Well, I have experienced 4 sort of major update problems in the last couple months.
Every time after update (first two times) snapshots stopped working altogether. The only cure was to erase the destination and re-setup the whole thing.
Third time I disabled snapshots before doing the update then rebooted and re-enabled snapshots no problems.
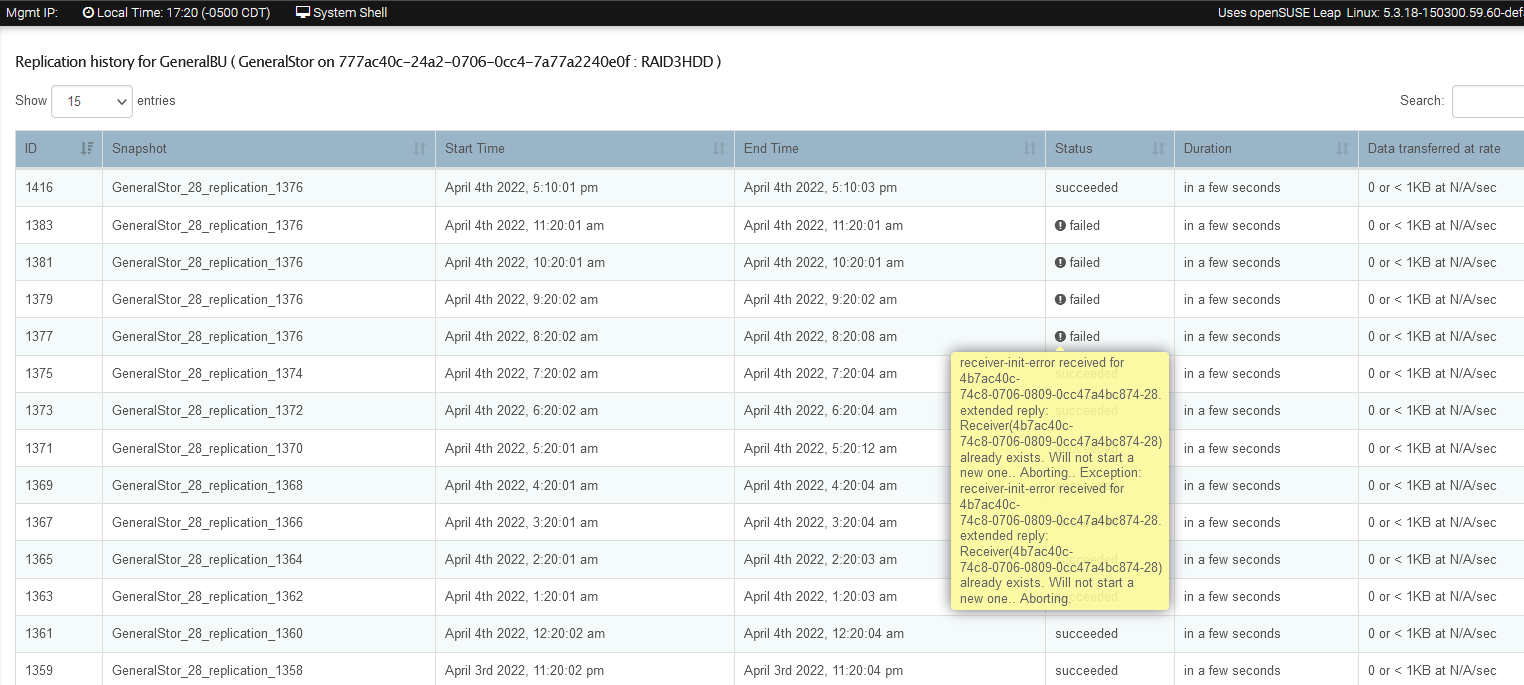
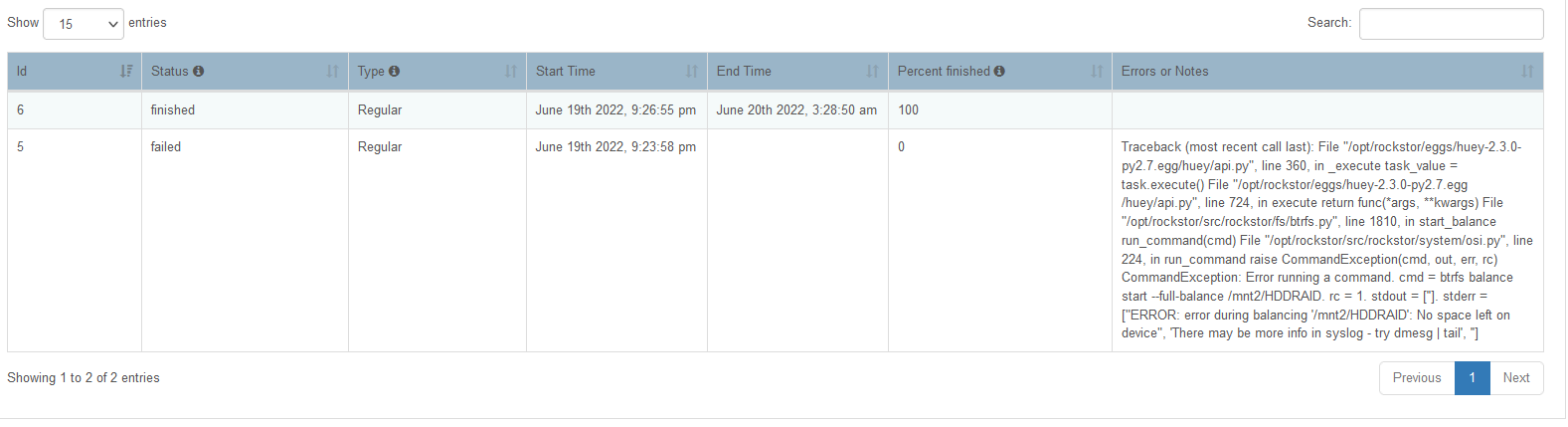
Yesterday I did the same thing, disabled snapshots, let the updates run, rebooted both systems this morning, restarted snapshots and they all failed on one raid10 setup/share.
