Brief description of the problem
I can no longer start my SFTP service after disabling it from the web UI and replaced 1 drive of a 7 drive RAID 1 pool. Drive replacement was done to increase pool size.
Detailed step by step instructions to reproduce the problem
- Disabled SFTP service.
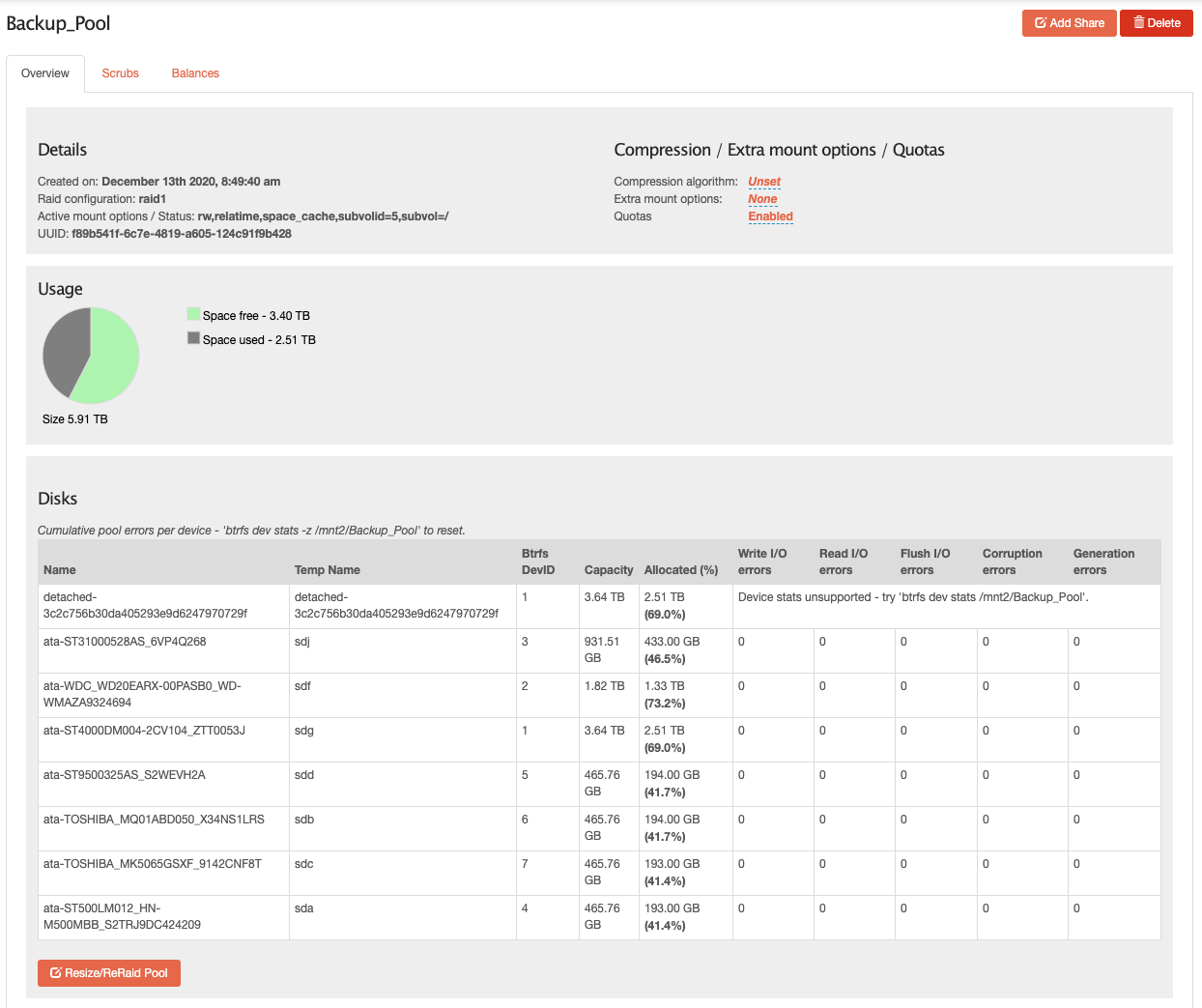
- Replaced drive with procedure documented here:
Data Loss-prevention and Recovery in Rockstor — Rockstor documentation - Ran a balance on the pool.
- Disabled pool quota during the balance as I noticed the balance was running very slowly.
- Re-enabled pool quota aftr balance had completed.
- Tried to restart the SFTP server from the web UI.
