Hey, I had an issue on my Rockstor system regarding a HDD not spinning down and I would like to share my findings and workaround.
I have 2 drives in my new Rockstor system:
Seagate IronWolf Pro
Toshiba N300 NAS
Both are 18TB in capacity, SATA-III and are fairly new models (bought in 2023).
For the Toshiba N300 NAS drive I was able to configure the spin-down settings via Rockstor Web-UI and everything worked as expected.
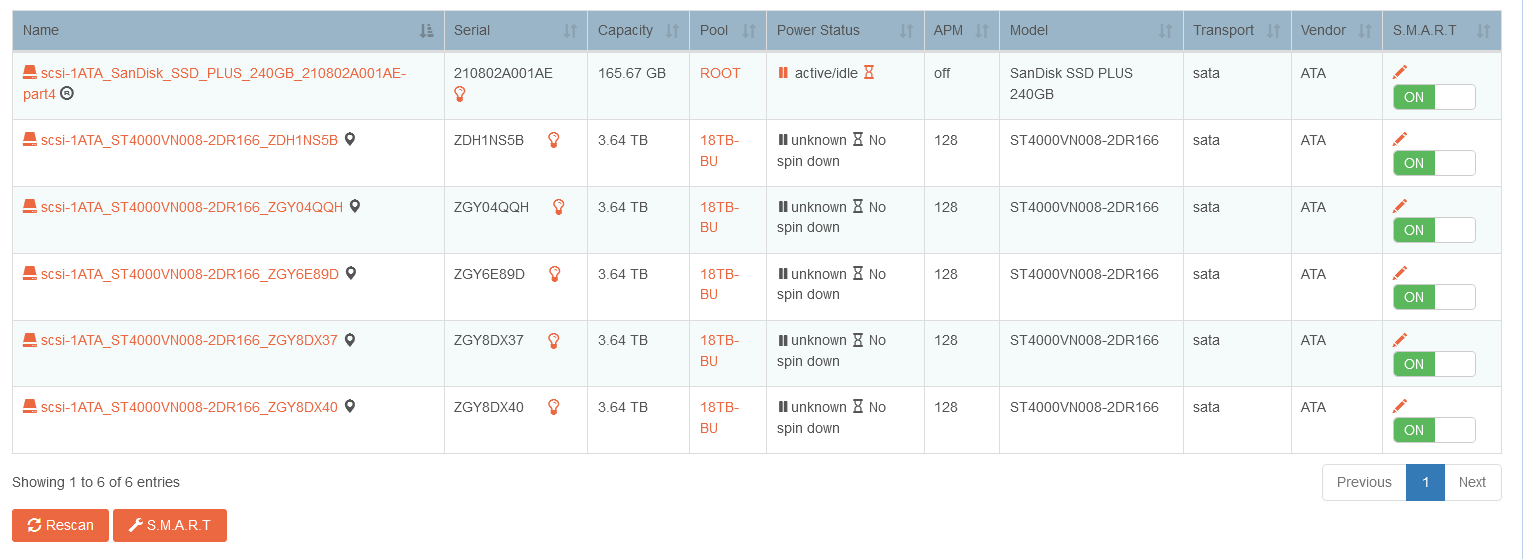
But the Seagate IronWolf Pro drive was not configurable via Rockstor Web-UI.
