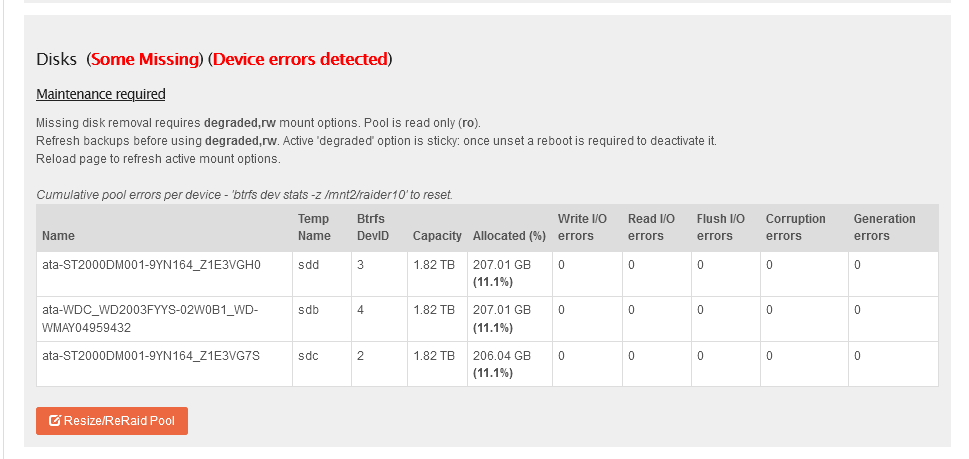
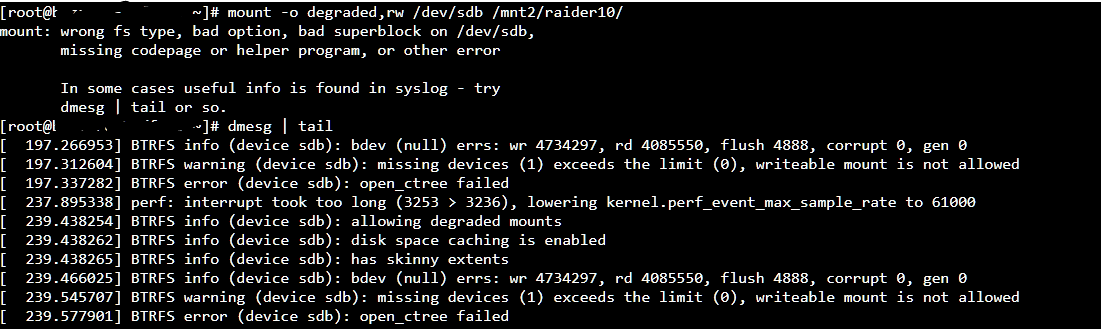
Brief description of the problem
I have a drive that failed in a 4 disk RAID10 pool. I have been following the Data Lossa Raid 1 documentation without any luck. The drive is completely dead so it doesn’t register as a device anymore. I mount the pool and run the replace:
btrfs replace start 1 /dev/sdf /mnt2/raider10
But when i look at the status it says ‘Never started’. It won’t let me mount the pool as RW, an error is thrown
Detailed step by step instructions to reproduce the problem
fdisk -l
Disk /dev/sda: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: dos
Disk identifier: 0x00017bcd
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 1026047 512000 83 Linux
/dev/sda2 1026048 5222399 2098176 82 Linux swap / Solaris
/dev/sda3 5222400 1953523711 974150656 83 Linux
Disk /dev/sdb: 2000.4 GB, 2000398934016 bytes, 3907029168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sdc: 2000.4 GB, 2000398934016 bytes, 3907029168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sdd: 2000.4 GB, 2000398934016 bytes, 3907029168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sde: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sdf: 3000.6 GB, 3000592982016 bytes, 5860533168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
btrfs fi show
Label: 'rockstor_rockstor' uuid: 9a41126b-4153-42d4-b106-ff205d2f260e
Total devices 1 FS bytes used 2.47GiB
devid 1 size 929.02GiB used 5.04GiB path /dev/sda3
Label: 'raider10' uuid: 182033a2-cad6-4a4f-aece-1a8ddf038736
Total devices 4 FS bytes used 407.76GiB
devid 2 size 1.82TiB used 206.04GiB path /dev/sdc
devid 3 size 1.82TiB used 207.01GiB path /dev/sdd
devid 4 size 1.82TiB used 207.01GiB path /dev/sdb
*** Some devices missing