent blank UUID entries from the lsblk command given in that thread. And that all disk members are also whole disk btrfs?
This was my assumption following:
As you log has been altered on the serial numbers can we assume there is only one by-id name with a -part1 ending as I see 2 entries that could be covered by:
ata-ST6000VN0033-2EE110_xxxx-part1
excluding the system disk elements of course.
Also:
Note that we still don’t support space_cache=v2 as a mount option.
Hope that helps to sort things out as it’s all that springs to mind currently. Ie if a disk is still showing a redirect role in play that could account for it.
[root@nas ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdd 8:48 0 5,5T 0 disk /mnt2/btrfs
sdb 8:16 0 5,5T 0 disk
sde 8:64 1 59,7G 0 disk
├─sde2 8:66 1 7,9G 0 part [SWAP]
├─sde3 8:67 1 39,1G 0 part /mnt2/rockstor_rockstor
└─sde1 8:65 1 500M 0 part /boot
sdc 8:32 0 5,5T 0 disk
sda 8:0 0 5,5T 0 disk
[root@nas ~]# blkid
/dev/sda: LABEL="btrfs" UUID="c8c7ac34-dbbd-4eb5-8fa2-cfc2e5e530b2" UUID_SUB="59563d66-eb99-4a93-bcbb-3dc7c12c90ab" TYPE="btrfs"
/dev/sdd: LABEL="btrfs" UUID="c8c7ac34-dbbd-4eb5-8fa2-cfc2e5e530b2" UUID_SUB="6f325c56-fda1-429e-9c1e-a0a1098ac4ff" TYPE="btrfs"
/dev/sdb: LABEL="btrfs" UUID="c8c7ac34-dbbd-4eb5-8fa2-cfc2e5e530b2" UUID_SUB="097c4ed7-df6f-481d-8d1f-9fbbd0f7ffea" TYPE="btrfs"
/dev/sdc: LABEL="btrfs" UUID="c8c7ac34-dbbd-4eb5-8fa2-cfc2e5e530b2" UUID_SUB="c9d89869-c281-41e3-a903-c21dbcb89362" TYPE="btrfs"
/dev/sde1: UUID="b33c499b-dc29-4de5-94cb-9e2793079ef4" TYPE="ext4"
/dev/sde2: UUID="0b187eee-8c67-49f9-ab87-2f9230f4e77c" TYPE="swap"
/dev/sde3: LABEL="rockstor_rockstor" UUID="44835519-60f7-44bc-9323-64ec5a1febc8" UUID_SUB="8da543e1-afc0-4b3e-a9c3-d356d65e25ab" TYPE="btrfs"
After removing the disks from the pool i installed a new gpt table on every disk.
As you log has been altered on the serial numbers can we assume there is only one by-id name with a -part1 ending as I see 2 entries that could be covered by:
ata-ST6000VN0033-2EE110_xxxx-part1
Jep, its always the same part1 thats been missing. i anyway have only one ata-ST6000VN0033-2EE110. the other disks are “22”,which are sightly different disks.
As whole disk does not have partitions a partition table is not required. They are literally managed from the firmware (EDIT correction) ‘base block device’ up by btrfs. Hence the preference. I.e. no partition table of any kind be it mac’s variant of gpt (newer macs), or gpt, or msdos or whatever. Whole disk is no partitions and so no partition table required. The UI prompt to wipe the disk, which wipes all partitions and the table itself (when going for the whole disk default). Hence we are back to drives as if they were new. That is why when a partition table is found by Rockstor it prompts to wipe the whole disk.
You are rather complicating things for yourself and those attempting to support you in Rockstor by using low level tools out of context.
From the disk page it now looks like all of you disks has some tag icon next to it. When we were last here (in the referenced thread) with the btrfs in partition element there was only one drive setup this way. However besides the potentially errant redirect role selections (my current suspicion) the lsblk output looks to be OK and you have confirmed that btrfs understands the drives to be whole disk from your last ‘btrfs fi show’ command earlier in this thread.
If you click on those tags what does the drop down indicate?
You can see how those icons are used from our Disks page and the tag is highlighted in the Disk Role Configuration which starts "Disk roles are not required and are not advised for general purpose disk use. ". I suspect in your ‘advanced’ re-arrangements you have inadvertently added a redirect role where non is required (for whole disk use anyway): as you appear to have one for every disk in the pool now. The docs don’t however show the more recent addition of the map icon which indicates that a drive is mapped to a pool.