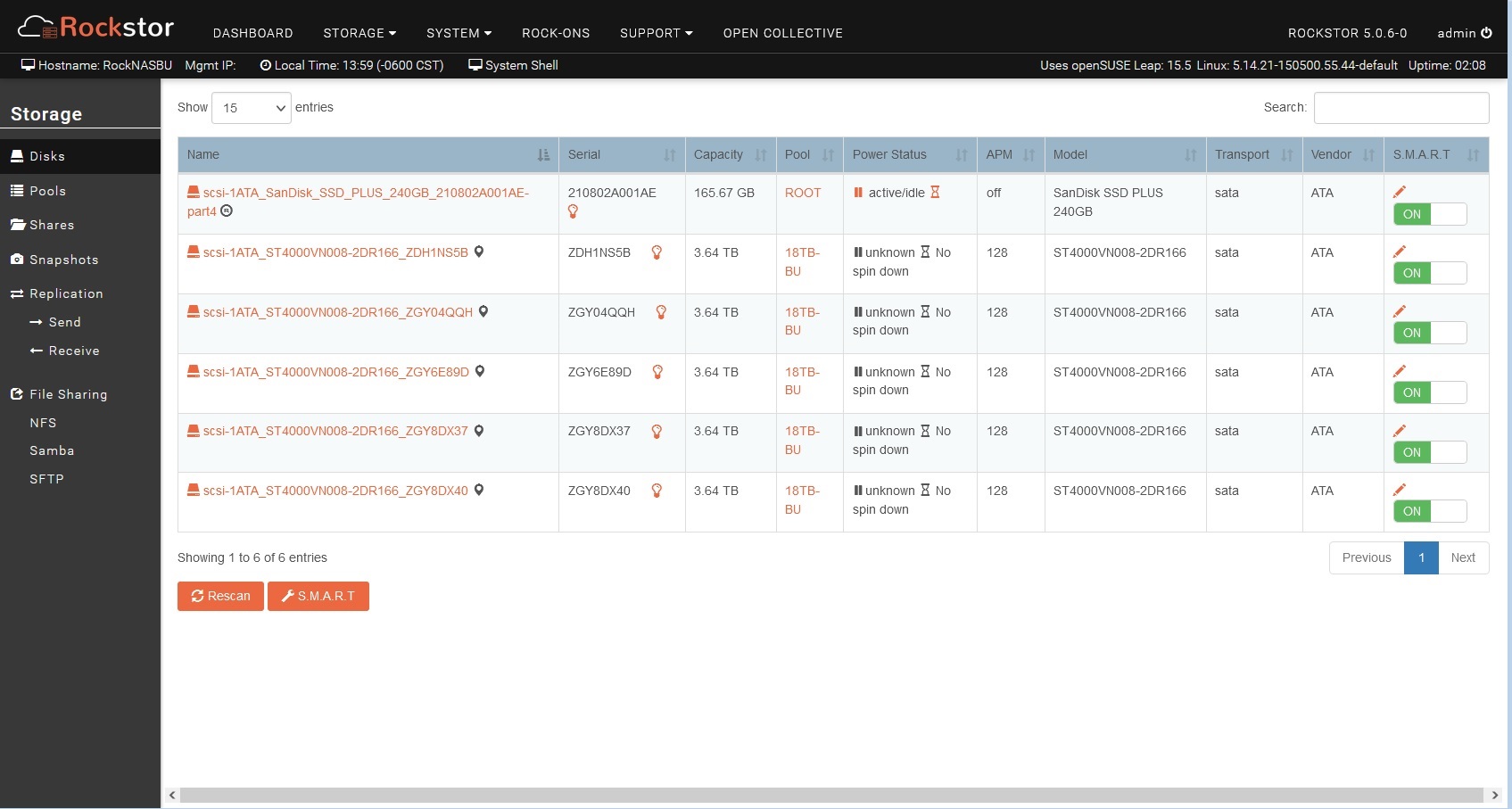
The APM column only shows ???, the Power Status is unknown and I can’t press the hour-glass symbol:
I was not keen on installing openSeaChest from source on a “production” system, so I downloaded the pre-built binaries form the latest release: Releases · Seagate/openSeaChest · GitHub
File: openSeaChest-v23.03.1-linux-x86_64-portable.tar.xz
copy tar-ball to Rockstor via SSH ($ scp openSeaChest-... root@hostname:)
extract tar-ball on Rockstor (# tar xf openSeaChest-...)
