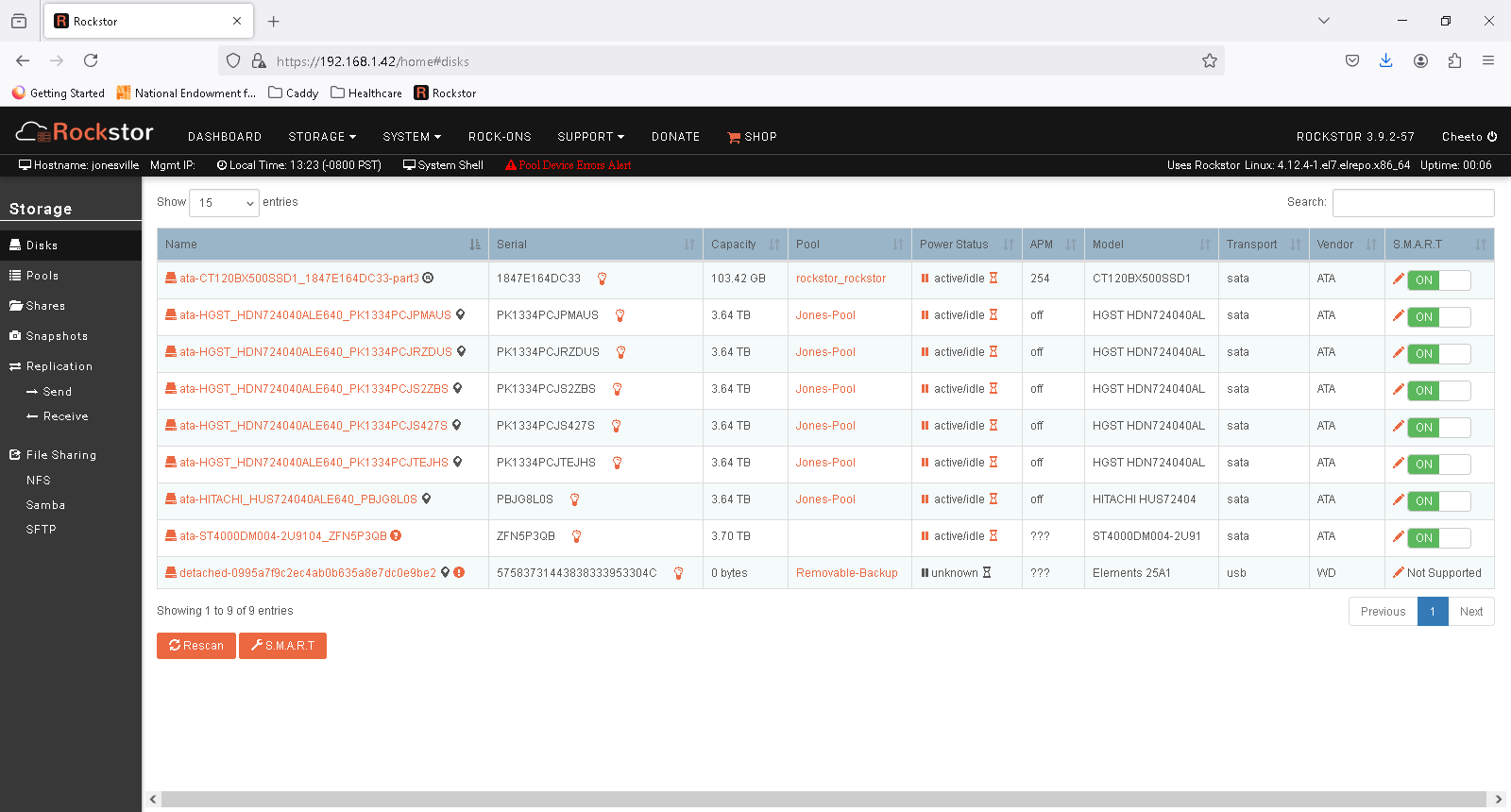
Running older CentOS version 3.9.2-57
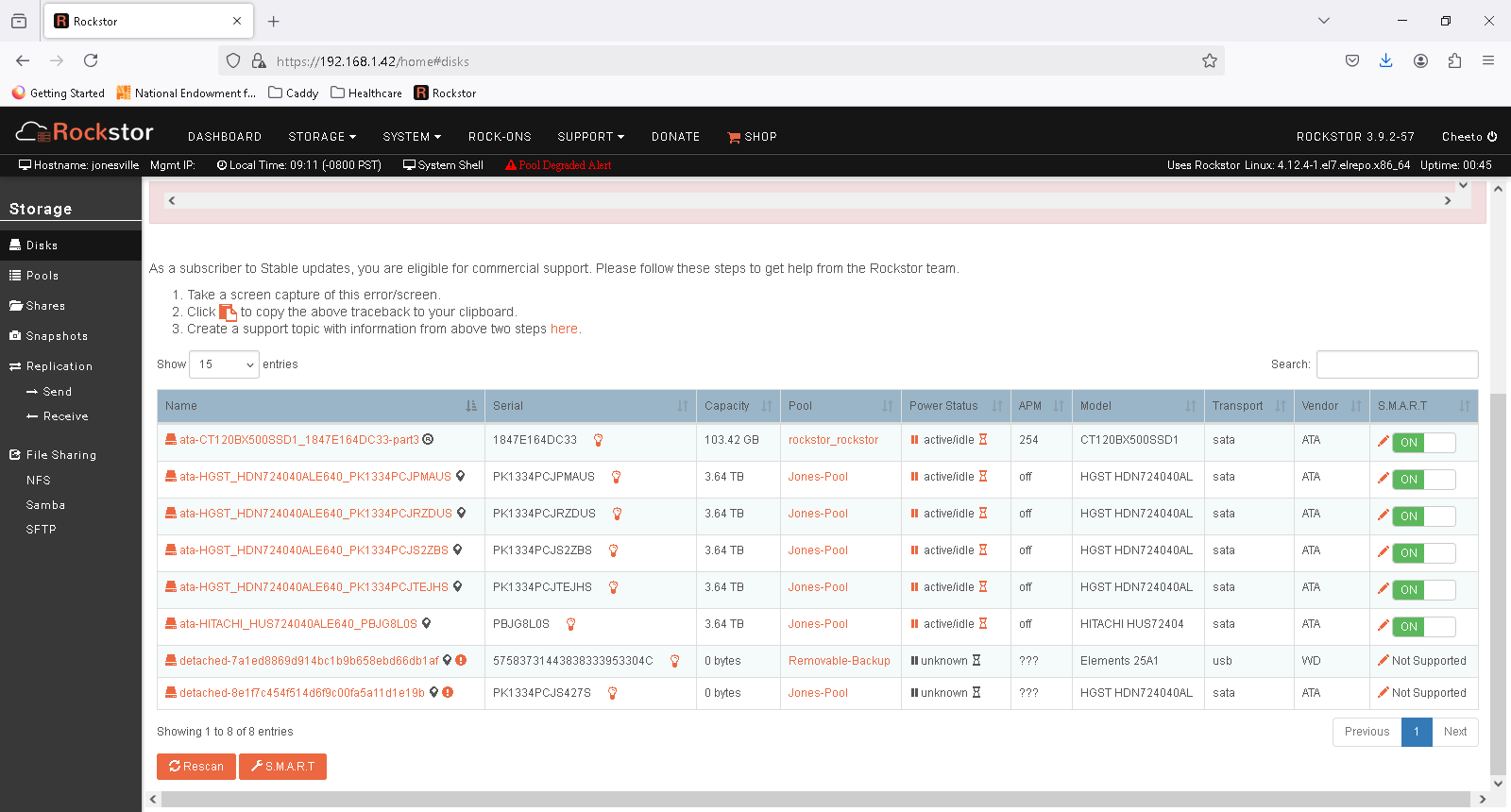
I had a detached disk showing in the pool and a degraded pool alert. The stats page for the disk looked OK, so I rebooted the system to see if it would clear and now I have no access to the pool data in the UI, but I can see the disks in the UI. I can SSH into the box. The detached removable drive has been there for a while with no problems and previous attempts to remove it have failed, but I tired again today again with no luck. I get an error that says it can’t remove it because it’s not attached. I have no access to shared from windows machines on network. OpenVPN rockon doesn’t appear to be running. Everything was working prior to reboot, but with pool degraded alert at top of page. I should have a replacement hard drive in a few hours.
