Hi
I was running 3.8.15 in a VM. I have 4 data disks passed through (i.e. not virtualised). I upgraded to 3.9.0 and got the error below. I have since wiped the OS disk and reinstalled both 3.8.15 and 3.8.16 but still get the same error when I try to auto import pools/shares.
Error
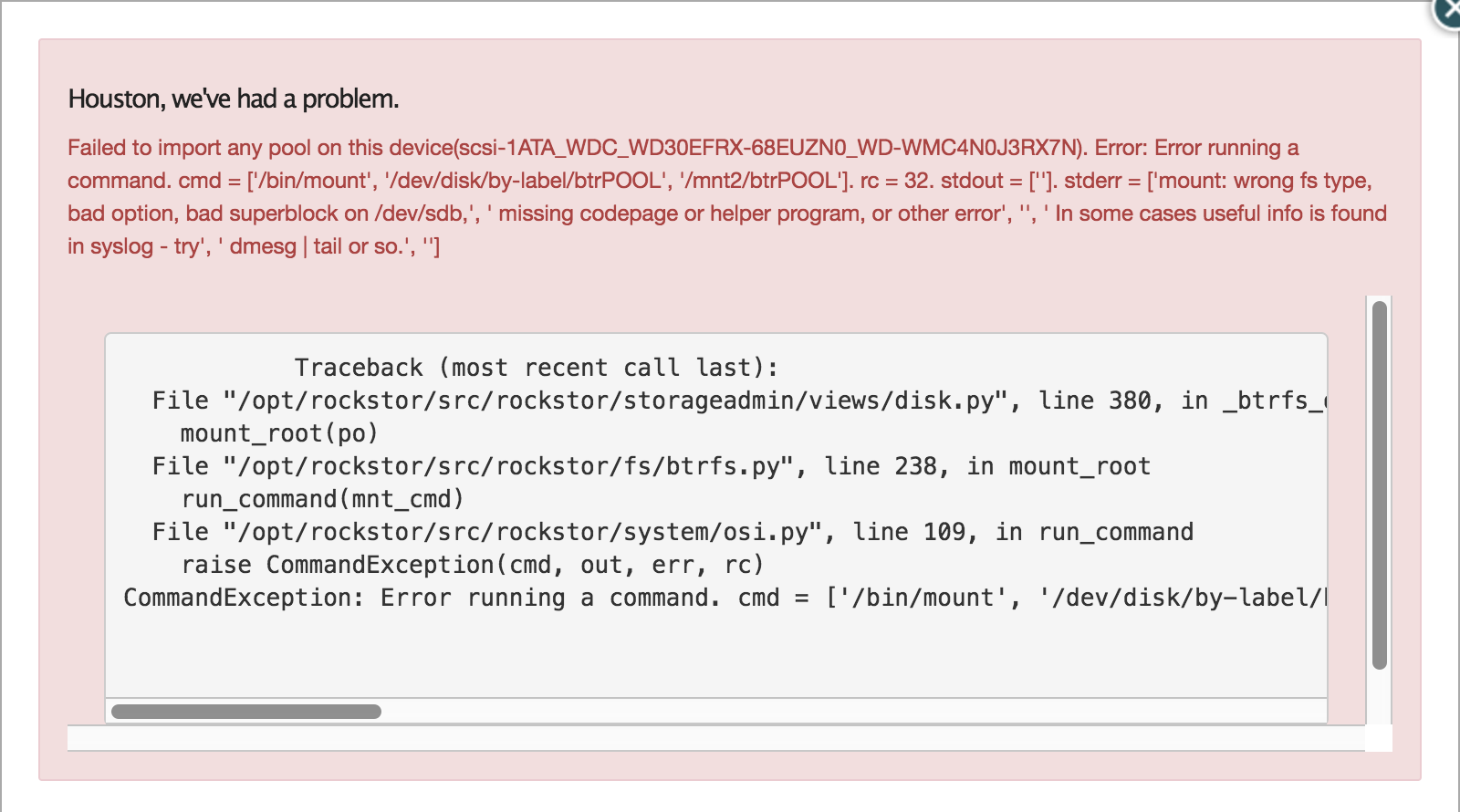
Failed to import any pool on this device(scsi-1ATA_WDC_WD30EFRX-68EUZN0_WD-WCC4N0PYDZT7). Error: Error running a command. cmd = [‘/bin/mount’, ‘/dev/disk/by-label/btrPOOL’, ‘/mnt2/btrPOOL’]. rc = 32. stdout = [‘’]. stderr = [‘mount: wrong fs type, bad option, bad superblock on /dev/sdb,’, ’ missing codepage or helper program, or other error’, ‘’, ’ In some cases useful info is found in syslog - try’, ’ dmesg | tail or so.', ‘’]
Web-UI screenshot
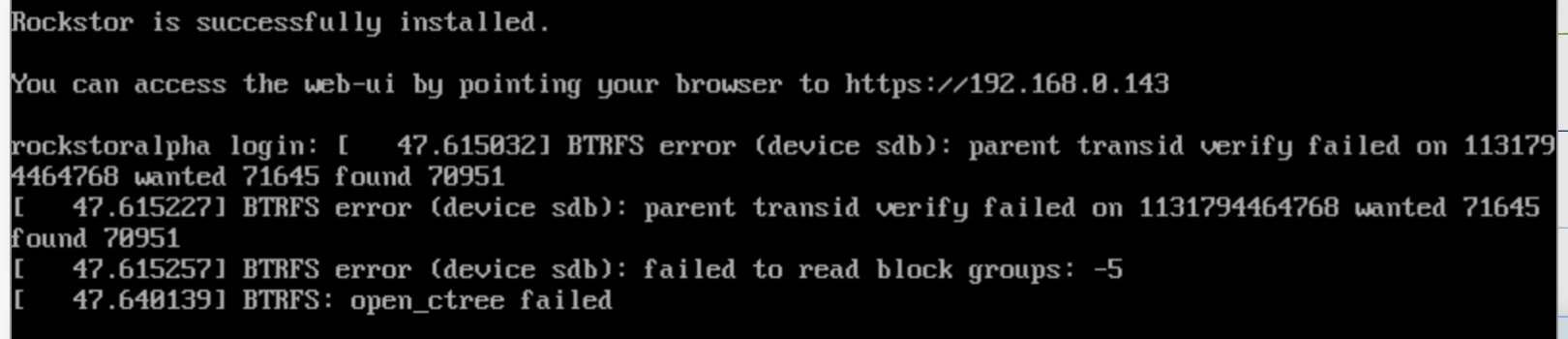
…and in the console:
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 380, in _btrfs_disk_import
mount_root(po)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 236, in mount_root
run_command(mnt_cmd)
File "/opt/rockstor/src/rockstor/system/osi.py", line 104, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = ['/bin/mount', '/dev/disk/by-label/btrPOOL', '/mnt2/btrPOOL']. rc = 32. stdout = ['']. stderr = ['mount: wrong fs type, bad option, bad superblock on /dev/sdb,', ' missing codepage or helper program, or other error', '', ' In some cases useful info is found in syslog - try', ' dmesg | tail or so.', '']
###Also
Via SSH I tried:
mount -o rw,degraded,recovery /dev/sdb /mnt2/Files
…but got:
mount: mount point /mnt2/Files does not exist
The I tried:
mount -o rw,degraded,recovery, /dev/sdb /mnt2/
…but got (what I guess is the original error):
mount: wrong fs type, bad option, bad superblock on /dev/sdb,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so.
So then I remembered that I had the noatime and autodefrag options on the pool, so I tried:
mount -o rw,degraded,recovery,noatime,autodefrag /dev/sdb /mnt2/
…but got the same:
mount: wrong fs type, bad option, bad superblock on /dev/sdb,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so.
###Any ideas
Does anyone have any ideas on how to recover my pool / data?