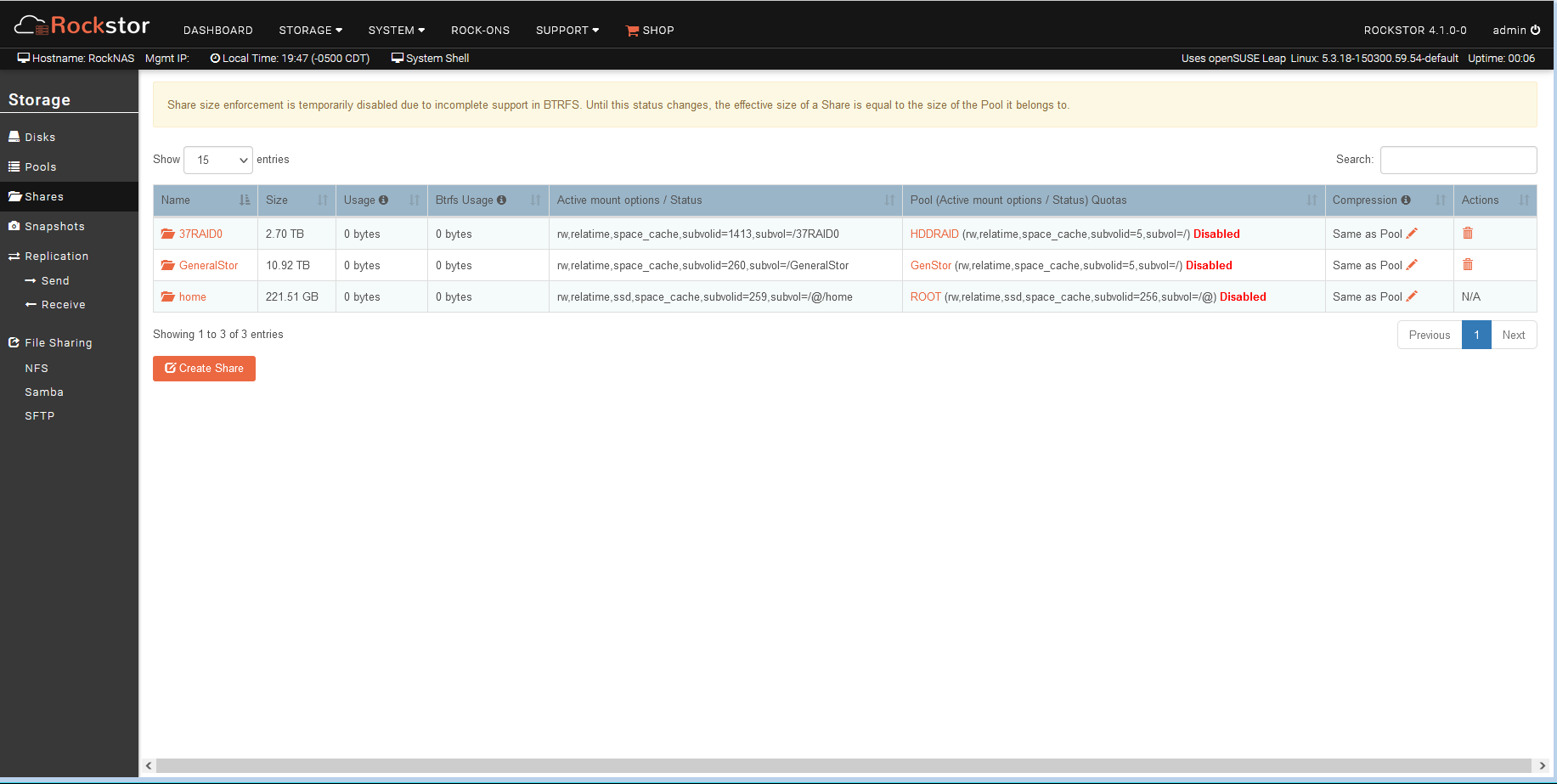
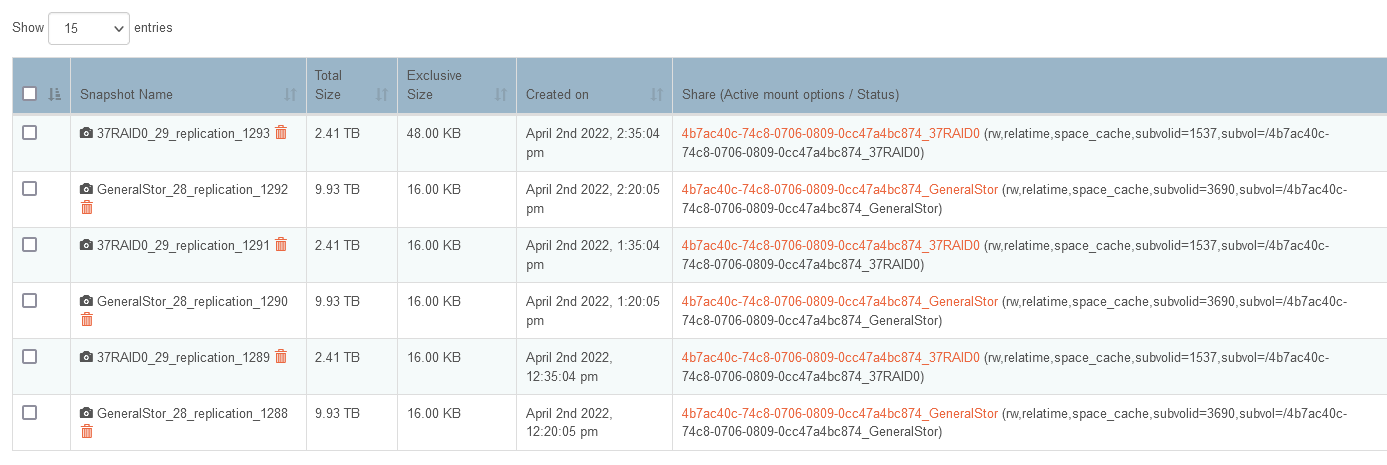
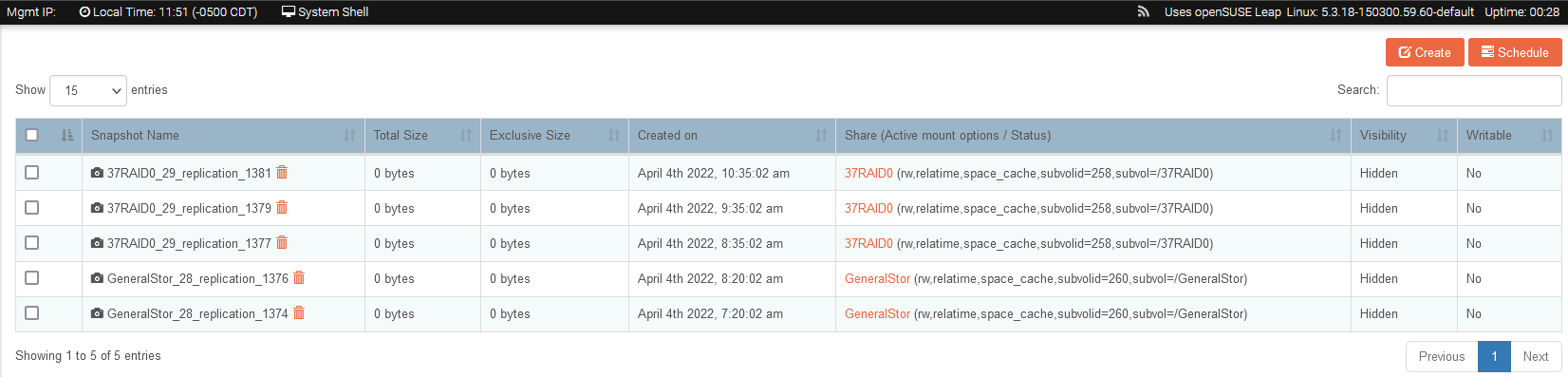
The 37raid0 share would NOT snapshot so I did the delete thing I have done before and still no joy.
So I deleted the share and pool, rebooted, re-imported the pool/shares (which I have done many times before without problem) and it seemed to work…
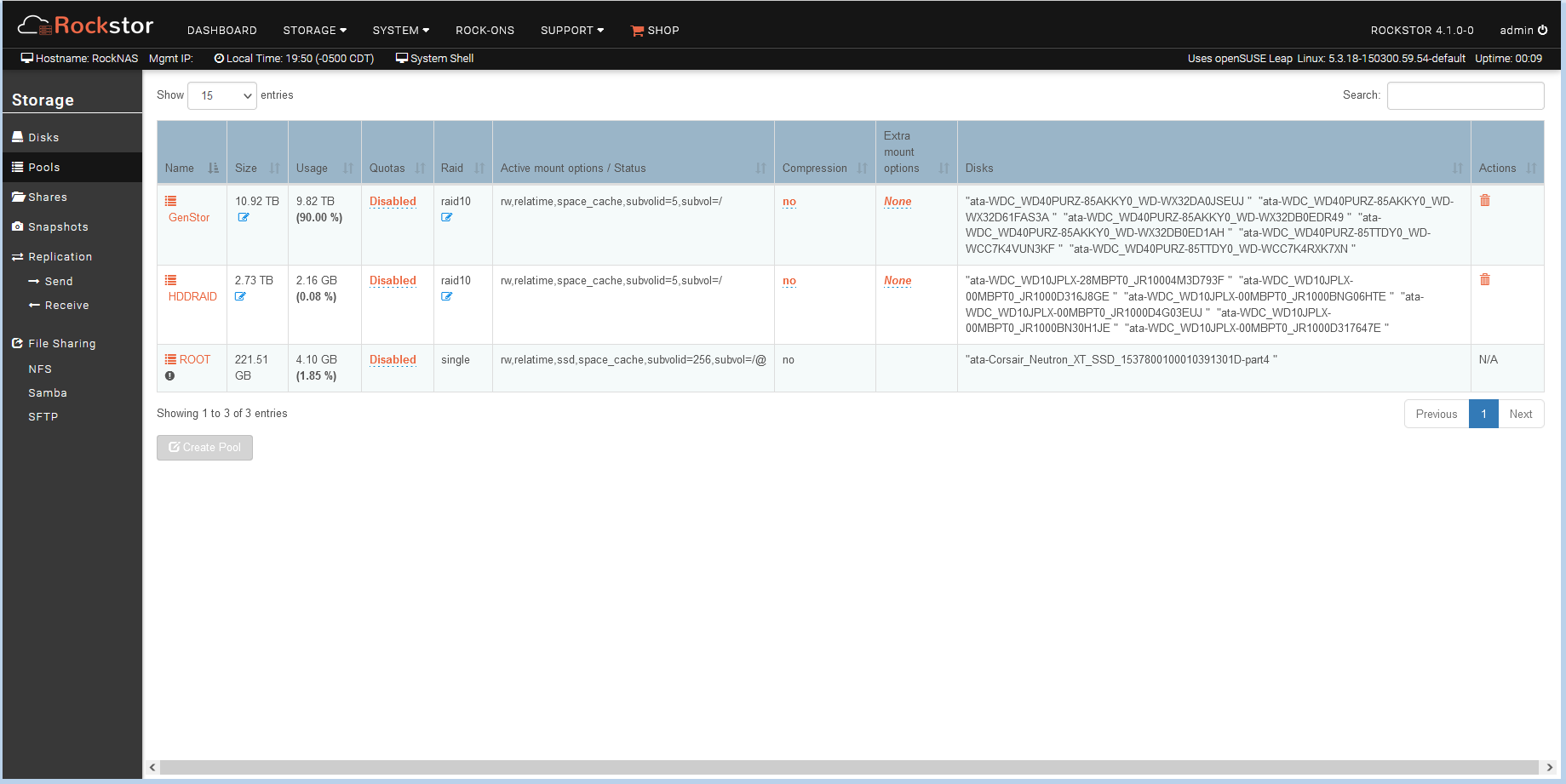
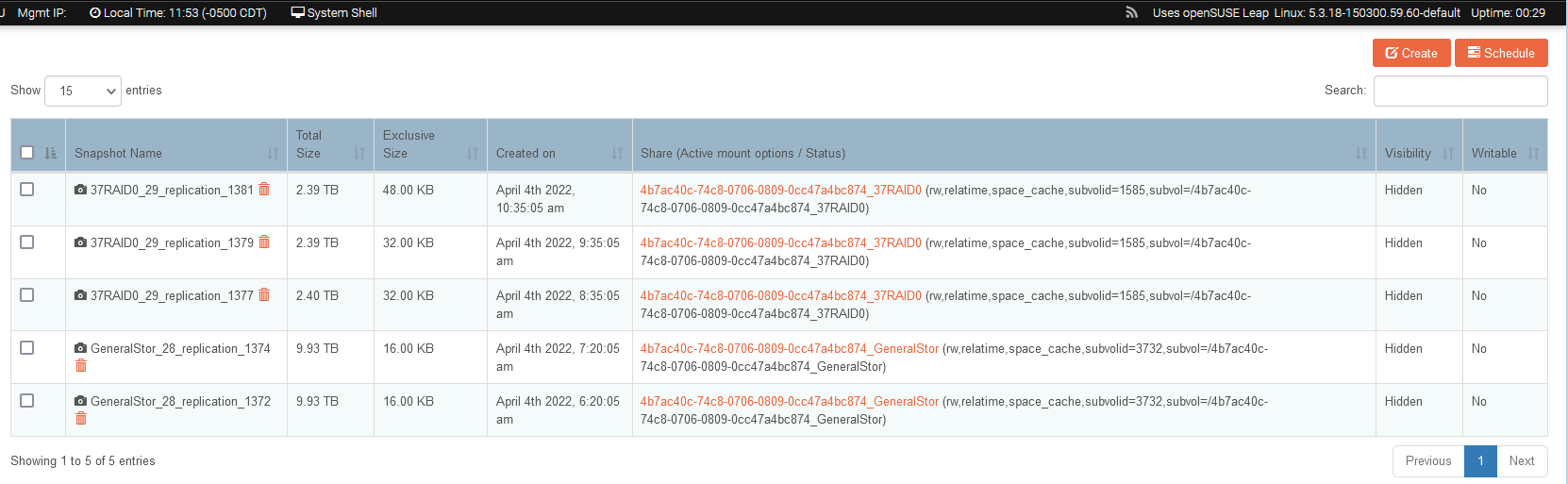
Then I discovered there was NO DATA on the imported Raid10!!! I’ve tried many times to import the pool with no positive results…
Also notice used and available sizes are all zero??
I’ve recreated the raid AGAIN, and now I need to know how to get either the snapshot or the data from the backup NAS copied over. Couldn’t find anything about Restoring in the Wiki… any help appreciated.
Thanks, I’ll check things out. I have already recovered what I lost from another backup on the primary NAS setup, so no worries there. Just that I want to see how to do it from the backup NAS setup if I can.
I still can’t figure out why after every major update, the snapshot function stops working.
When you delete a pool it wipes all the subvols, it’s then empty. There is a Web-UI warning popup about this. In really early Rockstor and in a doc somewhere I think, we say otherwise. But the Web-UI warns that you are about to delete all data. And that looks to be what’s happened at this stage at least.
Could you clarify what you mean here if you would. Are you talking about scheduled snapshots or the auto-snapshots associated with the replication service.
Glad you’ve got things back up and running again and we definitely have some rough edges in these parts.
Well, I didn’t know there was an “auto snapshot” thing… hmmmm… In all of this, I am referring to the Replication Snapshots from my main NAS to the backup NAS appliance. When I am working, I set it for once per hour, otherwise once per day.