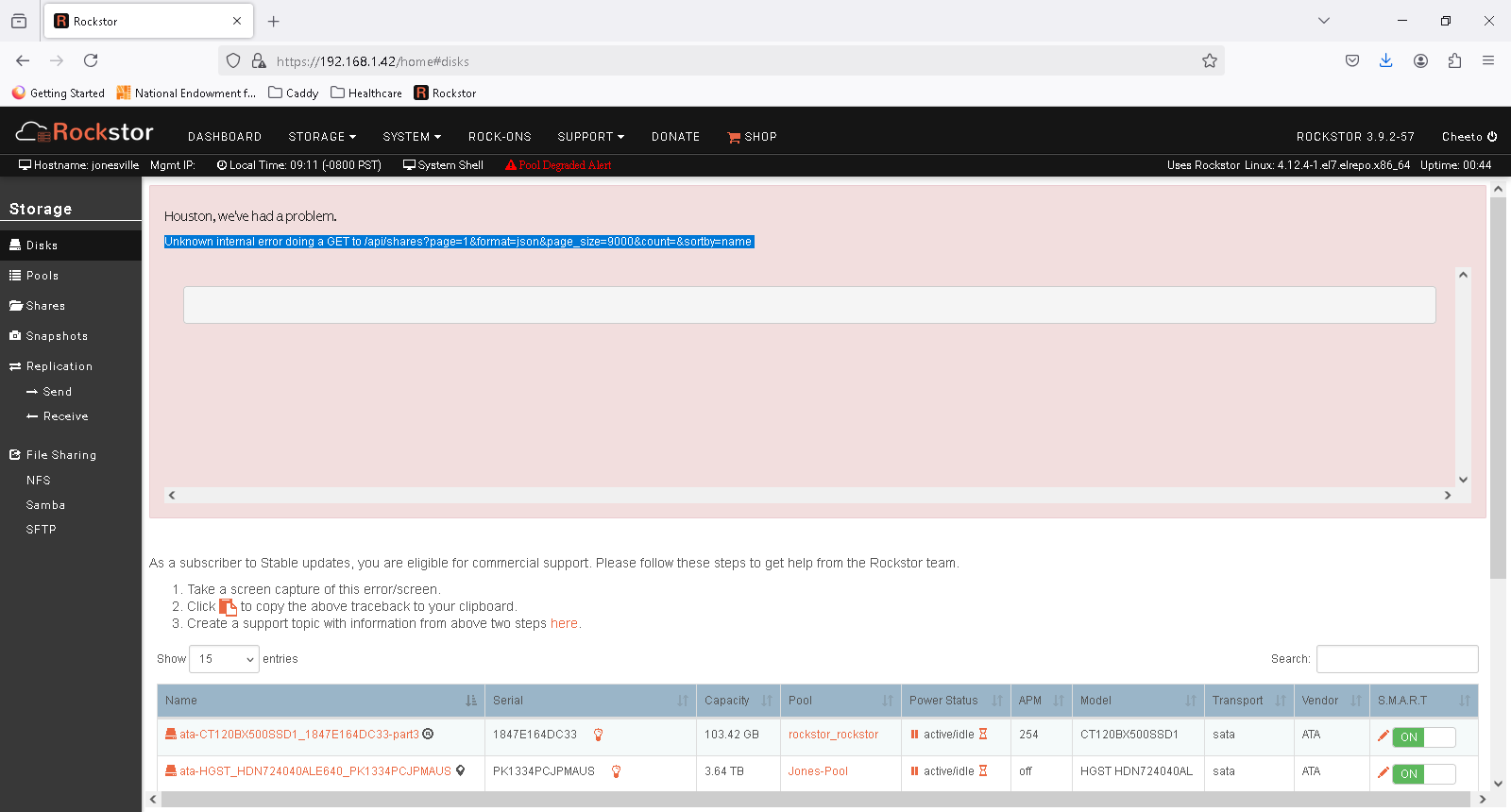
Pool data now available in UI, maybe I wasn’t patient enough the first time. Still showing the same GET error on the top of the UI.
Detailed step by step instructions to reproduce the problem
Unknown internal error doing a GET to /api/shares?page=1&format=json&page_size=9000&count=&sortby=name
Rockstor.log tail provided the following.
