@phemmy22 Hello there, I just wanted to chip-in on this a little:
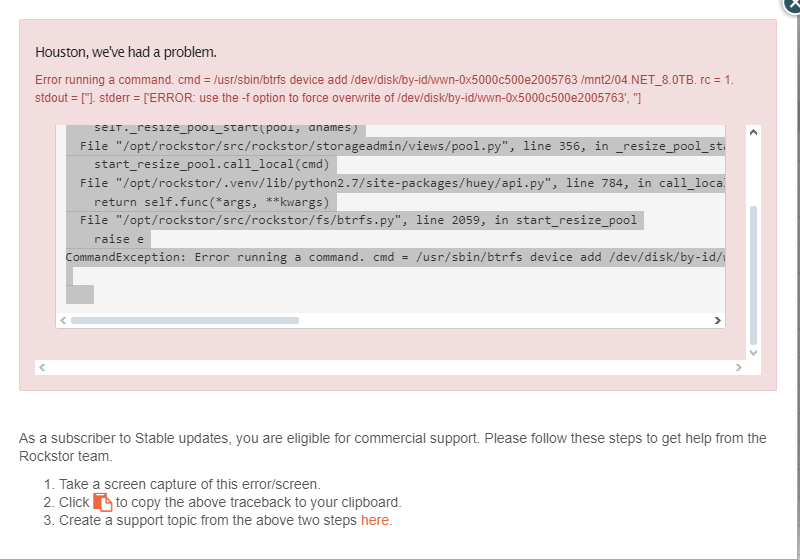
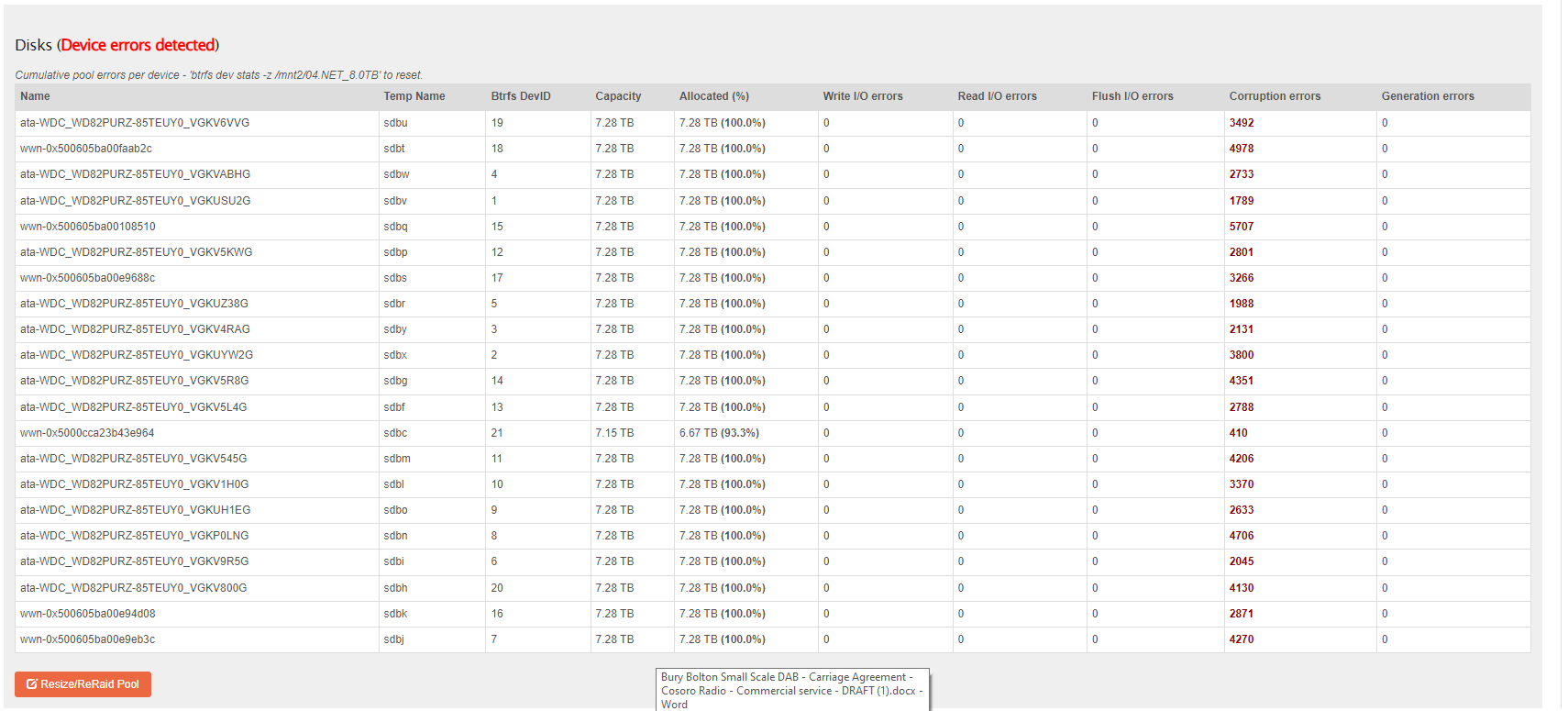
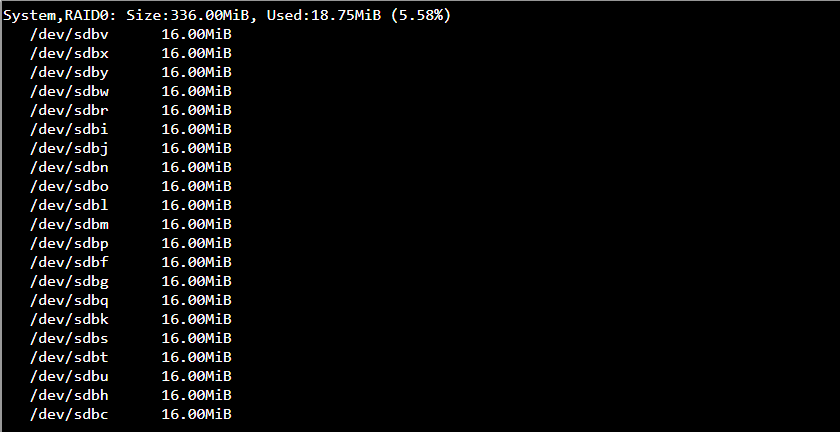
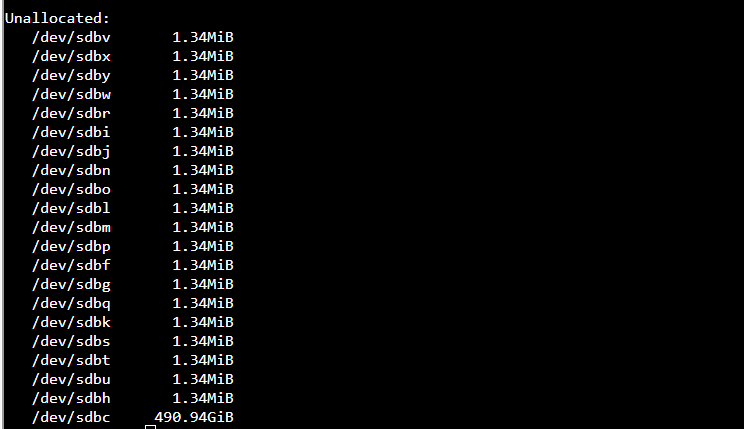
There-after the system displays errors across all drives: These errors are all corruption, not read, or write. That suggests that you have an issue higher up than the individual drives themselves. I.e: @Hooverdan 's question:
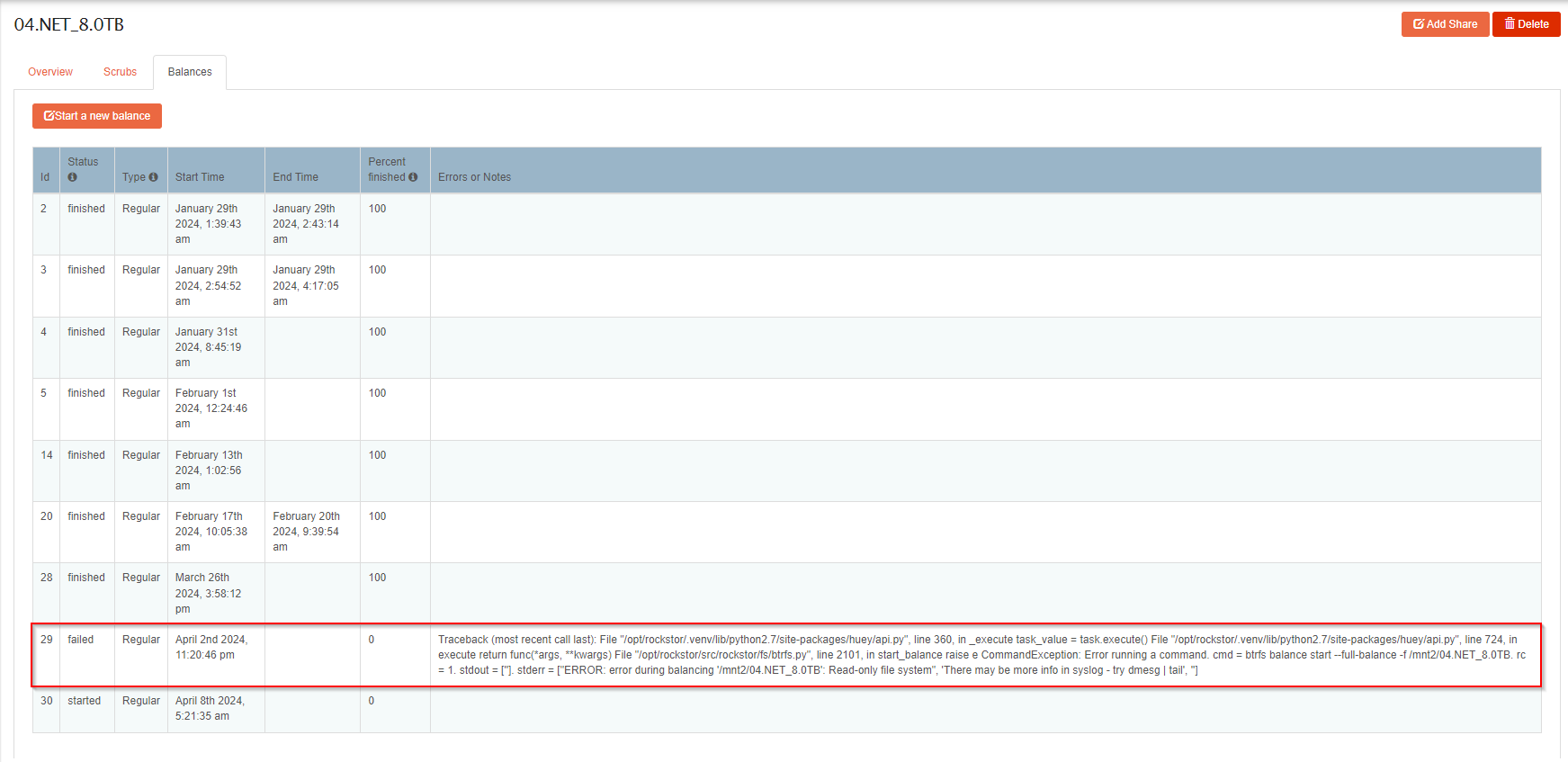
Failure in memory could given errors across all drives. If it was just the newly added drive, the errors would be confined to that drive. But they are not. Likewise the system history, from my only quick read here, was that this all started when you added the last drive. The error you noted form that time in the Web-UI balance logs by the way was due to a read-only pool status. Btrfs goes read-only to protect data integrity it if finds something iffy. Thousands of corruption errors in seconds across all pool members definitely counts as iffy. So back to that drive addition. You may have overly stretched your PSU. This then causes a system wide instability that could well cause power fluctuations that lead to corruption.