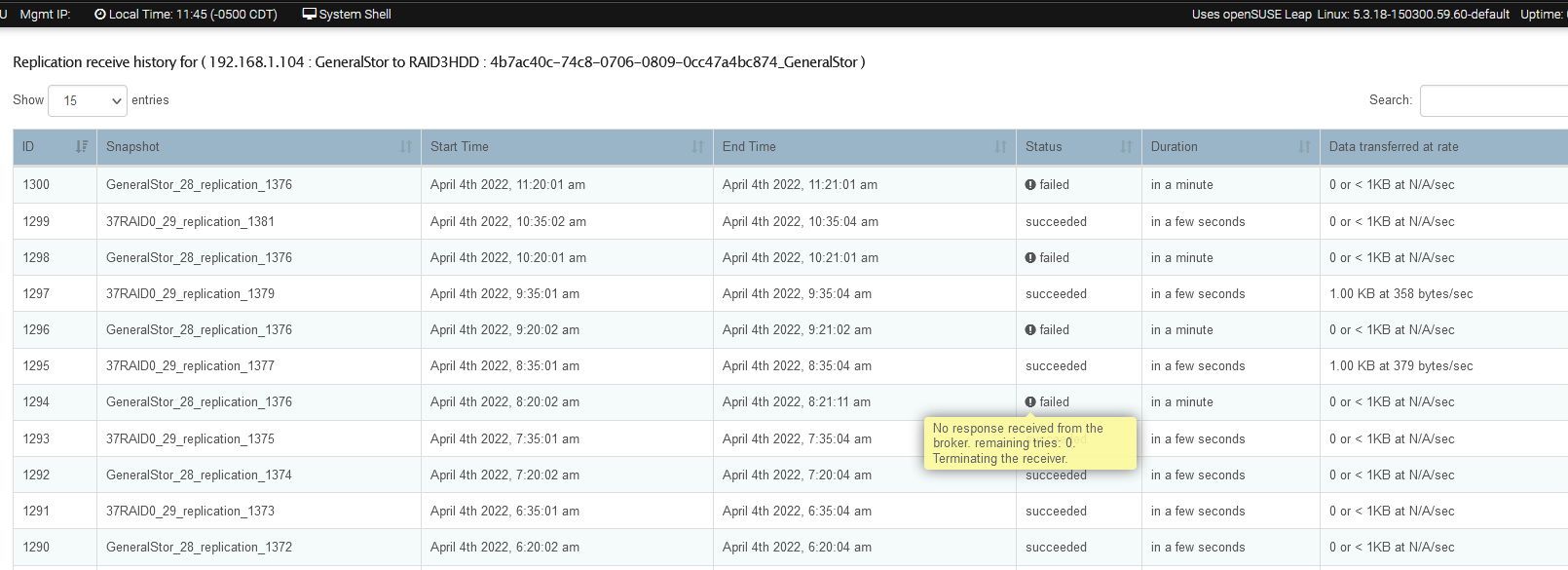
IIRC since February we have had 4 major updates to 4.1… mostly library updates so far as I could tell. After every update, the hourly snapshot would fail, mostly with a failed to receive something or other from the main NAS. I am thinking there is some timing thing with the 10Gbps LAN speed. In all instances except the last, I was able to delete the failed snapshot from both appliances and continue on.
Hope that helps, If if happens again, I won’t delete anything and just ask for help from the getgo,
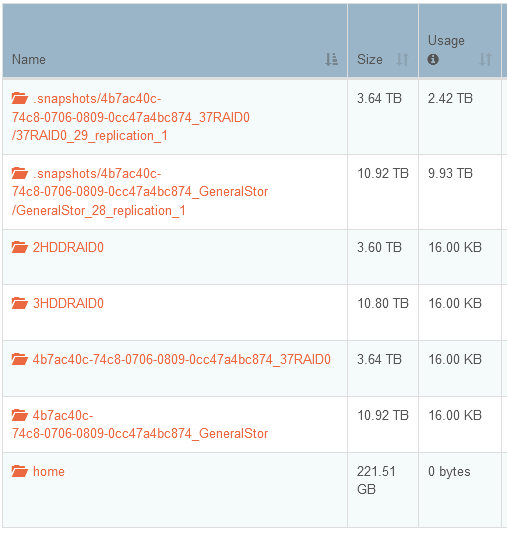
Also remember that it takes 5 replication tasks for it to settle into it’s end state. Those weirdly named .snapshots* shares are an anomaly at the beginning of this settling period.
Normally if a replication task is interrupted there is never a need to delete pools. Only the associated snapshots at replication tasks. And often, as you indicated before often only the last sending snapshot associated with the replication task. The Pool is much higher up. And if you change this at either end it’s then a requirement to change everything else from there down. Each pool has a unique uuid and the replication tast (btrfs send receive) uses this to know who it is.
Hope the hardware tests go OK. I will try to look further at improving our send/receive wrapper robustness but also know btrfs itself is as yet unable to resume an interrupted send/receive. Hence no pick-up if a send is interrupted. There are plans however, and fairly soon I think, for upstream (btrfs devs in this case) to move the send/receive format on some and adopt many of the requested capabilities. The ability to resume an interrupted send has been a popular request. But we still have our own fragility so keep an eye on that network etc.
Your report of updates breaking things is interesting on this front. We’ve not actualy released any ourselves in this time; so they have all been from upstream. It would be usefull to know the type of update. A kernel update during an active send/receive may well trigger an interruption and cause the requirement to re-enable that step in our wrapper by removing the last sender snapshot.
Incidentally does once per hour give sufficient time for the snapshot to complete? We can handle them overlapping (we just don’t run another if one is already running) but just in case.
Also what transfer rates are you getting. That’s another improvement coming down the line I believe.