[root@jonesville log]# tail rockstor.log
return func(*args, **kwargs)
File “/opt/rockstor/src/rockstor/storageadmin/views/command.py”, line 348, in post
import_shares(p, request)
File “/opt/rockstor/src/rockstor/storageadmin/views/share_helpers.py”, line 86, in import_shares
shares_in_pool = shares_info(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 685, in shares_info
pool_mnt_pt = mount_root(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 525, in mount_root
‘Command used %s’ % (pool.name, mnt_cmd))
Exception: Failed to mount Pool(Removable-Backup) due to an unknown reason. Command used [‘/usr/bin/mount’, u’/dev/disk/by-label/Removable-Backup’, u’/mnt2/Removable-Backup’]
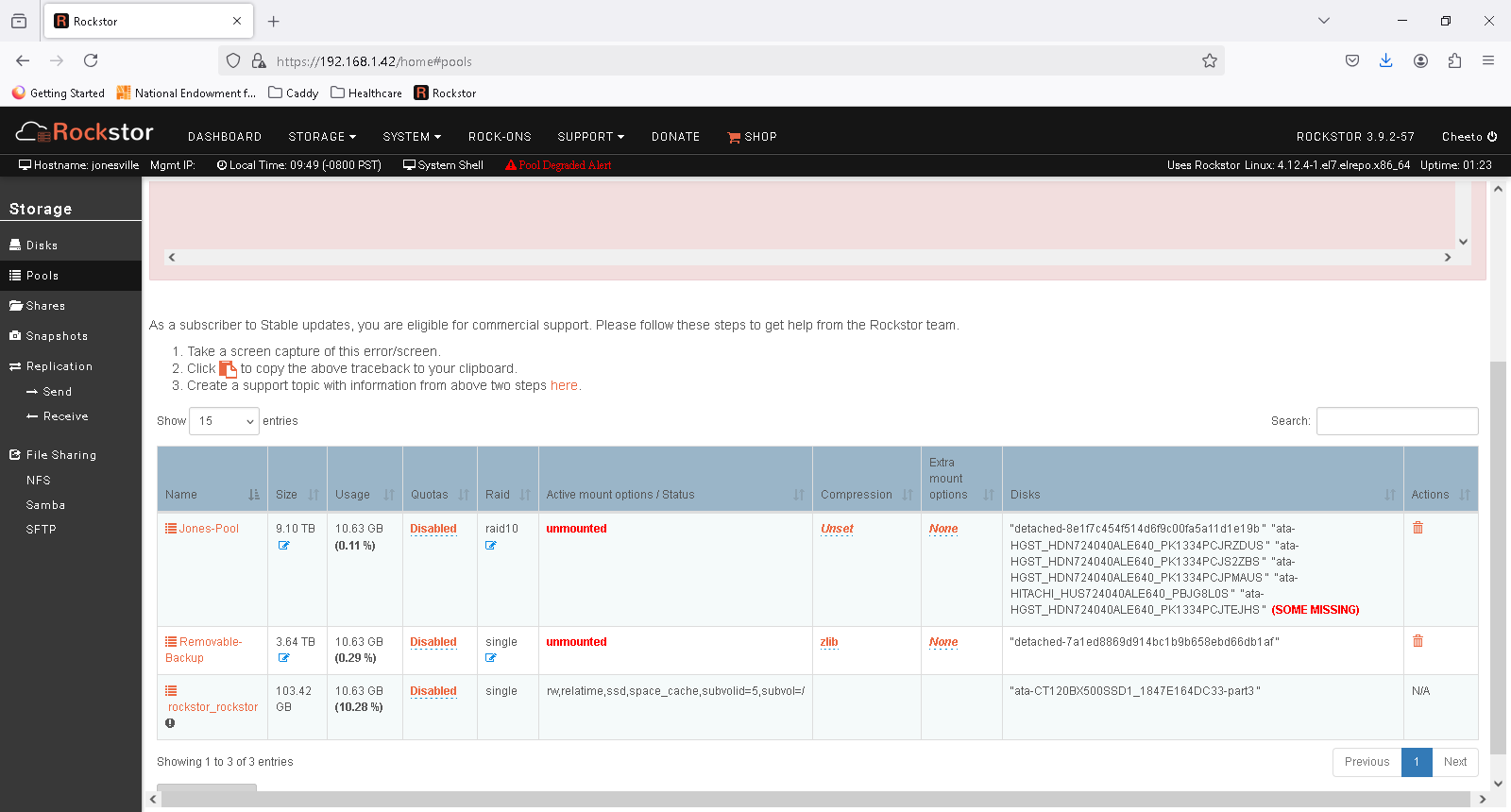
I assume I need to remove the drives via command line to restore the pool, but not sure where to start.
That would still leave you with the non-functional drive for your jones-pool pool. I think you can mount that pool as degraded using the command line, and then use the replace function via the WebUI.
while it has been updated to account for the Built on OpenSUSE versions, I believe the process of mounting the pool degraded and then attempt the replace (or add new disk and then remove broken disk) still holds true. Ideally, once you are able to mount it as degraded do:
Configuration back up via the WebUI - and offload to a non-Rockstor location
ideally back up your pool data to another device (assuming your Removable-backup drive is for?)
Then deal with getting that pool clean again … and then
move to the latest testing release or at least latest stable.
Luckily I just finished a full backup to 2 removable USB drives connected to a windows client. The one that shows in the pool is too small these days. It’s been living there for a while with no issues. Drive 3 being detached, on of the HGDT drives appears to be the one that caused the error. I’m running so close to full I’m going to need to add a drive to the pool before I remove one, or I’ll have to move to RAID 0, remove drive, add drive, and then convert back to 1.
If your existing pool is pretty full, I would then opt for, if you can, add the new drive, before removing the other one “officially”. I would not mess with the RAID level until you have a healthy pool again.
IT gremlins were kind to me today. Powered down added new drive, re-seated errored drive and everything came back up. I just need to investigate the error alert and figure out if it’s the missing USB drive or not.
If you’re not using that USB drive, you could remove that pool via the WebUI … that would give you an immediate answer.