Web-UI screenshot
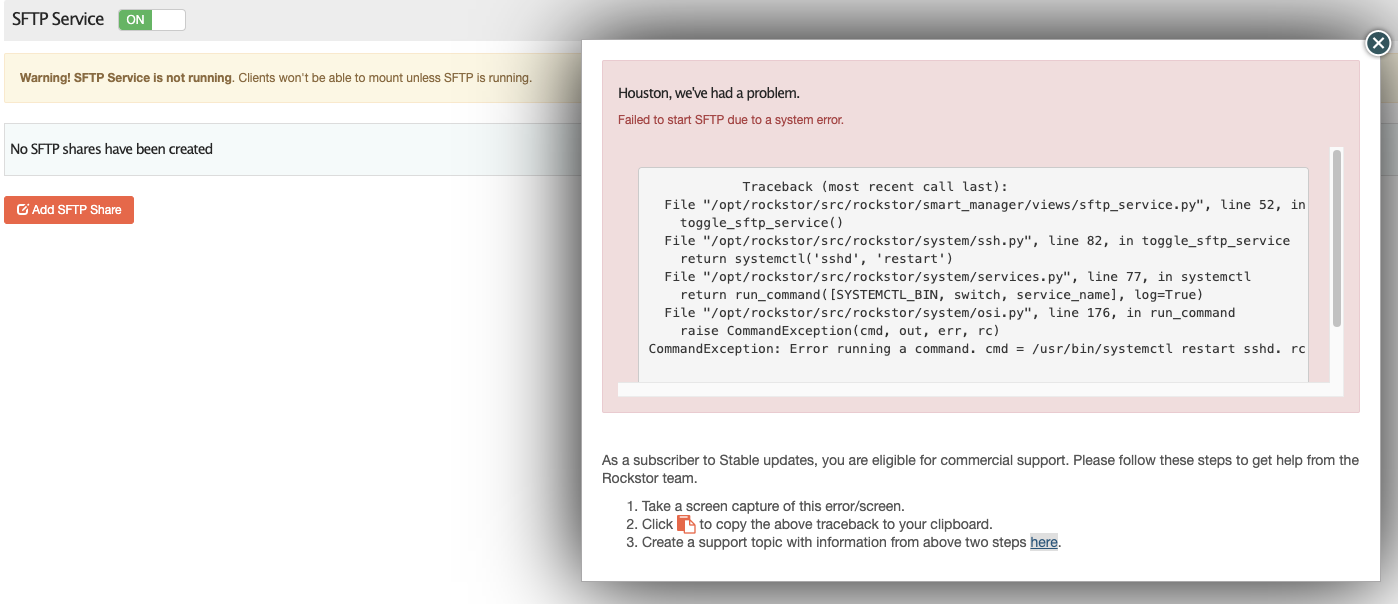
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/smart_manager/views/sftp_service.py", line 52, in post
toggle_sftp_service()
File "/opt/rockstor/src/rockstor/system/ssh.py", line 82, in toggle_sftp_service
return systemctl('sshd', 'restart')
File "/opt/rockstor/src/rockstor/system/services.py", line 77, in systemctl
return run_command([SYSTEMCTL_BIN, switch, service_name], log=True)
File "/opt/rockstor/src/rockstor/system/osi.py", line 176, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/bin/systemctl