Brief description of the problem
I run Rockstor 5.1.0-0 on an old Fujitsu Primergy TX150 S8, which I rebuilt specifically for this purpose.
Until recently, it had 1 SSD for Rockstor and four 6TB SATA HDDs for the Main pool, each one LUKS-encrypted and set to auto-unlock on boot. The Main pool is configured as a raid1.
A few days ago, I added a fifth disk, set up LUKS encryption and added it to the pool via the “Resize/ReRaid Pool” button/modal in the WebUI. I kept the profile as raid1 and new balance operation started.
During the balance, which took ~32h, one of the older HDDs seems to have failed completely:
- both the LUKS volume and the disk itself were marked as “detached” in the Rockstor UI
- the device file
/dev/sdbwas gone - the disk didn’t even show up as a physical disk in the output of the MegaRAID CLI command and trying to query the slot gave the same output as if there just wasn’t a disk in there, at all, and
- the orange fault indicator LED was on next to the disk’s slot in the server’s disk enclosure.
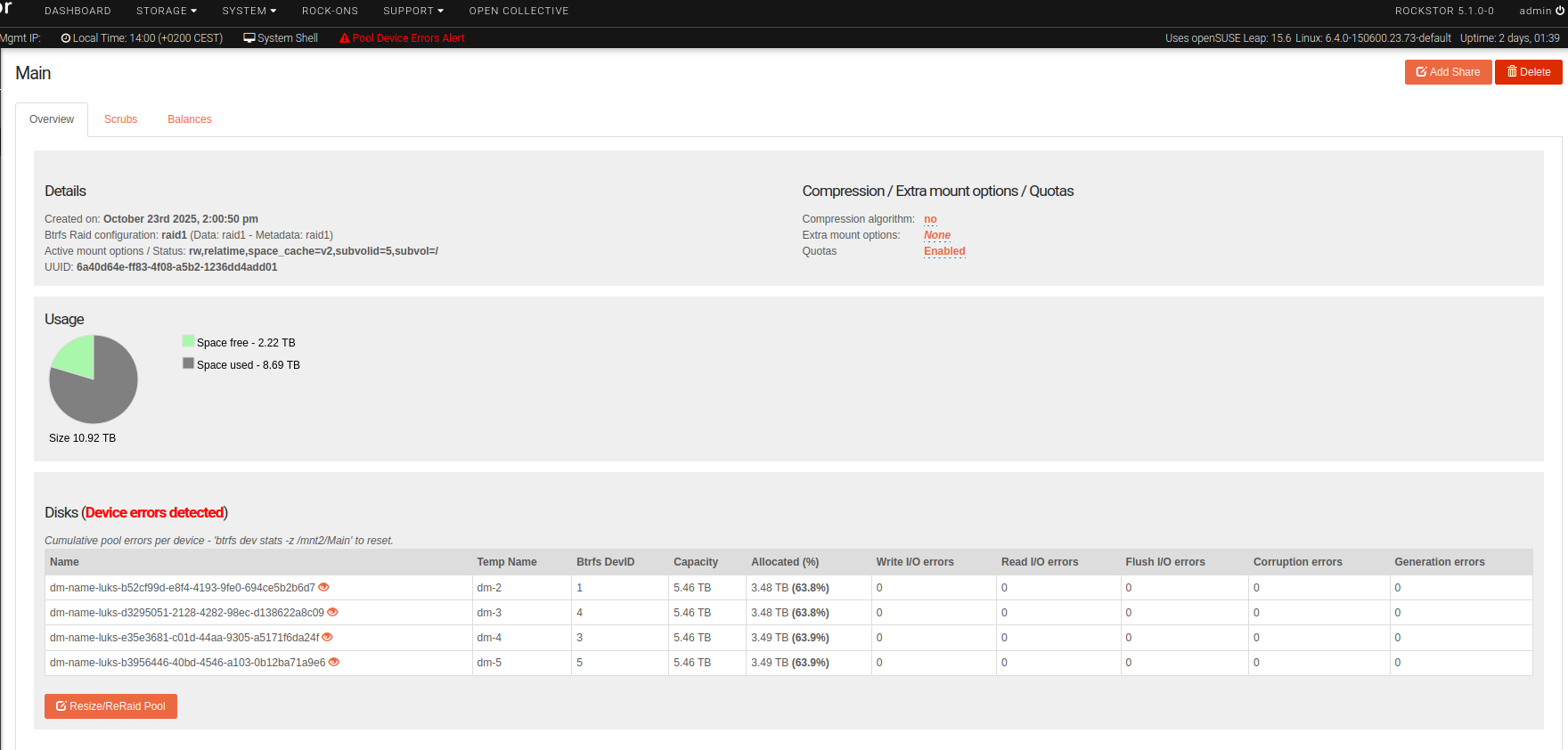
There are also some additional warning messages in the WebUI:
- a “Pool Device Errors Alert” message at the top of each page and
- “(Device errors detected)” warnings in the “Disks” sections of both the overview of all pools and the Main pool overview panel.
But here’s the puzzling thing: there were and are no detached/missing disks listed in the Main pool overview, so none can be removed, either. It only lists the four working disks.
Deleting the detached disks from the Disks page did not change this, nor did physically pulling the disk out of the enclosure.
The balance operation finished successfully and the pool now still shows four disks and no detached/missing ones, but the warnings persist.
I logged in via SSH and checked the Main pool’s filesystem with btrfs fi show /mnt2/Main. It still lists a total of five devices.
How do I proceed here?
Detailed step by step instructions to reproduce the problem
- Create a pool with a raid1 profile on top of some LUKS-encrypted disks (don’t know if there need to be four of them)
- Add another disk to the system, LUKS-encrypt and unlock it
- Add it to the pool via “Resize/ReRaid pool” button and modal, let the balance operation start
- While the balance is running, physically remove one of the old disks
You should see the removed disk and its LUKS volume listed as detached on the Disks page, but not on the pool’s overview page.
Web-UI screenshot

Error Traceback provided on the Web-UI
Only
Pool Device Errors Alert
… at the top of each page and
(Device errors detected)
… in the Disks section of both the pools overview page and the overview panel on the Main pool’s page.