For your working-again pool, it might be useful to do a scrub and a balance to clean out inconsistencies and get the system to balance the load more across the new drive as well …
With regard to the repair scenarios and removing pools with all missing drives etc, we have addressed quite a few bugs on that front since the CenOS days and 3.9.2-57 (April 2020). Plus the underlying btrfs is way better; especially on our new preferred target of Leap 15.6. Not that helpful to you right now however. So what @Hooverdan said re scrub etc and once you have a healthy main pool again you can approach (time allowing) the transition to our modern openSUSE variant. Note that we have also recently update the following how-to:
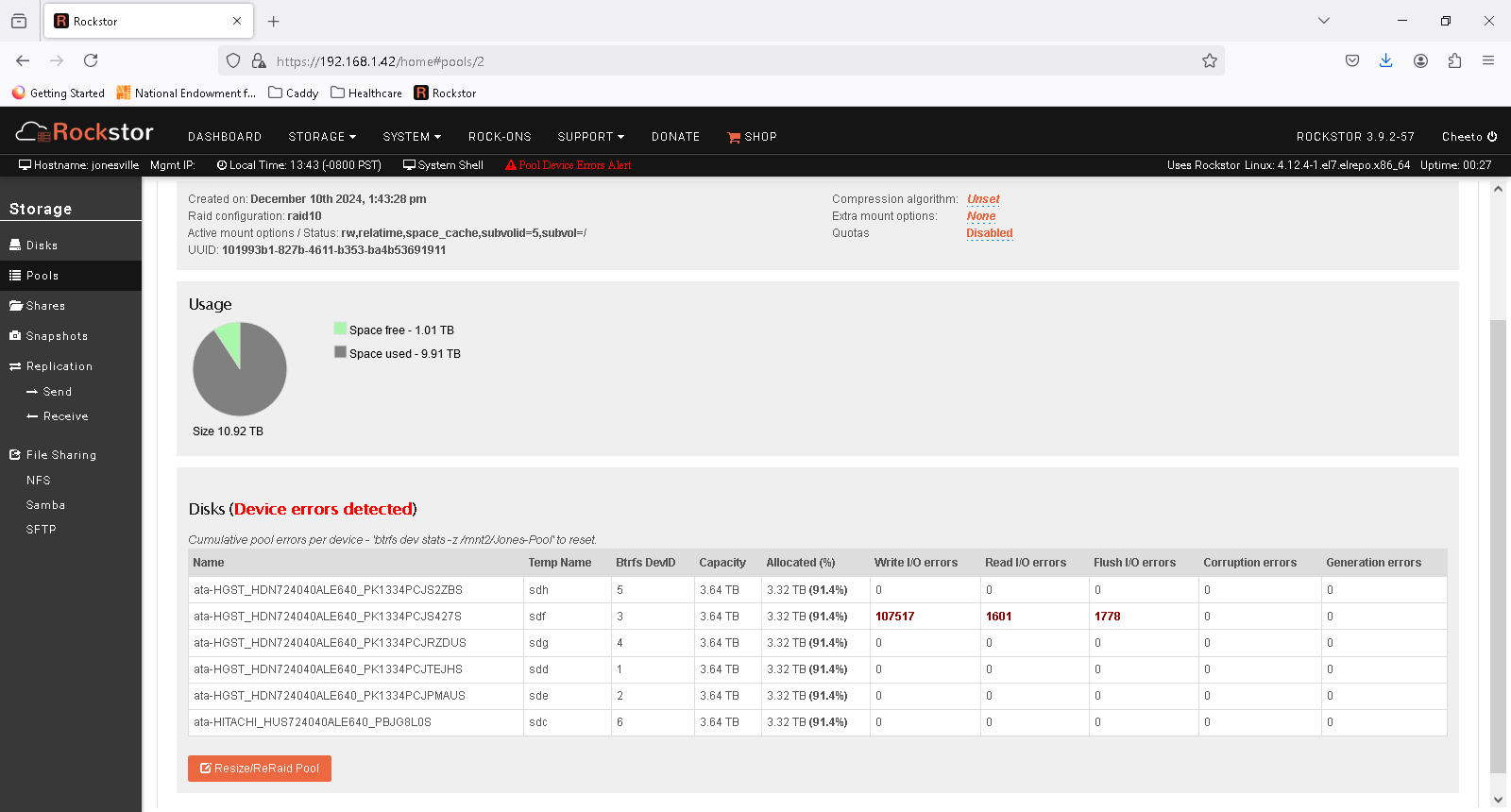
The errors reported on that flaky dive in the main pool are accumulative. I.e. they show all errors encountered since the drive was part of this pool, or since they were last reset. The indicated command there (text above table) can be used to reset those stats so you can more easily see if there are any new errors generated.
Assuming the USB drive is not connected, and it’s the only member of that Pool “Removable-Backup”, you may have success with deleting the pool. But again we had more bugs back then in this area !!
Well done for stringing along this old CentOS install for so long by the way. And once that main Pool is healthy again - we can attempt approach any issues with it’s import. But a good scrub before hand, with your existing kernel, without any custom mount options, can only help.
New drive added, old drive removed, balance running, fingers crossed! Going to ignore USB drive for a while, even deleting to pool didn’t work. CENTOS here I come, if’s funny how the threat of data loss can change your priorities. Unfortunately out of town for 10 days before I can get to that.
I’m back to working on getting my server ready for a migration to the current rockstor, and would appreciate a little strategy guidance. Before I headed out of town I installed a new 4TB drive and kicked off a balance to add it, and then shortly after that balance started I kicked off one to remove the failing drive. In hindsight I think I should have waited to start the remove balance. I’ve definitely confuse the UI.
when I run a btrfs balance status from the command line I get no balances running. I’m not really concerned that I confused the UI, but the results aren’t as expected. The new drive it there, but so is the old drive, and the old drive is shown with 2 entries at the top of the table.