restart sshd. rc = 1. stdout = ['']. stderr = ['Job for sshd.service failed because the control process exited with error code. See "systemctl status sshd.service" and "journalctl -xe" for details.', '']
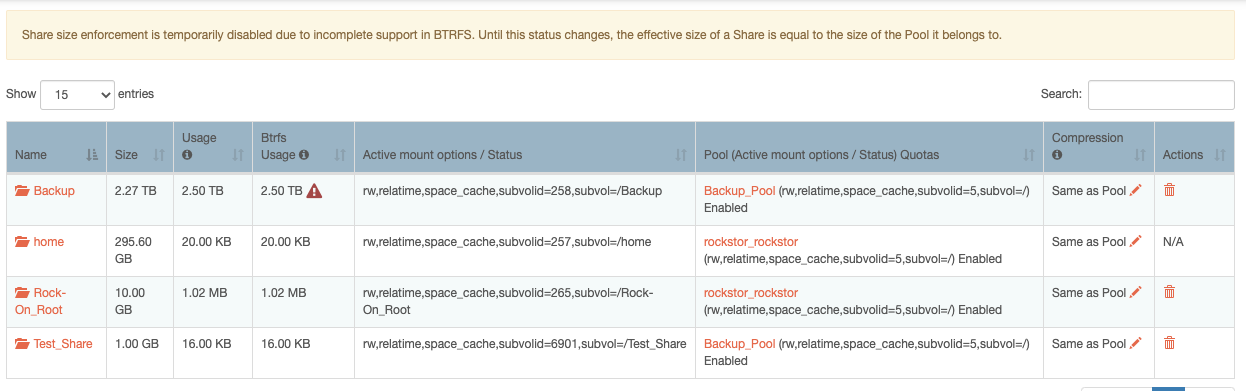
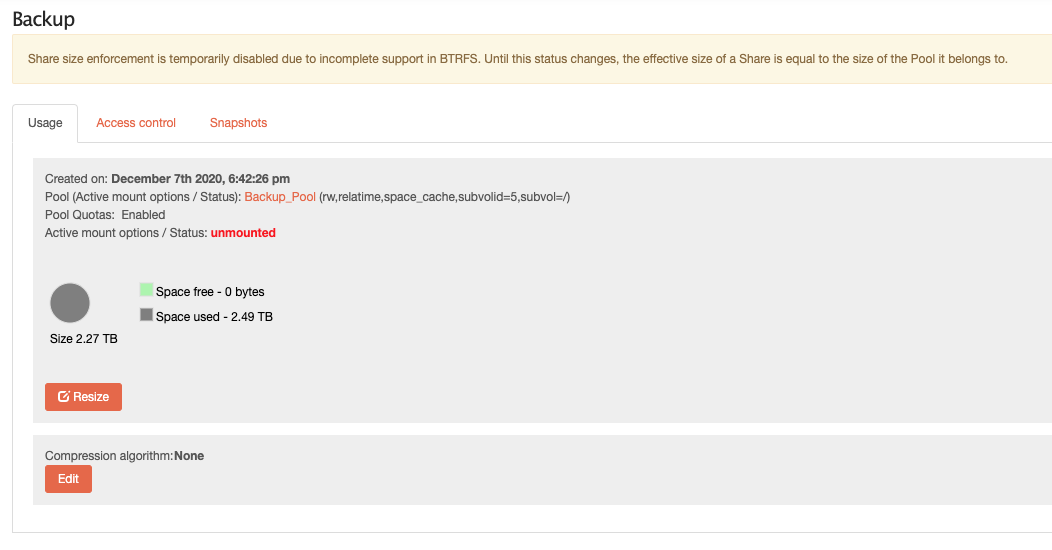
Note: the “Backup” share that I previously served with SFTP now shows as unmounted and with the previous size:
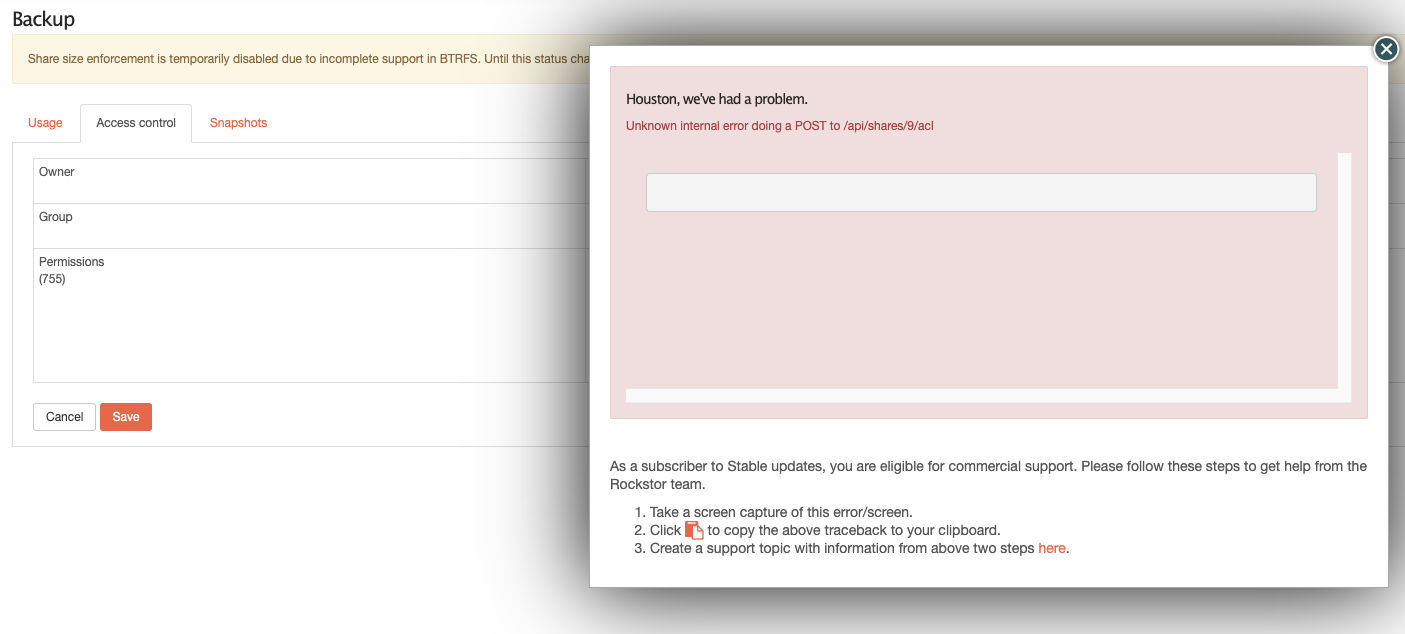
Trying to change the share’s size also shows an error:
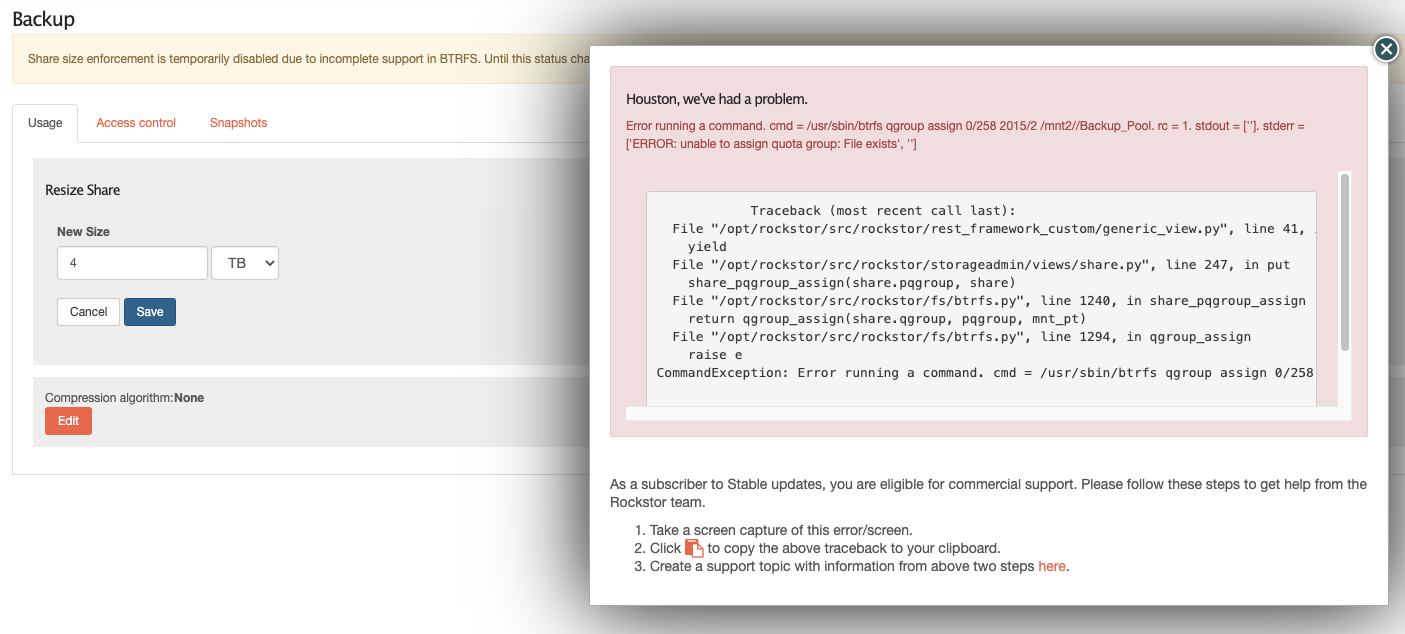
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/share.py”, line 247, in put
share_pqgroup_assign(share.pqgroup, share)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 1240, in share_pqgroup_assign
return qgroup_assign(share.qgroup, pqgroup, mnt_pt)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 1294, in qgroup_assign
raise e
CommandException: Error running a command. cmd = /usr/sbin/btrfs qgroup assign 0/258 2015/2 /mnt2//Backup_Pool. rc = 1. stdout = [‘’]. stderr = [‘ERROR: unable to assign quota group: File exists’, ‘’]