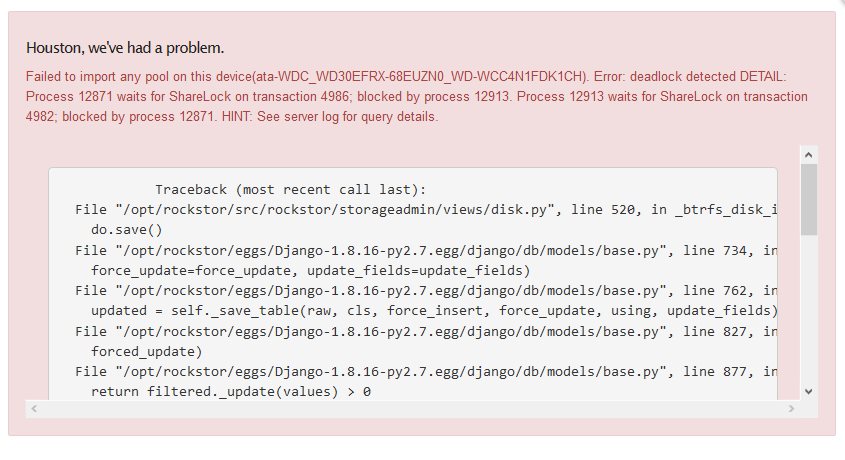
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 520, in _btrfs_disk_import
do.save()
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/base.py", line 734, in save
force_update=force_update, update_fields=update_fields)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/base.py", line 762, in save_base
updated = self._save_table(raw, cls, force_insert, force_update, using, update_fields)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/base.py", line 827, in _save_table
forced_update)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/base.py", line 877, in _do_update
return filtered._update(values) > 0
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/query.py", line 580, in _update
return query.get_compiler(self.db).execute_sql(CURSOR)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/sql/compiler.py", line 1062, in execute_sql
cursor = super(SQLUpdateCompiler, self).execute_sql(result_type)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/sql/compiler.py", line 840, in execute_sql
cursor.execute(sql, params)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/backends/utils.py", line 64, in execute
return self.cursor.execute(sql, params)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/utils.py", line 98, in __exit__
six.reraise(dj_exc_type, dj_exc_value, traceback)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/backends/utils.py", line 64, in execute
return self.cursor.execute(sql, params)
OperationalError: deadlock detected
DETAIL: Process 12871 waits for ShareLock on transaction 4986; blocked by process 12913.
Process 12913 waits for ShareLock on transaction 4982; blocked by process 12871.
HINT: See server log for query details.
@lightglitch Thanks for the report and well done on the work around. Of late I’ve mainly been working on disk management but I hope soon to look more to the pool side of things. So for the time being at least this one is more in @suman land.
As for the mount_root(po) where po = pool object: it does look a little suspect.
Just had quite a journey tracking down that mechanisms history and it seems it’s always been that way, ie from when the import mechanism was first added:
so the mount_root(pool_object) looks to have always been inside that loop.
From a quick look it appears that the mount is attempted sequentially via each disk. I know in the earlier days of btrfs it was sometimes required to specify all disks in a pool, so not sure if this was an attempt to do that but ended up being a sequential pool mount by every disk member; which is most likely not what was intended anyway.
EDIT: So had another quick think and given the mount_root(po) function mounts by label (see below) then given the current use of this call within the loop simply repeats the exact same request of mounting by label for the discovered number of devices in the pool being imported (assuming no fail over to by dev): odd!
All subsequent changes have left it as is by the looks of it.
However in mount_root(pool) in src/btrfs.py we have:
Which would indicate that it simply returns directly upon is_share_mounted(pool.name) anyway so looks like it was by design. However, at a much later date the mount_root was enhanced to itself try each drive in turn upon an initial failure to mount by label so we may have a situation where initially the import tired each disk in turn but that this is now redundant given the more recent enhancements in mount_root to do the same(added in the following pr):
And although there have been more changes since then it does now look like mount_root will do the same as what was originally done only by _btrfs_disk_import.
In which case this is a very nice find.
Do you care to look into proving this, there has recently been enhancements to mount_root logging which should help to see what’s going on in a fail over from label mount situation.
With the above caveats it does look like this element is worth looking into further. Please see the Developers section of the Contributing to Rockstor - Overview if you fancy taking this one on.
Chuffed that you got your import sorted and looks like you might be onto something. Please consider opening an issue and consequent pull request if you have the time to look further into this as I was only able to take a little peak as detailed above.
Hope this is enough to encourage you to look further at this potential legacy/redundant code issue. Plus it would be an awesome single character fix. But again I’ve only had a quick look and if I were to tackle this one I’d start by adding additional logging and attempting multiple imports of multi disk pools to prove the function. I suspect your suspicions are correct however and hope that the above historical context will help with your efforts.
Of course I may have this all wrong, hence the proof and explanation associated with issues and pull requests.
Thanks again for taking such a constructive and critical look at this code and well done for persevering (although I think the @transaction.atomic is probably required and it’s removal covered up the real problem, which you may have uncovered anyway).
Let us know if you want to take this one on?
EDIT: Sorry for edits folks, I’m better when I focus on a single issue but this one looked like a nice find so wanted to chip in and encourage where I could.