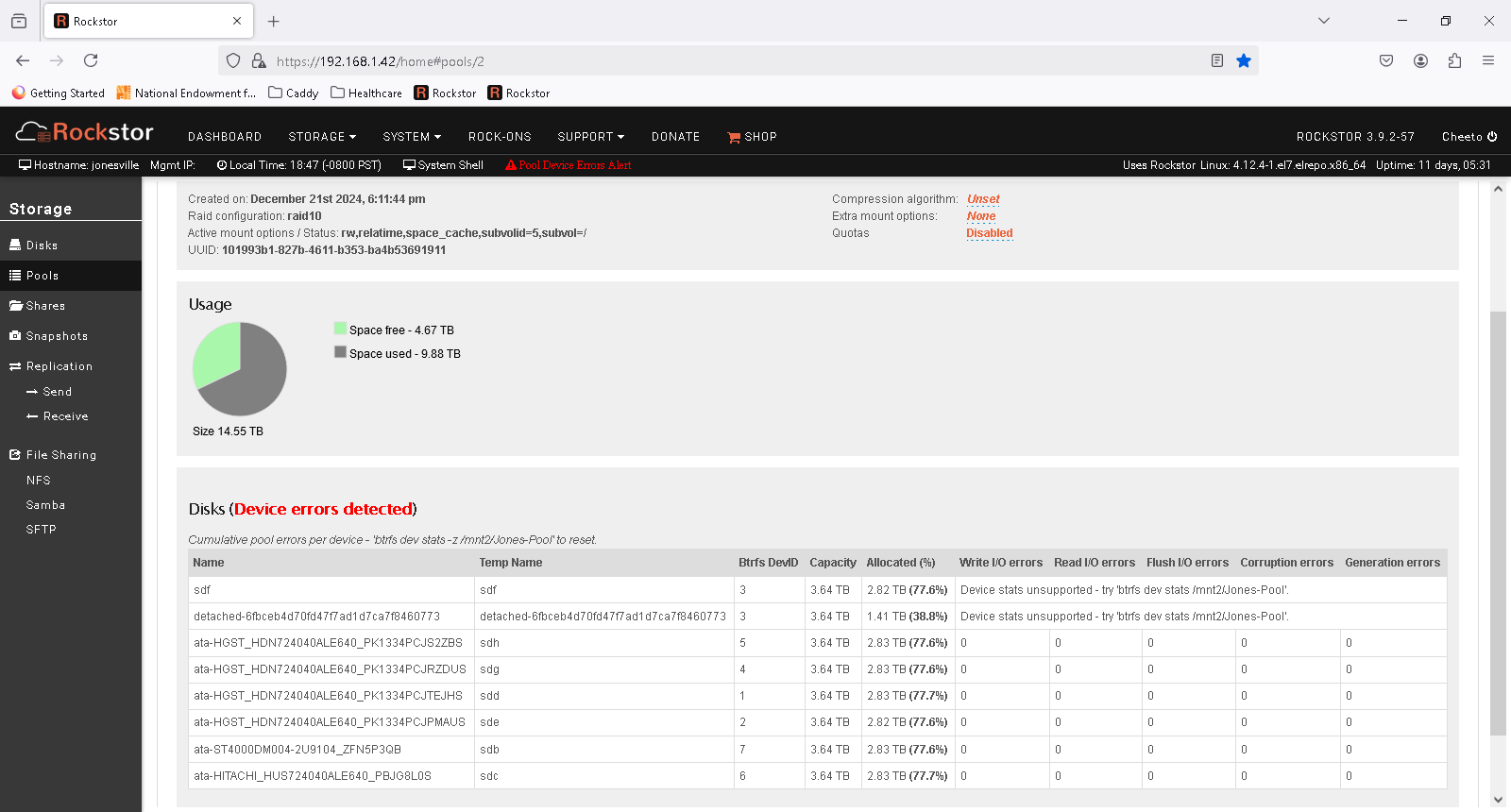
Label: ‘Jones-Pool’ uuid: 101993b1-827b-4611-b353-ba4b53691911
Total devices 7 FS bytes used 9.88TiB
devid 1 size 3.64TiB used 2.83TiB path /dev/sdd
devid 2 size 3.64TiB used 2.82TiB path /dev/sde
devid 3 size 3.64TiB used 2.82TiB path /dev/sdf
devid 4 size 3.64TiB used 2.83TiB path /dev/sdg
devid 5 size 3.64TiB used 2.82TiB path /dev/sdh
devid 6 size 3.64TiB used 2.83TiB path /dev/sdc
devid 7 size 3.64TiB used 2.83TiB path /dev/sdb
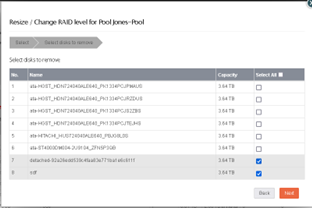
I don’t like the fact I’m running so close to max capacity so I’ve got a couple 12TB disks on order. My original thought was to install1 of them and rebalance to add. Then when the add is done run another remove on the bad disk. (maybe from the CLI) Assuming that works, add the 2nd 12TB drive to the pool. After those 2 are added I’ve got one more drive that starting to log SMART errors, so remove that one. When that’s done I hope to have a healthy pool and can start migrating. So that was plan A, but after a little thought I came up with a plan B.
Add a 12TB drive as a new single disk pool and move all the data. Then I can be more aggressive in removing the existing failed drive. If that’s successful I install the 2nd 12TB drive, add it to the new pool, and configure the 2 12TB drives as a RAID1 pool. Ideally that leaves me with 2 healthy pools and I can start my migration, or it leaves me with 1 healthy and one unhealthy at which point I migrate but only import the new healthy 2 drive pool
I know a pool with different size drives isn’t ideal, but I understand btrfs can handle it.
Love to hear thoughts on how you’d recover from this situation. One limiting factor 8 bay hot swapable case, 7 bays currently in use, so I have to get rid of 1 of the 4TB to add the 2nd 12TB.