Give the replication time to settle before judging the sizes. Especially with those strange early snapshots with odd long names. I did try to hide them when I was last coding in this area but it caused too much complexity so I left them as at least they can be diagnostic.
As an aside, I haven’t proven updates themselves cause problems exactly… next time something happens, I won’t touch a thing and take it from there.
Currently, transfer speeds run between 140MBs to 190MBs over the 10Gbps network. The initial snapshot to a blank BU NAS appliance took almost 2 days (mucho TBytes of data). Since then it normally takes a few seconds per update. So far, once per hour on both major shares is running fine, although I normally run the biggest 12TB share once per day.
So far so good. I also had a problem after a power outage that may have corrupted something. Both NAS setups actually take very little power; 70 & 100 watts idle after startup. Spinning up the drives and such adds about 50 & 80 watts respectively for maybe 20-30 seconds max.
I’ll keep you updated. I’ve been hip deep in building my new water cooled 5950X workstation with nothing but problems…
Did it again. I stopped the replication service and guess what? Today there are more updates to install!
Coincidence? I wonder…
In any case, this time it errored on my 12TB Raid10 share, not the 3TB Raid10 share.
This is the all the info I have. Except for stopping the main NAS replication service, I’ve done nothing. Both NAS and NAS BU are also waiting for me to click updates.
@Tex1954 Hello again.
I’m a little unclear at what’s going on here actually.
For now, if you have disabled all send replication tasks then you can go ahead and apply all system updates. That get that bit done at least.
Could you then add to your plethora of screen grabs (Thanks) the send replication details. The receiver service pretty much just sit there awaiting the sender to tell them what to do. So they can be left on, however one of you error messages suggest that the receiver couldn’t be found by the sender. I wonder if this is just down to wondering IP addresses. Have you set both systems to be assigned static IP on your network? Some routers will change out IP addresses every 24 hours or so. Just a thought.
Hope that helps and let us know when both machines are updated. And then with the details of the send replication tasks I or another helper here may well be able to pin down the exact failure that’s holding things up.