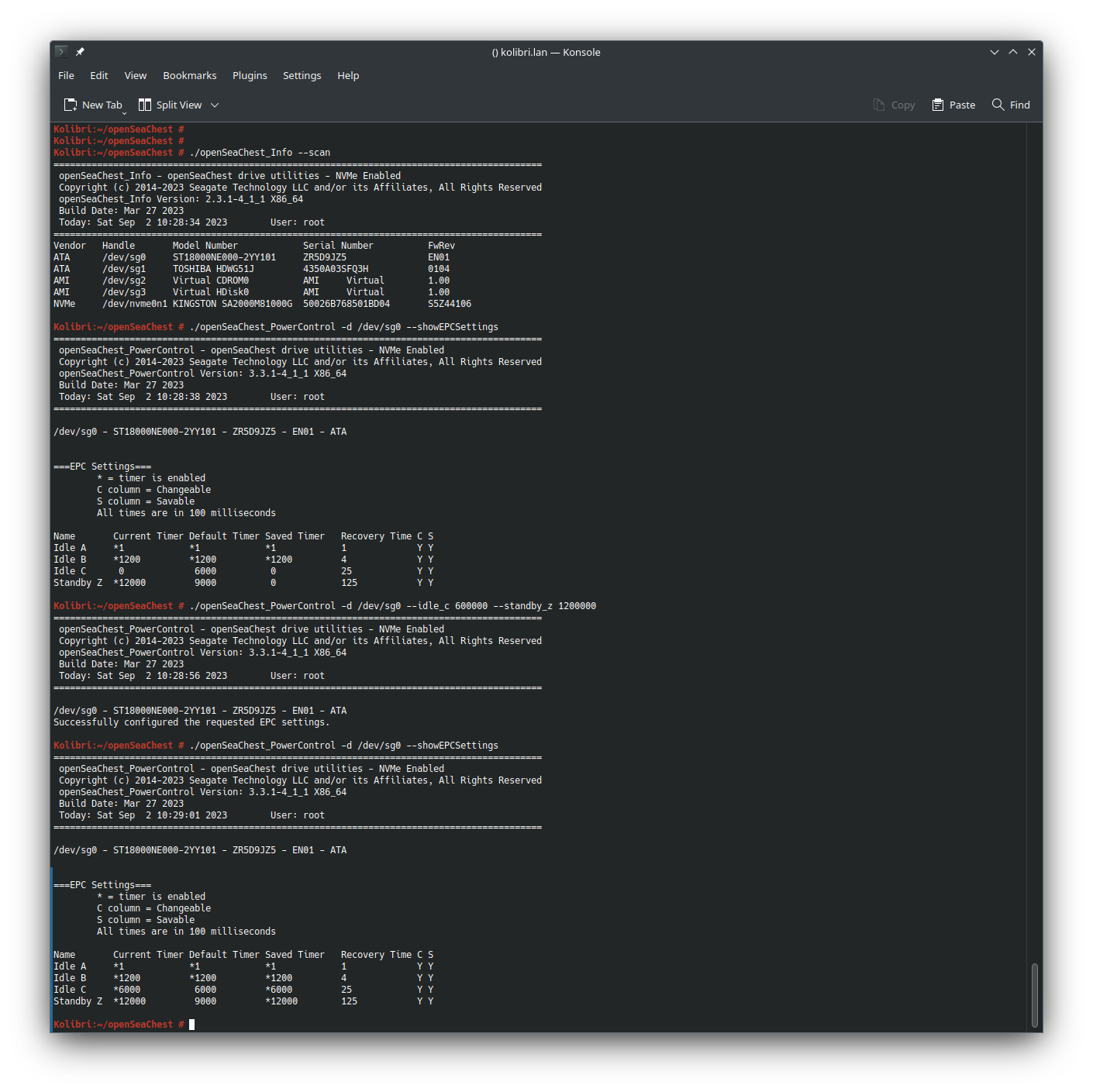
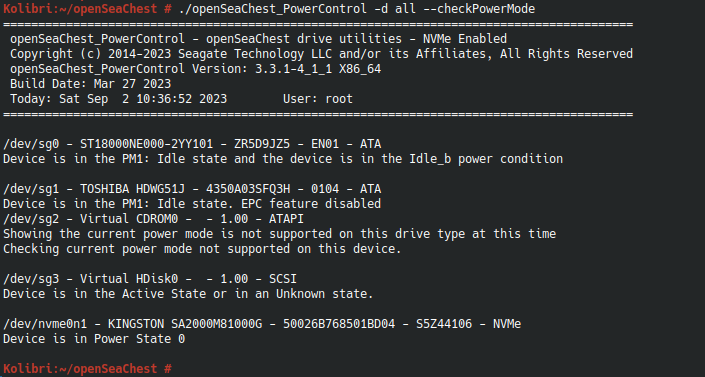
enter the new directory to execute the binaries for setup. ./openSeaChest_Info --scan - list all devices ./openSeaChest_PowerControl -d /dev/sg0 --showEPCSettings - show the timers for drive sg0 ./openSeaChest_PowerControl -d /dev/sg0 --idle_c 600000 --standby_z 1200000 - modify the timers for drive sg0 (idle_c: 60 minutes; standby_z - aka spin-down: 20 minutes)
@simon-77 Thanks for sharing your findings on this one. And a nice bit of investigation there.