Thanks, Del
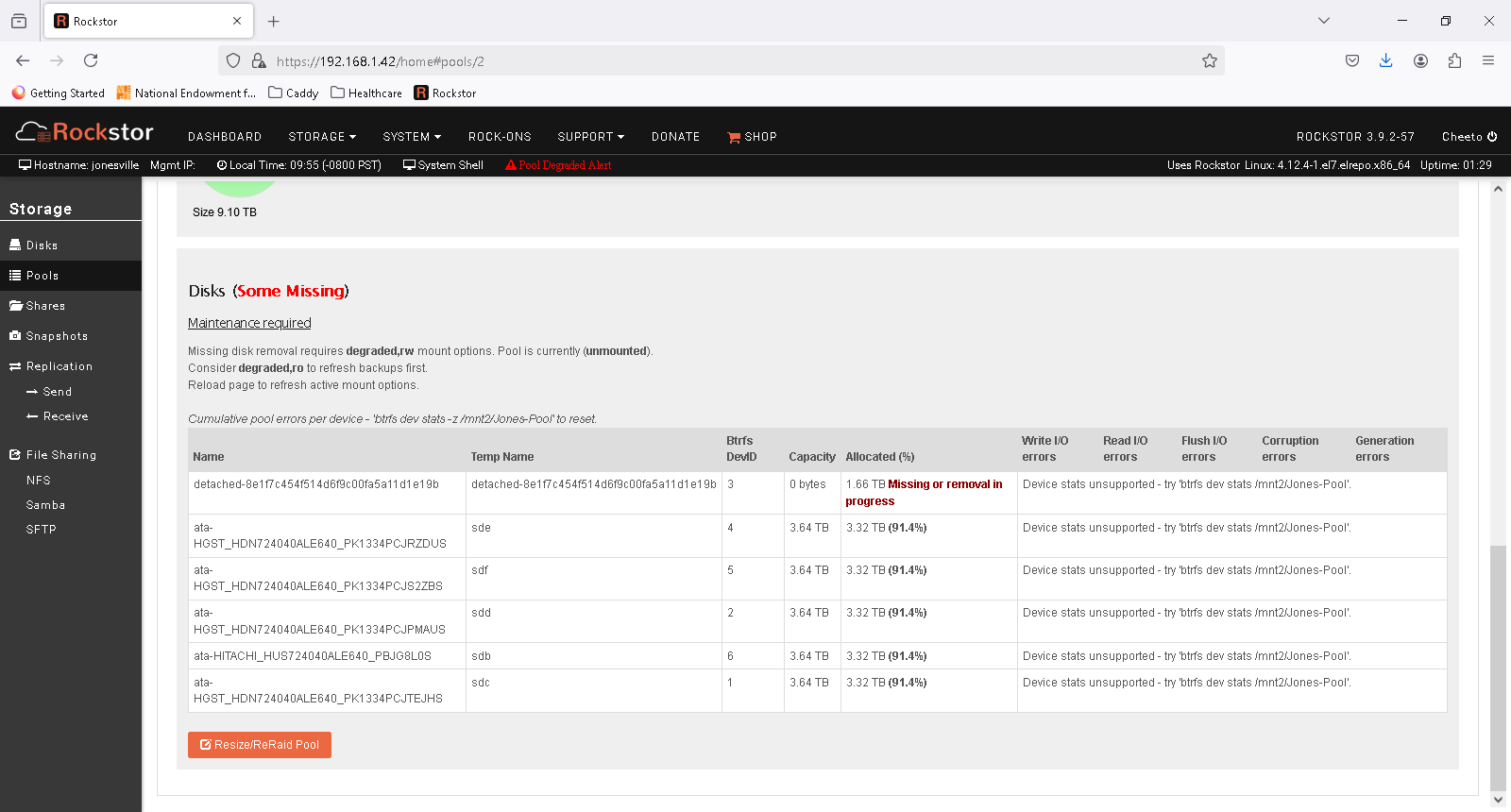
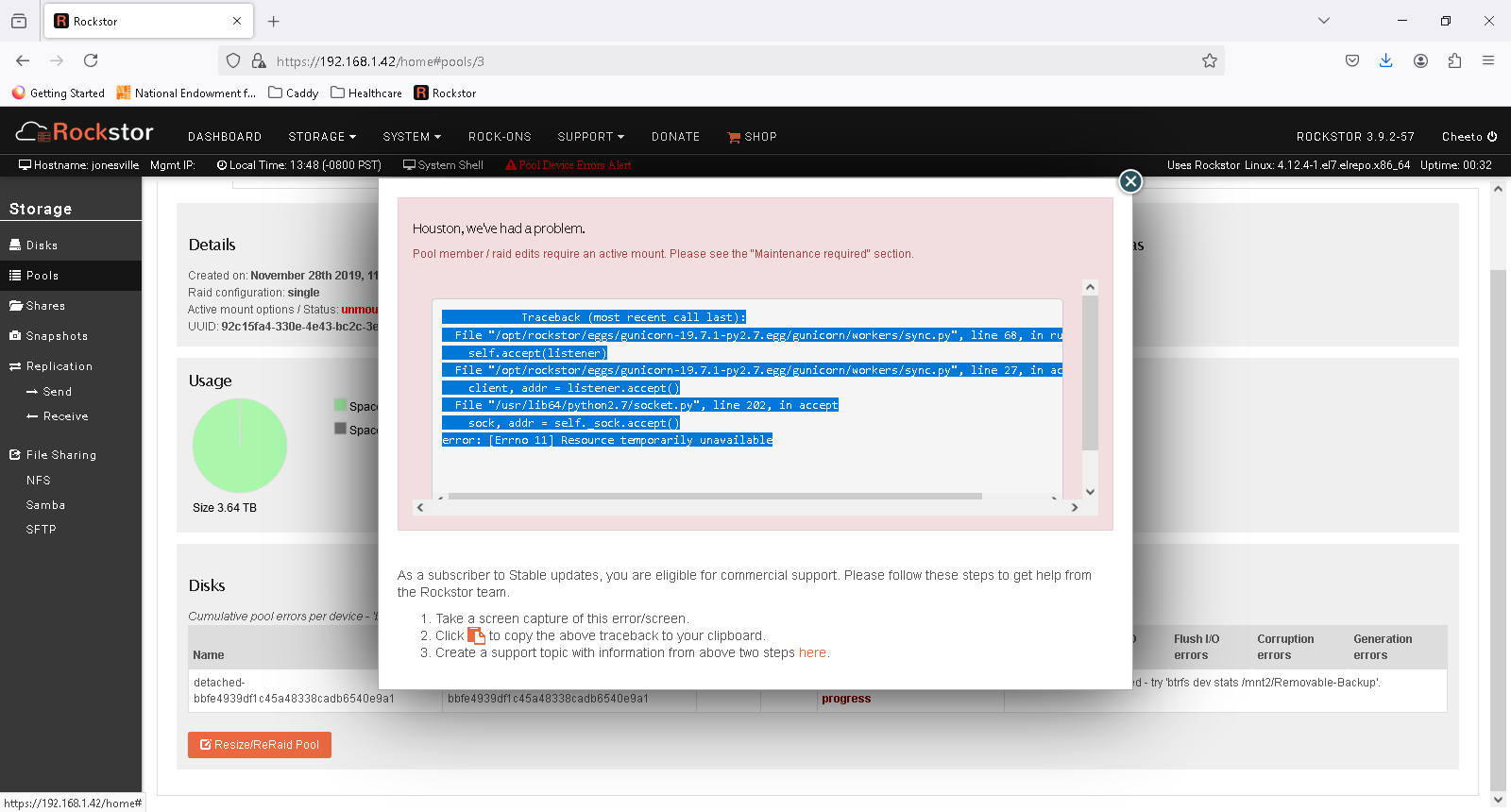
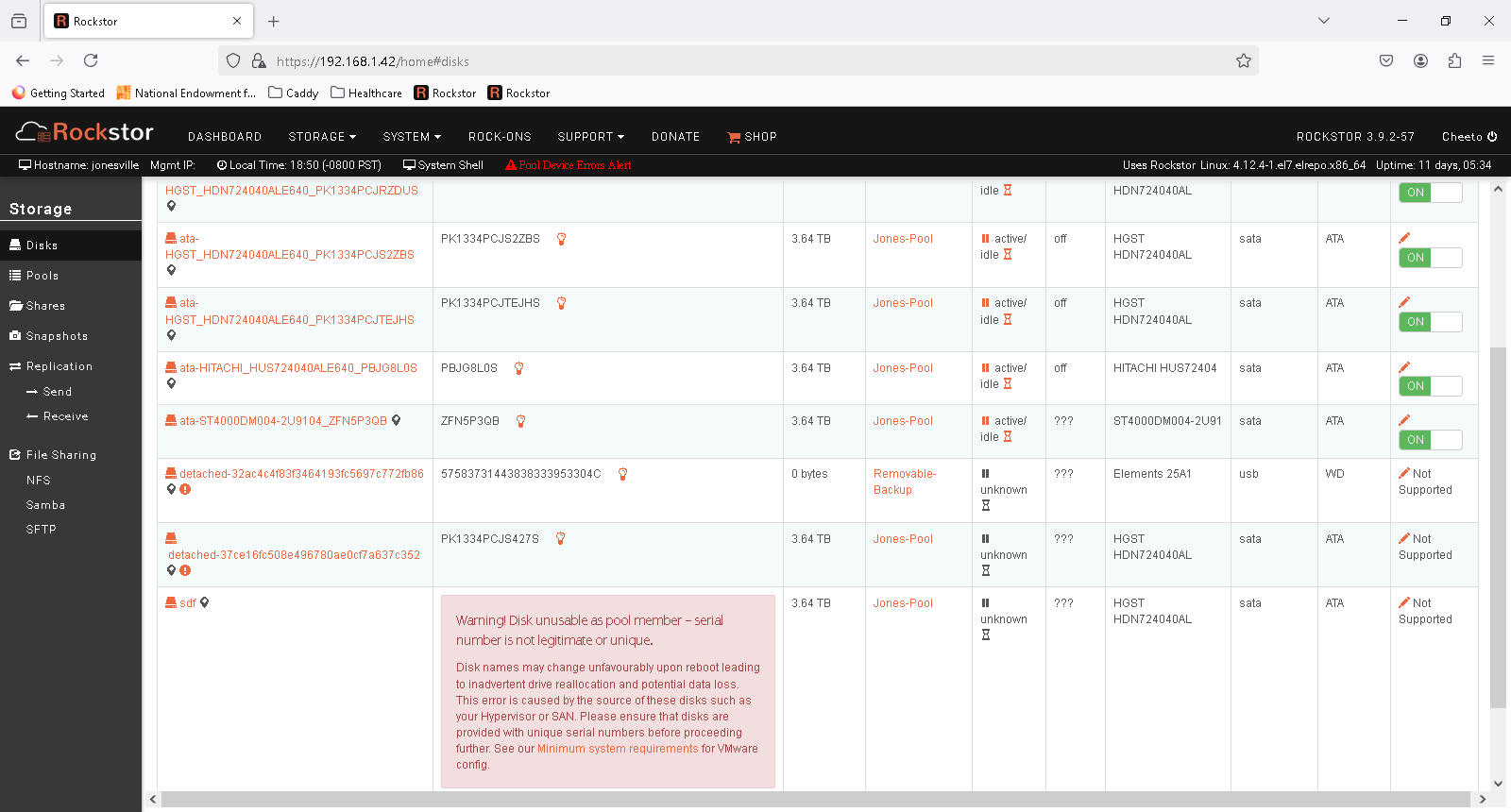
I made another attempt to remove the bad drive with the UI remove disk option and it says it ran, and the balance shows 100% complete, but the drive is still there. I think at this point I need to work in the CLI.
Based on this UI window
and this filesystem show command output
[root@jonesville ~]# btrfs filesystem show /mnt2/Jones-Pool
Label: ‘Jones-Pool’ uuid: 101993b1-827b-4611-b353-ba4b53691911
Total devices 7 FS bytes used 9.86TiB
devid 1 size 3.64TiB used 2.83TiB path /dev/sdd
devid 2 size 3.64TiB used 2.82TiB path /dev/sde
devid 3 size 3.64TiB used 2.82TiB path /dev/sdf
devid 4 size 3.64TiB used 2.83TiB path /dev/sdg
devid 5 size 3.64TiB used 2.82TiB path /dev/sdh
devid 6 size 3.64TiB used 2.83TiB path /dev/sdc
devid 7 size 3.64TiB used 2.83TiB path /dev/sdb
I think the command of choice is
btrfs device remove /dev/sdf /mnt2/Jones-Pool
Although I’ve been doing some reading, and it sounds like remove works before the drive fails. I may be beyond that since the UI shows the drive as detached. In which case I think my command of choice is
btrfs device delete /dev/sdf /mnt2/Jones-Pool
Since sdd is device 1, I assume it’s the device used to mount the pool so I can remove or delete sdf.
My case supports hot swapping so if the remove fails, I may try and pull and reseat sdf and see if it reconnects long enough to remove. If that fails I’ll move on to the delete command.
Before I go flailing around on the command line, can I get a quick sanity check please?
Thanks,
Del
the real expert here is @phillxnet probably, but my 2 cents would use your Plan B.
