Hello, all!
So here’s a weird one - old server (HP Micro 8gen) started flaking out so I retired it and built it anew last year with an 8-bay NAS case, purchasing two new IronWolf 10Tb SATA drives for MORE STORAGE. I had four 4Tb drives from the old server, and a spare 3Tb so I chucked it into the case because why not. Built two pools: “Storage” with the two 10Tb drives (intending to replace the others as I could afford it), “Old_Stuff” with the four 4Tb drives (for which pool recovery “just worked” and all four drives re-assembled as a pool when asked).
Moved shares off the “Old_Stuff” pool into the new “Storage Pool” to prep for eventual replacement, and then things got weird and I had to shelve the “buy more drives” project for a bit.

(You may notice something strange there, based on the description - foreshadowing, if you will)
Nevertheless, everything was running smoothly… until now. See, bond0 crashed out (working that issue separately) and when I finally managed to un-bond it to see what was going on, the GUI shows me that things are… confused:
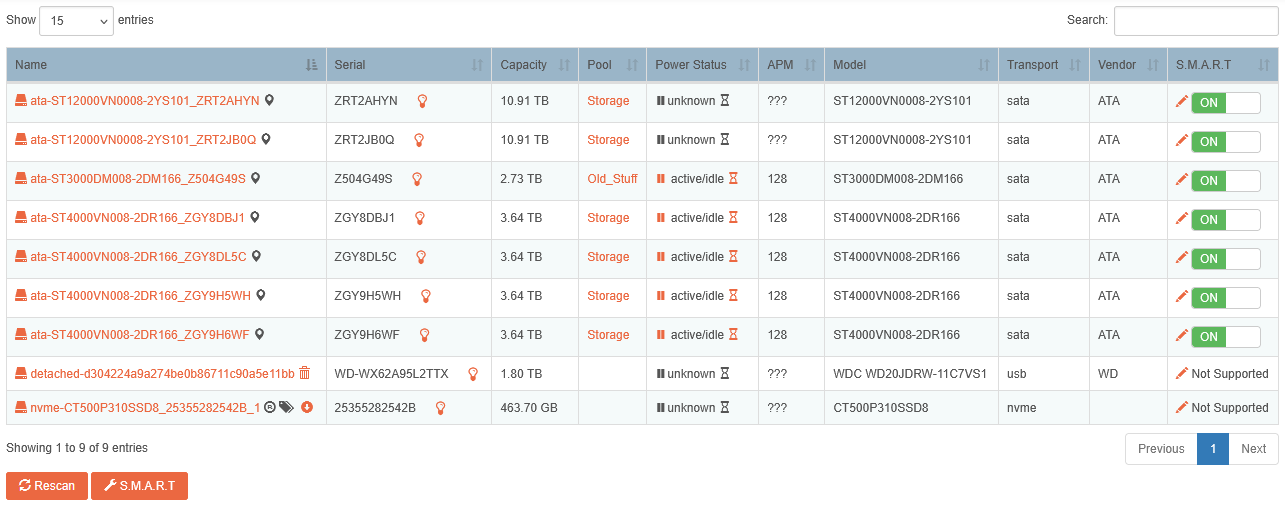
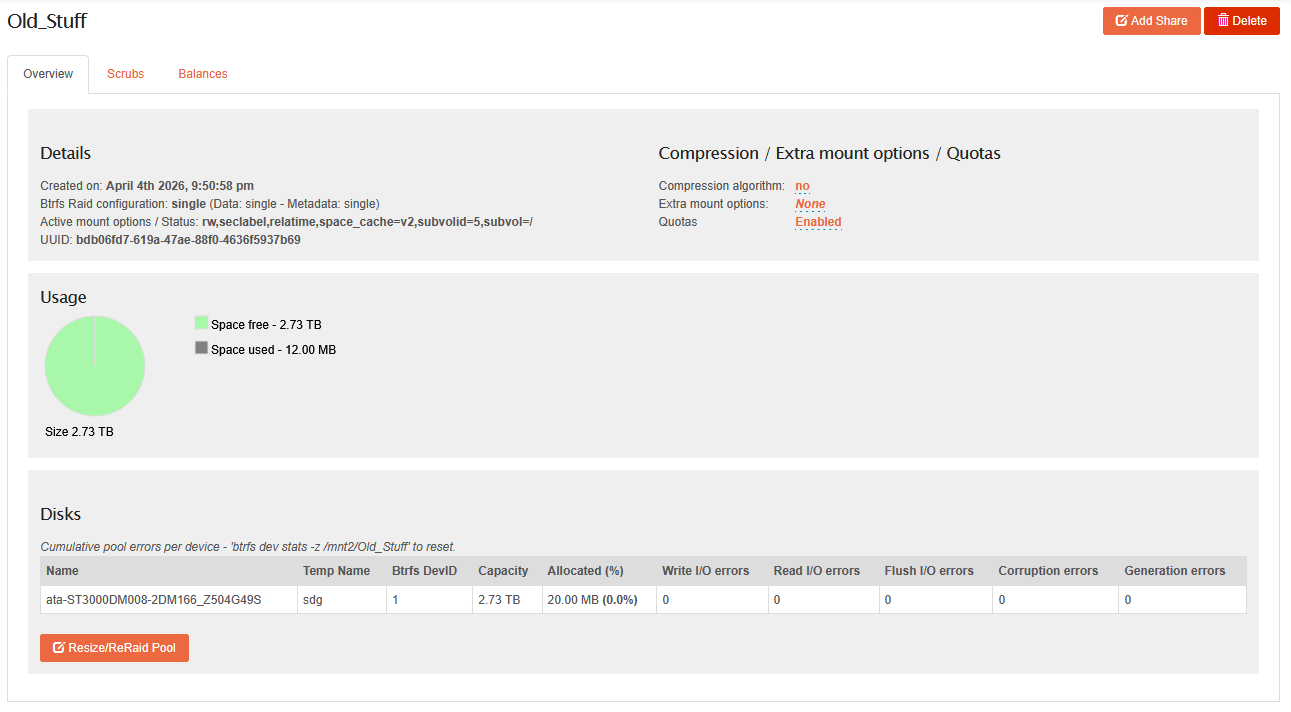