Do nothing else with the pool until you prove your memory good. Then look into your PSU capacity/health (not easy) and the massive not insubstantial load it is now under with this drive count. Our following doc may be of help on the memory test front:
Pre-Install Best Practice (PBP): Pre-Install Best Practice (PBP) — Rockstor documentation
Another cause could be a drive controller interface: but again; power instability (voltage fluctuations etc) could also show up as all sorts of hardware failure as all components need a steady power supply. Just thinking that the adding of this last drive could have been the last straw for the PSU and pushed it into failure (maybe only at that load but potentially all loads there-after).
With the system in this state: unreliable with all these across the board errors on all drives, you can do nothing with the pool: it likely is the victim here; not the cause.
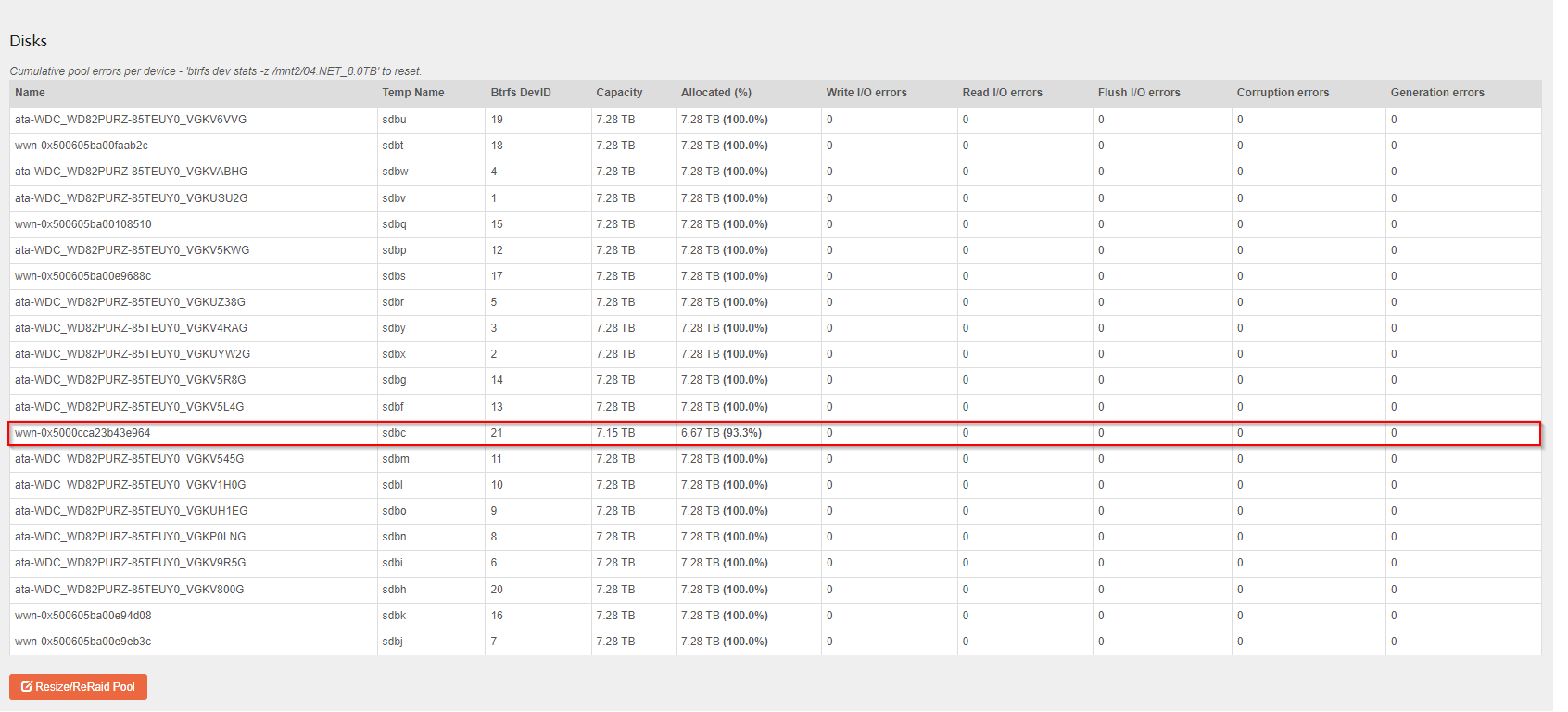
From the output no individial disk is any more suspect than any other. They are all receiving corruption reports: ergo not likely an individual disk is my initial thought here.