and try the CLI remove option first and then the delete, if all else fails. Though, I think you might want to try the reseating before any of that like you suggested.
As for the replacing and rebalancing, the more space you have (at least for the first device you’re replacing) add and then subsequently remove might be the safe option, especially since you’re not on the latest btrfs improvement that have happened since Rockstor moved from CentOS to OpenSUSE…
You could contemplate cleaning up the sdf device, perform the move to the newer version and then use the disk replace option (though you have the bay/connection restriction).
@phillxnet I should probably check one assumption. I’m assuming I can’t move to Rockstor 4.6 or 5.0 until I have a healthy pool with no device errors. However, I also know the newer btrfs is more capable. Do I have to fix my problems in my current version before migration, or should I migrate and used the improved btrfs functionality to fix my pool?
One other question, does the CentOS version support RAID 1c3? I’m thinking about re-raiding my pool from RAID 10 to gain more space.
Thanks and Merry Christmas (or holiday of your choice),
Del
Total 9.86TiB 13.41GiB 96.00MiB 22.87TiB
Used 9.84TiB 10.85GiB 928.00KiB
[root@jonesville ~]# btrfs balance start -v /mnt2/Jones-Pool
Dumping filters: flags 0x7, state 0x0, force is off
DATA (flags 0x0): balancing
METADATA (flags 0x0): balancing
SYSTEM (flags 0x0): balancing
WARNING:
Full balance without filters requested. This operation is very
intense and takes potentially very long. It is recommended to
use the balance filters to narrow down the scope of balance.
Use 'btrfs balance start --full-balance' option to skip this
warning. The operation will start in 10 seconds.
Use Ctrl-C to stop it.
10 9 8 7 6 5 4 3 2 1
Starting balance without any filters.
