So first version should be latest testing
# zypper info rockstor
Loading repository data...
Reading installed packages...
Information for package rockstor:
---------------------------------
Repository : Rockstor-Testing
Name : rockstor
Version : 4.0.7-0
Arch : x86_64
Vendor : YewTreeApps
Installed Size : 74.4 MiB
Installed : Yes
Status : up-to-date
Source package : rockstor-4.0.7-0.src
Summary : Btrfs Network Attached Storage (NAS) Appliance.
Description :
Software raid, snapshot capable NAS solution with built-in file integrity protection.
Allows for file sharing between network attached devices.
btrfs fi shows following
# btrfs fi show
Label: 'ROOT' uuid: 87514575-45ec-478d-b433-0f0b96ff504e
Total devices 1 FS bytes used 2.51GiB
devid 1 size 109.75GiB used 2.80GiB path /dev/sda4
Label: '2f84e287-4c6a-4750-981e-b19e4db8b16f' uuid: 2f84e287-4c6a-4750-981e-b19e4db8b16f
Total devices 1 FS bytes used 1.36TiB
devid 1 size 2.73TiB used 1.36TiB path /dev/sdc
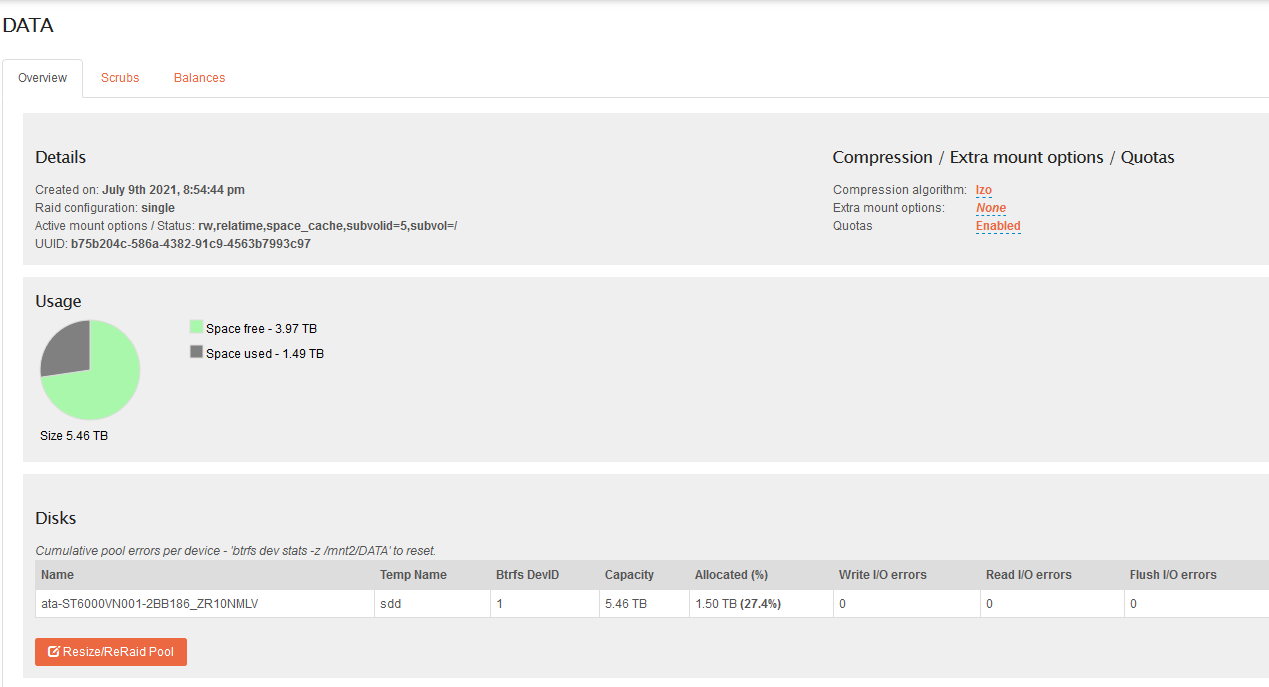
Label: 'DATA' uuid: b75b204c-586a-4382-91c9-4563b7993c97
Total devices 1 FS bytes used 1.49TiB
devid 1 size 5.46TiB used 1.50TiB path /dev/sdd
Explanation:
2f84e287-4c6a-4750-981e-b19e4db8b16f is original pool which i had before I have installed rockstor. After I installed rockstor and realized that my pools on multiple partition is not how rockstor is supposed to be used, I made pool 2f84e287-4c6a-4750-981e-b19e4db8b16f from raid1 to single, then I removed 6tb drive, so now there is only 3tb drive left in 2f84e287-4c6a-4750-981e-b19e4db8b16f in single mode.