I did have some much smaller Seagate IronWolf (non pro) drives, 4 TB I think they were, but no longer have access to those drives unfortunately. They did work as expected, so likely this is a more recent ‘thing’. Shame.
Yes, this is our cue to leave well alone and disable the Web-UI options in this area for given drive:
And we set the disk spindown via:
Which in turn configures/reconfigures the rockstor-hdparm systemd service to enable consistency over power cycling.
Just noting the above in case a little development in the testing channel takes your fancy :).
Thanks again for the heads up on this one. And for sharing your fix/work-around. Indicentally have you ensured that the settings, thus applied, survive a power-cycle. I think hdparm settings survive a reboot but not a power cycle (from memory at least). Hence our use of our dedicated systemd service to re-establish them on boot.
@petrosl Welcome aboard! I also have 5 4TB IronWolf drives that work fine in one setup, but I disable SpinDown normally. However, I may try it in the future!
Also, don’t forget to get your Rockstor case badge!!!
Update: Seems I can’t change the spin-down setting after the pool and share are created… hmmm…
Will have to clear it all and test it then. I’ll let you know for sure on my 4TB drives.
Okay, after the last update, the problems activating spin down went away… interesting. I set all five IronWolf drives to APM 40 and 5 min spin down and it works perfectly. The drives were then set back to no spin down and again had a small glitch. Then I got weird errors setting the drives back to no spin down and then it flat stopped working all together… Working on a video…
12/17/23 Update:
Well, had numerous updates lately and seems like all but the last 2 changed things… I will update with pictures later as time permits, but there is definitely something glitchy going on.
Okay, been busy and seems every update for the last few weeks changed what I was seeing. Then, the 5.0.6 .0 update came in and I am finally getting some repeatable and fairly consistent results.
Then I turn on the SMART stuff again and everything seems okay…until I log out.
When I log back in, it is all greyed out again as in the first picture.
These are all Seagate IronWolf drives, all 4TB, all same model.
I don’t know if this is a timing problem with the Rockstor WebUI or not. In any case, willing to try anything to help out…
Maybe CLI checks would be more consistent, don’t know. BUT, I did try the spindown stuff and it seemed to work, but the status has been screwing up all along complicating things. Even changing out a suspect drive made no difference.
Cheers!
2/14/24:
Noticed this stuff in the Rockstor log regarding trying to read status on all the IronWolf drives in the backup setup… BTW, it’s otherwise running fine… just the Disk Status is wonkers…
[14/Feb/2024 20:01:40] ERROR [smart_manager.data_collector:1010] Failed to update disk state… exception: Exception while setting access_token for url(http://127.0.0.1:8000): HTTPConnectionPool(host=‘127.0.0.1’, port=8000): Read timed out. (read timeout=2). content: None
[14/Feb/2024 20:01:42] ERROR [smart_manager.data_collector:1010] Failed to update pool state… exception: Exception while setting access_token for url(http://127.0.0.1:8000): HTTPConnectionPool(host=‘127.0.0.1’, port=8000): Read timed out. (read timeout=2). content: None
[14/Feb/2024 20:01:44] ERROR [smart_manager.data_collector:1010] Failed to update share state… exception: Exception while setting access_token for url(http://127.0.0.1:8000): HTTPConnectionPool(host=‘127.0.0.1’, port=8000): Read timed out. (read timeout=2). content: None
[14/Feb/2024 20:01:46] ERROR [smart_manager.data_collector:1010] Failed to update snapshot state… exception: Exception while setting access_token for url(http://127.0.0.1:8000): HTTPConnectionPool(host=‘127.0.0.1’, port=8000): Read timed out. (read timeout=2). content: None
I think the first error is most pertinent as regards the disk status bug…
Hello there,
my 4x 4TB Seagate Iron wolf Pro also do not show the Power value in the UI.
But using openSeaChest I could set the values and the drives are spinning down.
Thanks for the information.
./openSeaChest_PowerControl -d all --idle_a disable
./openSeaChest_PowerControl -d all --idle_b disable
./openSeaChest_PowerControl -d all --idle_c disable
./openSeaChest_PowerControl -d all --standby_z disable
It survives a reboot and powercycle
Found it here: