[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
[write here] Problem disk formated in windows ans add to system. It does not show up in disk page and when I do rescan I get this error.
Detailed step by step instructions to reproduce the problem
[write here]
Web-UI screenshot
[Drag and drop the image here]
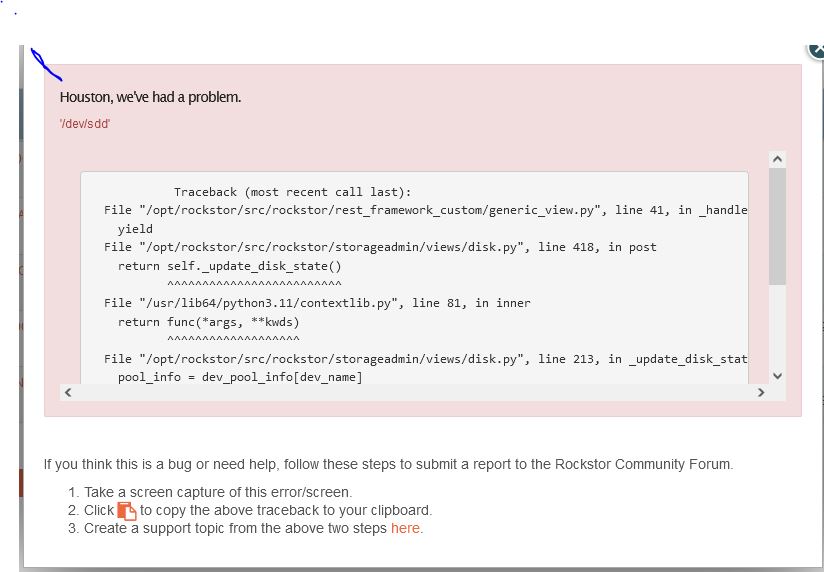
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py", line 41, in _handle_exception
yield
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 418, in post
return self._update_disk_state()
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.11/contextlib.py", line 81, in inner
return func(*args, **kwds)
^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 213, in _update_disk_state
pool_info = dev_pool_info[dev_name]
~~~~~~~~~~~~~^^^^^^^^^^
KeyError: '/dev/sdd'