Also note, as @Haioken mentioned that Rockstor expects and enforces a particular mount structure. It just won’t work if mount points are not where it expects. And it does all of it’s own mounting of all pools (btrfs vols) and associated subvols (shares and snapshots). This takes place on boot or during an import. If that fails then there after it’s a bit of an uphill struggle. But this is improving as we move forward. Hence my concern with your use of space_cache=v2 as it will also enforce it’s record of mount options and it doesn’t know about that one. You might get away with it though.
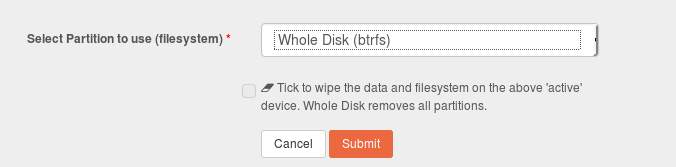
Am I right in assuming this means there was only that one entry in the drop down? Also did it have anything in brackets after the “Whole Disk” wording and was there the word “active” following the “Whole Disk” wording.
Just trying to pin down what’s going wrong here as a regular redirection role looks like so:
part2 (btrfs) - active
or in deed:
part1 (vfat) - active
When no redirect role is in play it would show as follows:
Whole Disk (btrfs) - active
The contents of the brackets show the discovered fs type and the “- active” show the currently understood ‘in-play’ setting with Whole Disk as the default.
Hopefully with this info we can step further into this one.
I’ve managed to reproduce what I believe to be the same state here, ie same disk icons, same redirect role state. To do so required changing a prior managed pool with a btrfs in partition member, via the command line, into a whole disk pool. In short the upshot of this is that the redirect role is maintained (currently intended behaviour but in an unintended and unrecognised system state): ie I couldn’t get to this state from within the UI. Anyway we are in a catch 22 there as there are safeguards against changing the redirect role, even if orphaned apparently. This is all well and good but not in your case.
Long and short is I think I now understand this situation Rockstor wise and have exact notes on how to reproduce it, but given that it only occurs after extensive cli manipulation of the pool, and that the changes to adapt to this scenario are all on fairly sensitive and otherwise well behaved code I think a adaptation is not going to arrive soon. But as and when we introduce whole disk roles, which is what I think your disk icon tool-tips will indicate (mouse over the tab icon on the disk page) "Whole Disk Role found, click to inspect / edit.” we can reference this behaviour then. But currently there are no whole disk roles, that message is the UI’s logic of “I have a redirect role but no partitions, must be a whole disk role.”
No export required with btrfs. As long as it is cleanly unmounted it just needs to be mounted again.
However your sentiment of a fresh import for the pool I agree with. That way all disk db entries are re-build from what they find, and to defaults. But only if the current persistent disk info is removed which can’t be done safely with the disks attached (well not easily anyway). So bar db edits to remove the now orphaned but intentionally persistent redirect roles, a more practical option is as per my previous instructions in a previous thread with yourself:
Which brings us back to your already observed and reported import failure for pools with a prior use of “space_cache=v2”:
Let us know how you get on. It’s been a challenging but useful one this so thanks for working through it. I was originally against the idea of supporting any kind of partitioned device but it was requested multiple times and in the long run I think it will be good as then we can have import / export to non native devices, attached locally, that are almost always partitioned. So pros (flexibility) and cons (complexity).
Did you not like my previous response on this question then:
I’m pretty sure it’s the db and it’s hold on redirect roles that’s out of kilter. Cleaner to do as I suggested above post I think.
Might need to re-scan quotas once the import is done to get rid of a load of zero space use size and resize your shares but then that is currently only cosmetic anyway. See my previous post of the link to the prior suggested method.
I did as you said. Removed the disks, deleted the disks from the pool, inserted the disks and imported them. Now it seems to work as expected (disk,pools, shares in correct size, etc).
@g6094199 That’s great news, glad you finally got sorted.
I’ve been thinking about adding back in some ability to do this without detaching the disks. We use to have it where if one deleted a pool it just removed from the db but later another convenience option of removing all subvol superseded it, but I think this need revisiting myself. I’ll have a think once my current backlog is done.