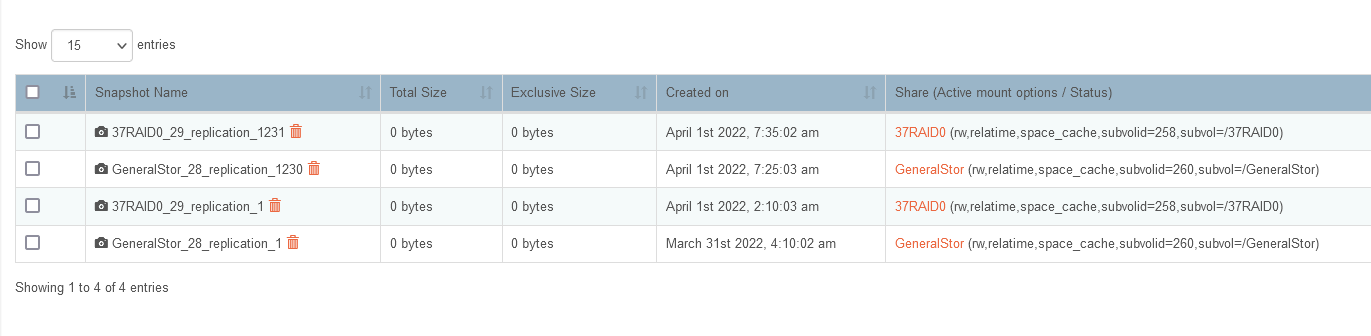
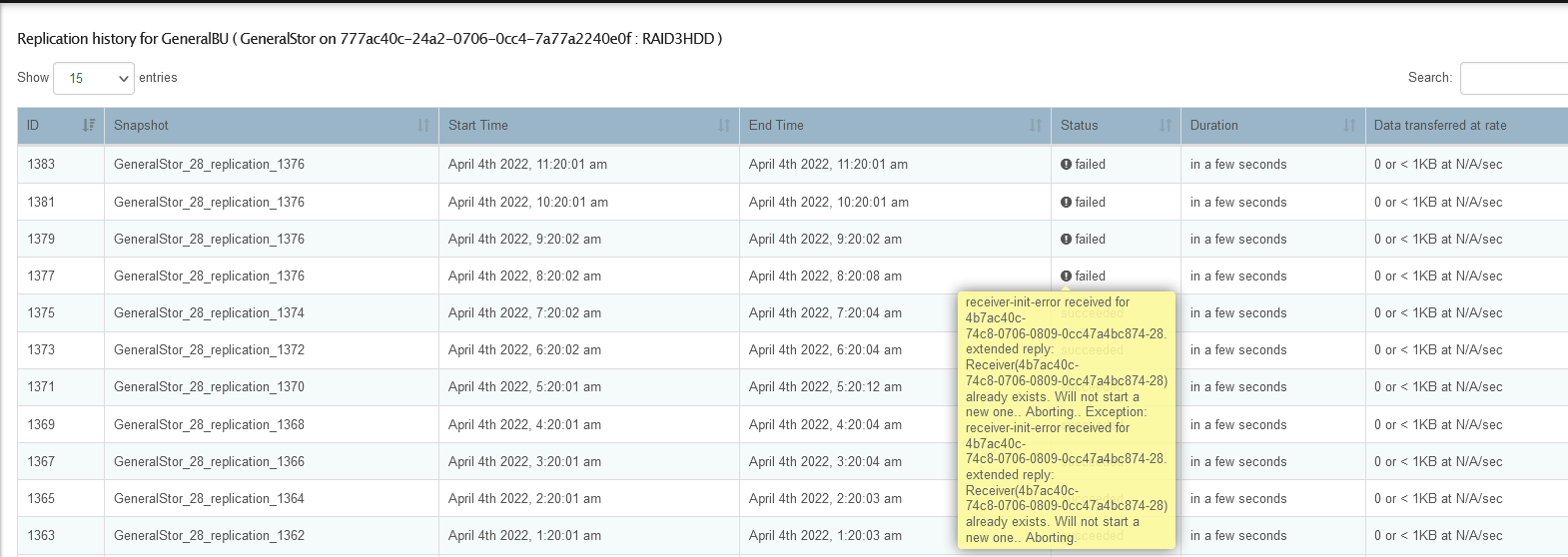
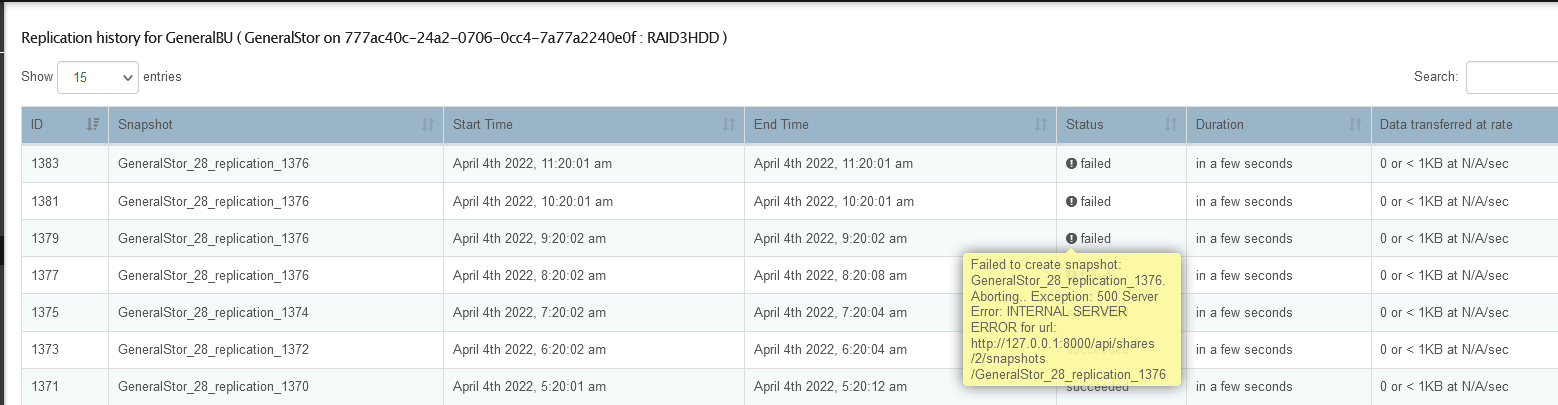
By far the most common is that a snapshot was taken on the sender and it was then unable to replicate that snapshot (btrfs send) over the network, it started and couldn’t finish for some reason. When next the send replication starts it finds itself stuck. Deleting the last snapshot for the failed send task usually does it as it then creates one afresh and carries on. See the following issue we have open for this to see if this rings true to what you are seeing. I don’t yet see exactly what your systems hold up is yet.
It’s actually a long standing replication issue since I last mended replication in stable quite some time ago. In our CentOS testing channel it was broken for quite some time.
Hope that helps and I should hopefully get some more time soon to have a closer look at your situation.
Thanks again for the detailed reports. And let us know what your IP assignment is for both these machines.
Also, the router has permanently assigned the addresses of both systems (RockNAS 192.168.1.104 & RockNASBU 192.168.1.108) according to their MAC address and these never change.
I’ve given what I could, it is running fine again after I deleted the last failed SEND snapshot.
Yup, it worked again, same as before.
Hmm, maybe something else affecting it? Maybe a global variable containing BU IP address clobbered by the software update function?
If you and I can figure something out, I am more than willing to do anything you ask including screen sharing so you can talk to my systems yourself.
30 days error free. First time ever… more testing going on. Also, CAT scan shows I need major surgery in near future so maybe not online for a while during that.
Discovered a glitch/bug with my router where a power glitch would cause it to reset but never enable the WiFi afterwards. No amount of software resets/configures would restart the WiFi function. Finally a several minute power down and restart corrected the problem. This also caused a replication glitch that was easily and quickly corrected.
Surgery scheduled for July 13 provided the rest of my heart scans/tests pass and I don’t catch Covid in the meantime. If all goes well, be home 8-12 days later depending.
NAS and NAS-Backup still doing well! Zero hardware or cooling problems and both setups reasonably low power as well.