So, top two drives (THE NEW ONES?!?!) are currently flaking out, multiple read errors OMG). Can’t worry about that right now. The 3Tb “why not spare drive” now thinks it’s the only member in the “Old_Stuff” pool, even tho it was never a member:
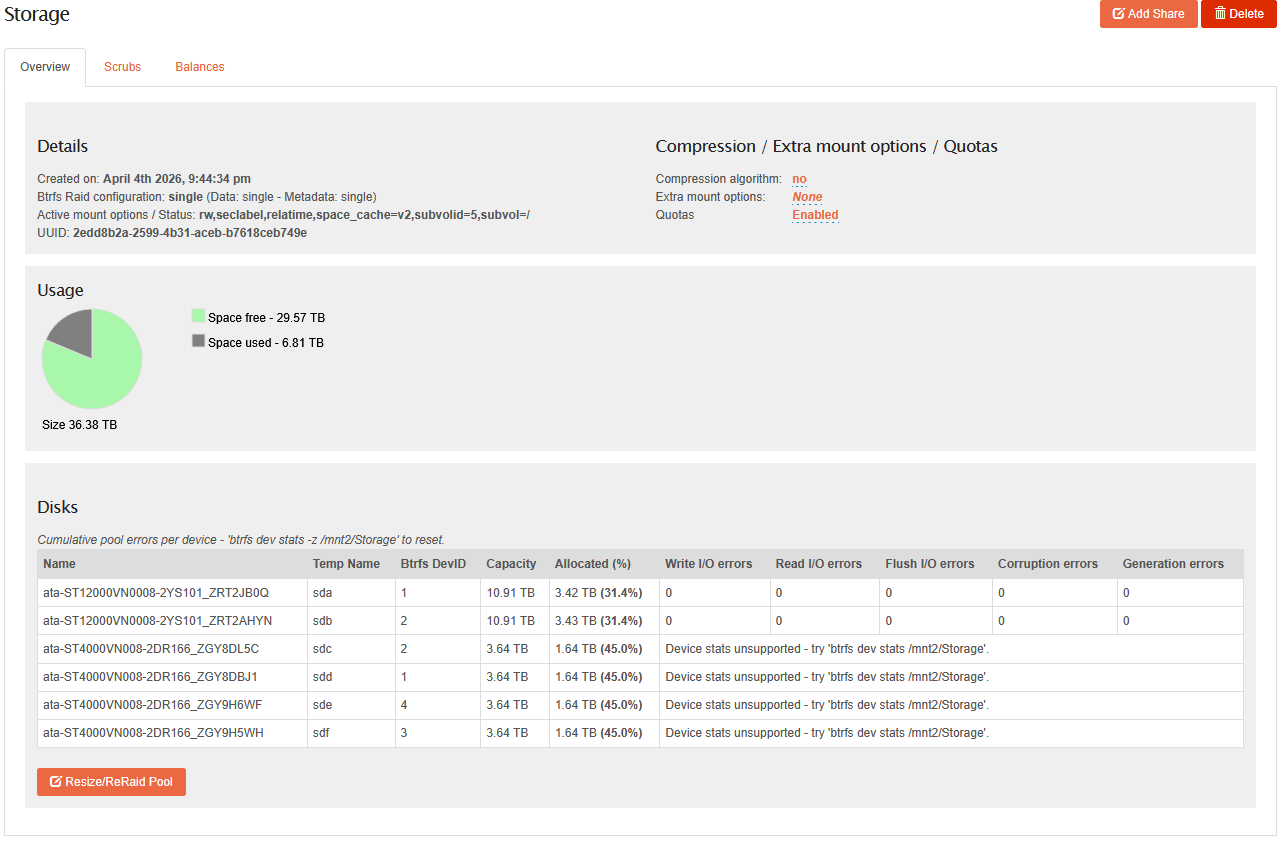
And EVERYONE ELSE is in the “Storage” Pool. (Not sure if it’s significant, but I now have multiple 1 and 2 devices in the pool. Devices that are supposed to be in the other pool):
Trying not to panic because while I do back up via CrashPlan-Pro… there’s a ton of home movies, photos, a massive CD collection, and a ton of DVD/BRDs I laboriously ripped onto the server… and I would prefer not to have to rebuild everything from scratch.
So finally to the questions:
- How bad is this? Everything seems to be working well enough with the shares, still accessible via CIFS/NFS etc. Should I just adapt to this new normal and not worry?
- Is there a way to massage this so that everyone shows up in the correct pool so I can stop worrying about massive amounts of data loss in my near future?
Advices welcome, as always. ![]()
Cheers,
KeithF