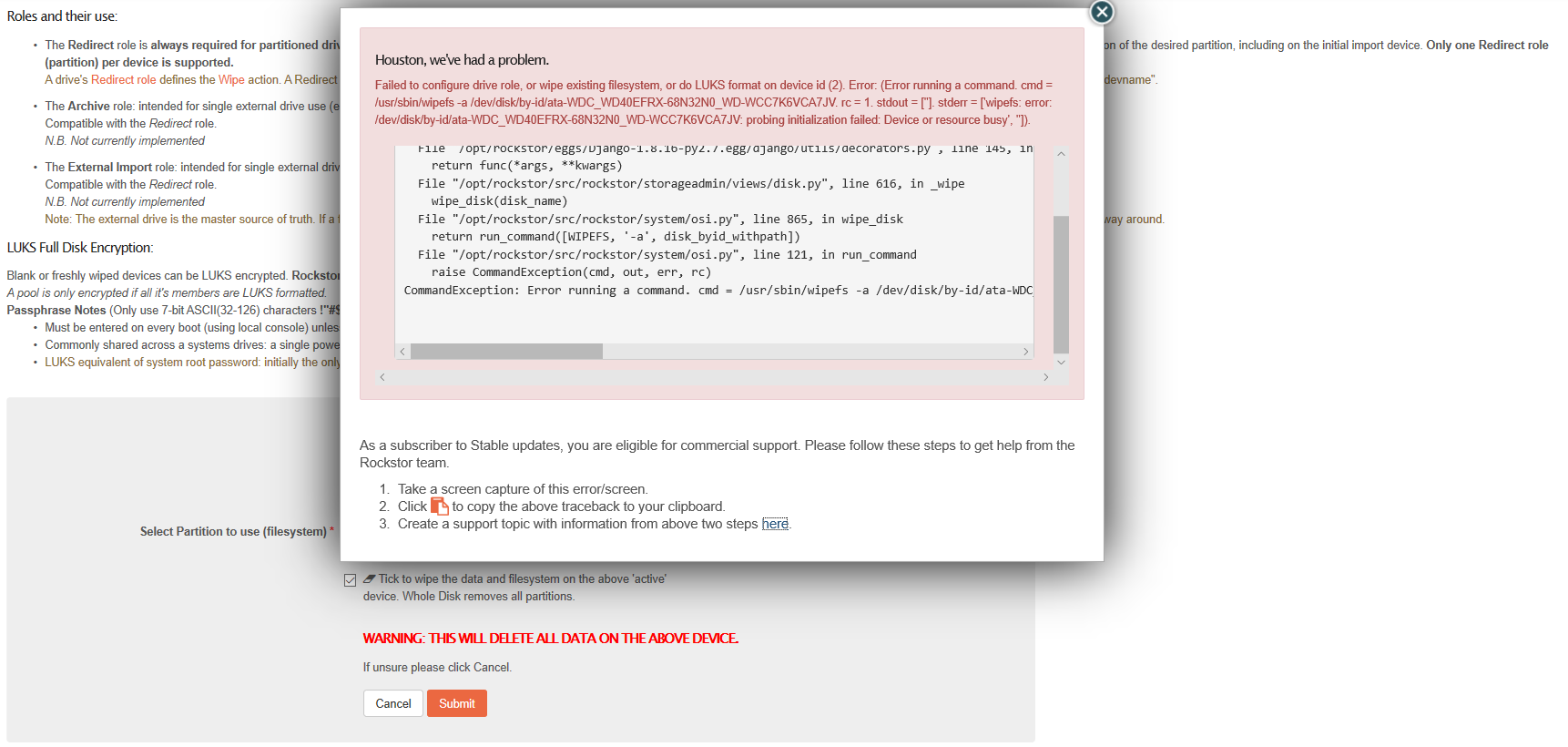
I am trying to move some drives from an old pool to another one but it looks like after deleting the old pool, if I try to wipe the drives to add them to the new pool I get the following error.
“Device or resource busy”
I have checked if one of the drives is mounted somewhere else but no. I don’t see what process could be using those drives either.
In the “disks” tab, Rockstor is still seeing the drives with BTRFS partition on them, and propose to import it.
Brief description of the problem
I want to move the drives from one pool to another, but they appear as “busy”.
Detailed step by step instructions to reproduce the problem
Deleted old pool.
Removed all scheduled tasks related to that pool.
Try to wipe the drives so I can add them to another pool not working.
Btrfs can sometimes be quite reluctant to release a drive, but in this case it may just be a Rockstor process that has not properly released it. Normally if one removes a drive from a pool it is released properly to be re-used but it may be we have an issue here when a pool is deleted.
Now that you have deleted the pool try a reboot. It may then work as intended. If so we need to look to this from our side and see if the same behaviour is still true with our openSUSE builds.
Let us know if this disk is properly released post a reboot, now that you have deleted it’s prior pool it should now be nothing to do with Rockstor as such and thus freed up ‘properly’. I strongly suspect a bug on our part with this one but let us know if the reboot does it. That will ensure it is properly released from both our side and btrfs’s side.
You already have by way of a simple reproducer. I have as a result opened the following issue:
That way when next anyone is available they can reproduce this issue and hopefully track down what’s going wrong.
Thanks for the nice clear report, much appreciated.
One more thing that would help here is a confirmation of the exact version of Rockstor that you are running. And given we had a painfull bug when moving from testing to stable, if you could double check via the output from:
yum info rockstor
Thanks for your help in clearly reporting this, I’ve seen the like of it but haven’t gotten around to a clear report but at least now we have this. Cheers.