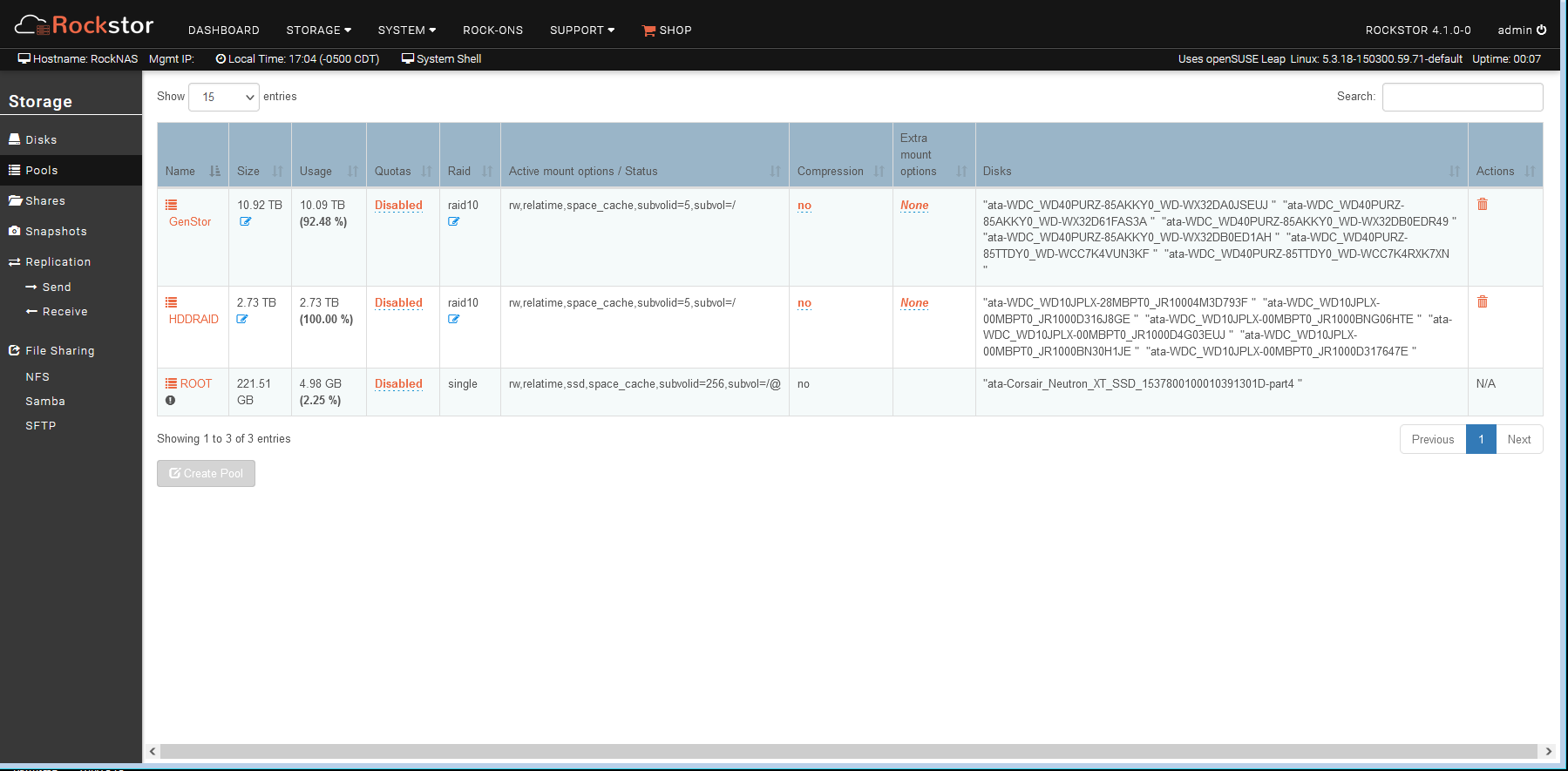
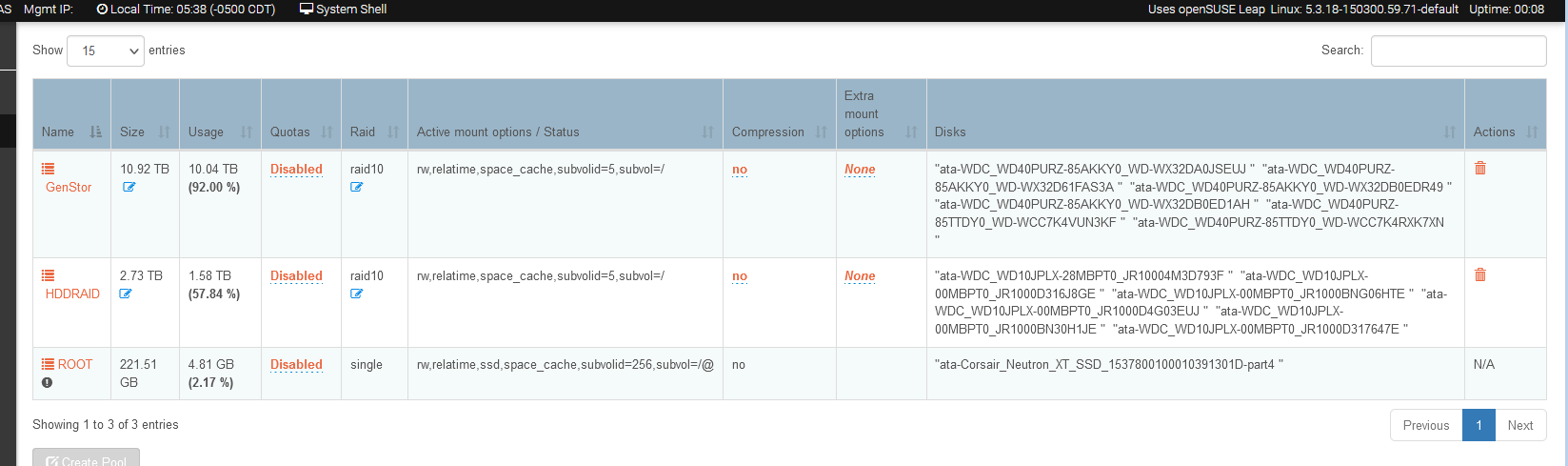
After the last update, Share and Pool sizes messed up. Trying a scrub on the 2.73TB Raid 10 pool which seems to be stuck at 100% usage even after 1TB data deleted.