[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
Getting the error below everywhere I go, mostly with the actual UI below it, except for the pool properties which aren’t loading at all.
Detailed step by step instructions to reproduce the problem
Started after a scrub, reproducable on my system on essentially every page of the web UI
Web-UI screenshot
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py", line 41, in _handle_exception
yield
File "/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py", line 46, in get_queryset
self._scrub_status(pool)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/utils/decorators.py", line 145, in inner
return func(*args, **kwargs)
File "/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py", line 65, in _scrub_status
PoolScrub.objects.filter(id=ps.id).update(**cur_status)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/query.py", line 563, in update
rows = query.get_compiler(self.db).execute_sql(CURSOR)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/sql/compiler.py", line 1062, in execute_sql
cursor = super(SQLUpdateCompiler, self).execute_sql(result_type)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/sql/compiler.py", line 840, in execute_sql
cursor.execute(sql, params)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/backends/utils.py", line 64, in execute
return self.cursor.execute(sql, params)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/utils.py", line 98, in __exit__
six.reraise(dj_exc_type, dj_exc_value, traceback)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/backends/utils.py", line 64, in execute
return self.cursor.execute(sql, params)
DataError: integer out of range
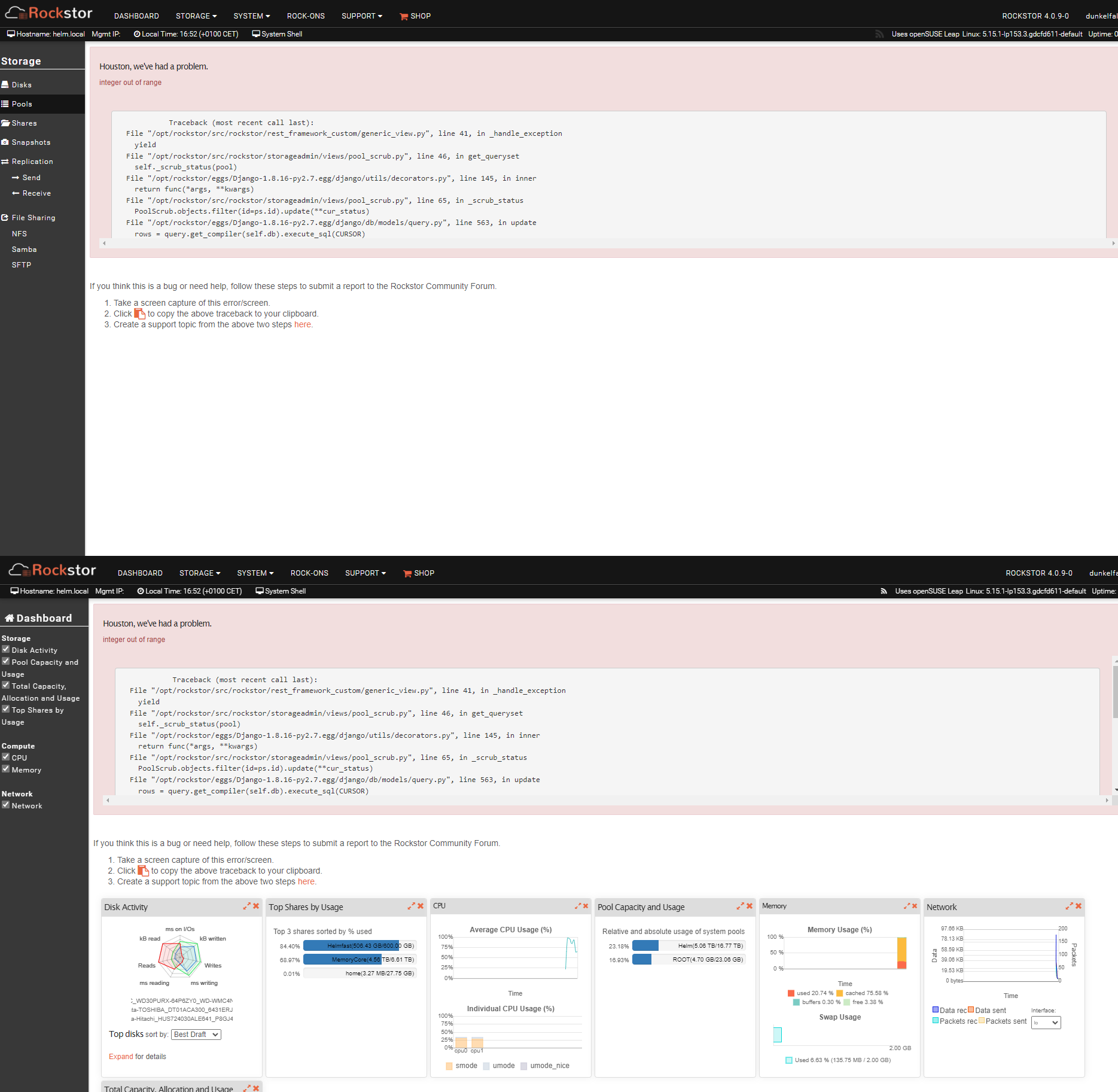
 I just went down a rabbithole …
I just went down a rabbithole …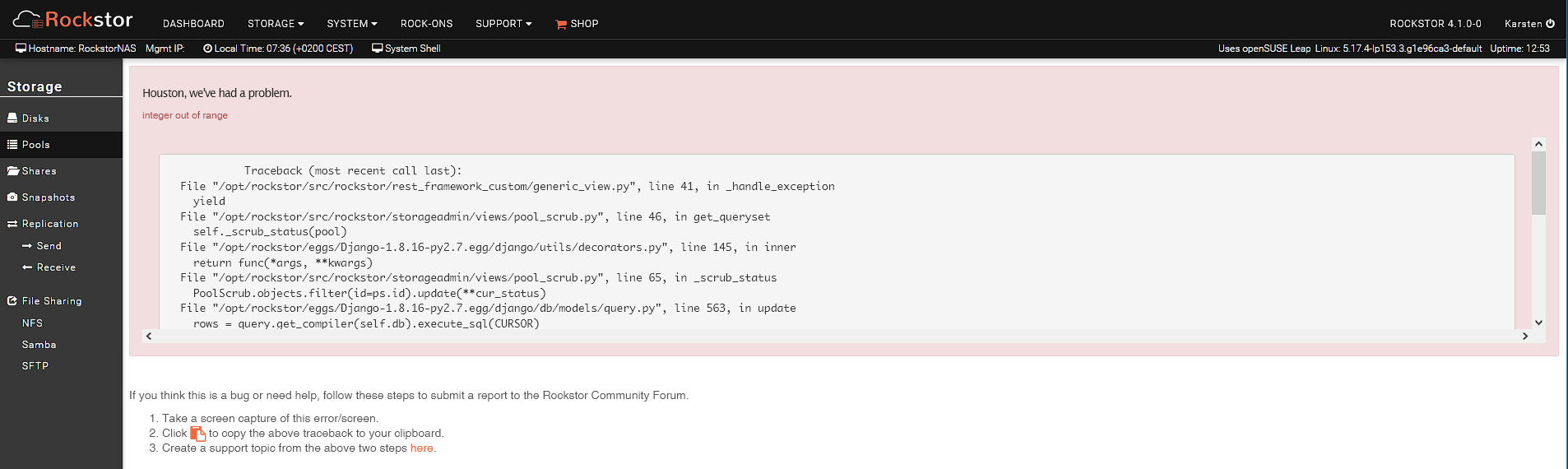
{kind=link}