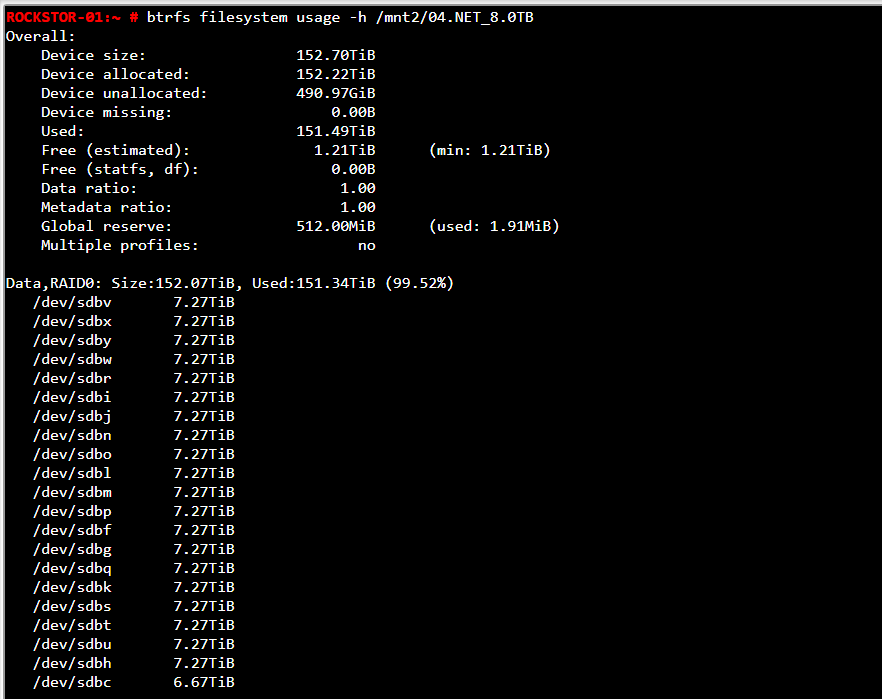
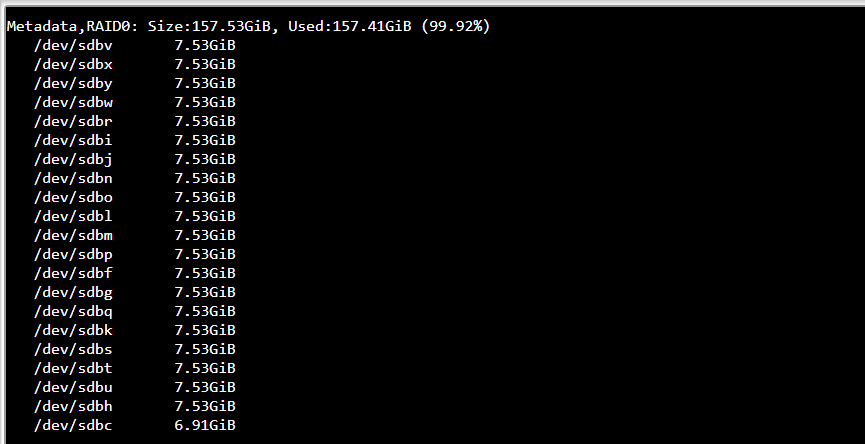
Always the hope, but btrfs-raid0, and btrfs-single for that matter have not meaningful redundancy: so are only appropriate for disposable data purposes: see our:
https://rockstor.com/docs/interface/storage/pools-btrfs.html#redundancyprofiles
But as stated earlier: you pool has gone read-only (the “ro”) in the mount status reports. That is likely as a result of the corruptions accross the board. But with no redundancy (btrfs-raid0) if there is a failure anywhere then the entire pool can be at risk. But check your memory and PSU health first as it is common place for additional load on a system to surface failure across the board.
Hope that helps,at least for some context.