Done, had to relocate 0 out of 0 chunks
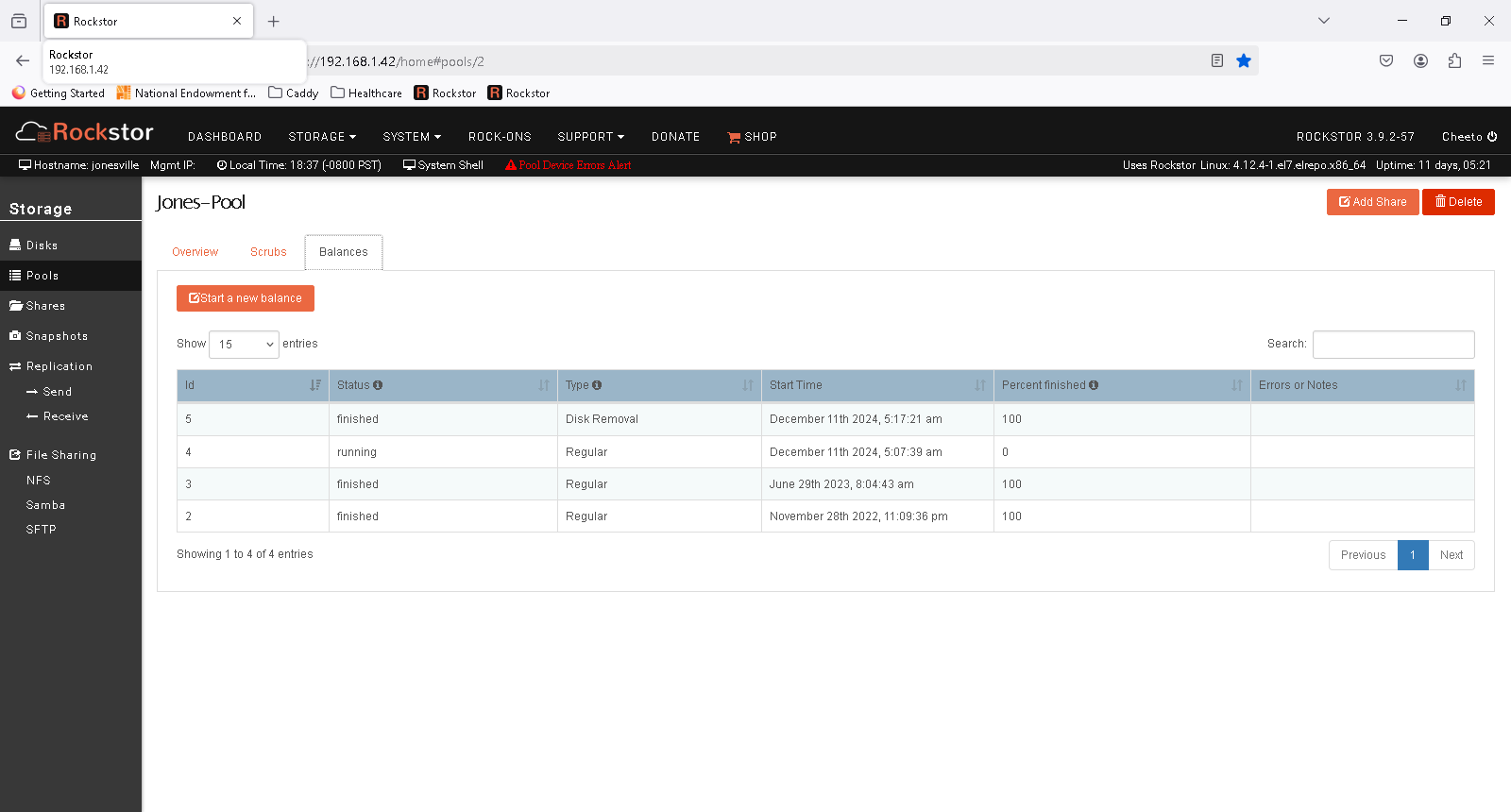
but as you can see at the bottom of this output, when I try and balance it says it allocates 0 blocks.
I notice system RAID 10 isn’t populated for the new drive, but I can find any options on the mount command that look like they would add that.
Open to advice and thank you to all of you for the time you’ve spent helping with this.
Del
You can, but it introduces more variables. Some older Pools in slightly poorly states can be mounted by older kernels (that arn’t so fussed) so it makes them more accessible to correction if they can, at least, be mounted. But as you say:
Yes, way more capable. And it has more repair options. So all-in do what you can where you are (old kernel) but don’t bother forcing/persist beyond frustration as it may well be that the new install will be more than capable of a mount and then provide the fixes from upstream as well as our better behaved Web-UI. You are seeing some Web-UI confusion after all.
No. It took a goodly number of years for this to emerge. But we have it by default now in our Leap 15.6 preferred installer option. And our Web-UI is fullly aware of it and can be used to do the Pool Re-Raid as we call it.
Same to you, and my appologies for the slow response here: busy times as we prepare for our pending next Stable.
I wouldn’t worry about the per-drive allocation, if I’m reading your concern correctly. Btrfs balance can do some very strange things, especially with unbalanced drive sizes. Plus the system having no entry is also likely not of concern. But I’m not certain of this.
That is essentially the system entry. Btrfs-raid10 does involve all drive members. As btfs-raid works on the chunk level: as long as each chunk conforms to the raid level you are good.
As your Pool now appears to have ample free space: Device unallocated: 13.00TiB and you have run a default (and heavy) balance, you might now want to run a scrub via the command line: given the Web-UI’s confusion. Once that is done you may well be set for the new install.
This just means that it is already balanced as per its internal directives. It is normal when, for example, one runs a balance directly after having just run one. Pool member removals will do a special kind of internal balance that doesn’t show up in balance status. We have to infer them for the Web-UI by watching space allocation.
Try a CLI initiated scrub given your pool now looks to be in a better state. As scrub is specifically intended as a health measure: ensuring/testing that all data can be read, and passes checksums. But it could take quite some time. If a read fails from one drive it will try from the redundant copy on another drive: repairing the first if it can.
However if you suspect a drive is about to fail: you should tread more carefully and ensure backups are refreshed before hand. But you already know this :). When a Pool has many older drives, it may be that one poorly drive has a good copy of data A, and another Poorly drive has the only good copy of data B. Btrfs-raid10 still only has a single drive failure capability after all.
@phillxnet I started a scrub and it was taking for ever and causing a lot of errors. I think I need to remove sdf, device 3 that is showing as disconnected. I’m not able to do if from UI or command line, I think becuase it’s a normal mount. I’ve read that there are some limits on how many times you can do a degraded mount so I’ve been holding off, but I think my road ahead is to
mount -0 degraded /dev/sda /mnt2/Jones-Pool
not sure if I need to unmount first or not
then
btrfs device remove missing
then
mount /dev/sda /mnt2/Jones-Pool
again not sure if I need to unmount first.
I did delete a significant amount of data so I do have plenty of room to work with, but I need to get rid of the missing drive, and then one other that’s showing significant SMART errors.
I really appreciate the help, and have a new Rockstor install USB ready to go.
Thanks again,
Del
Tried to umount to mount degrades and got the following error
[root@jonesville ~]# umount /mnt2/Jones-Pool
umount: /mnt2/Jones-Pool: target is busy.
I assume there is a force option, but not sure how aggressive to get any suggestions on how to make is not busy?