DATA is new pool created from scratch in rockstor. I made that pool from newly purchased 6hdd, my plan was to create new DATA pool, than make 2f84e287-4c6a-4750-981e-b19e4db8b16f from raid1 → single to release old 6tb drive, than add this drive to DATA pool and also change it to raid1. Currently old drive is not used in any pool, it is wiped but it shows only half of capacity.
# fdisk -l
Disk /dev/sda: 111.8 GiB, 120034123776 bytes, 234441648 sectors
Disk model: KINGSTON SA400S3
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 64536473-33FC-4B32-B87C-49ABD98E7BB7
Device Start End Sectors Size Type
/dev/sda1 2048 6143 4096 2M BIOS boot
/dev/sda2 6144 73727 67584 33M EFI System
/dev/sda3 73728 4268031 4194304 2G Linux swap
/dev/sda4 4268032 234441614 230173583 109.8G Linux filesystem
Disk /dev/sdb: 5.5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFRX-68L
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sdc: 2.7 TiB, 3000592982016 bytes, 5860533168 sectors
Disk model: TOSHIBA DT01ACA3
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sdd: 5.5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: ST6000VN001-2BB1
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
This is planned to be 2x 6tb pool ( currently it is single with single 6tb)
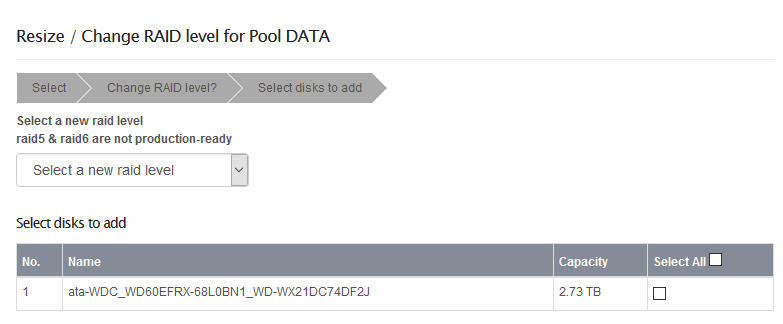
When I tried to add addtional old 6tb hdd it looks like this
Only 2.73TB…
I was worry to add it to pool like this as i was unsure about result, I would like to avoid necessary btrfs balancing, which as i read is done automatically after resize opetation in rockstor.
Can I extend DATA pool and make raid1 from command line? or it will confuse rockstor.
Is there any chance to delete that drive from database?
I find this in manual https://rockstor.com/docs/disks.html#detached-disks
According this if disk is not used, I should be able to delete it, there should be trash icon. But I dont have this icon, I triied to removed hdd physicaly from server. I was hoped that maybe after it would be deleted completely from database it could be used again in full capacity:)
Last option for me ( maybe the best ) is just to reinstall rockstor. I did not to too much configuration yet, it would be definitely faster then waiting for re-balancing 1.5tb data again.
PS: I like forum UI a lot, now I understand why you are not so active on reddit.
Thank you for help and warm welcome.