[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
Problem with write acces after windows restore
Detailed step by step instructions to reproduce the problem
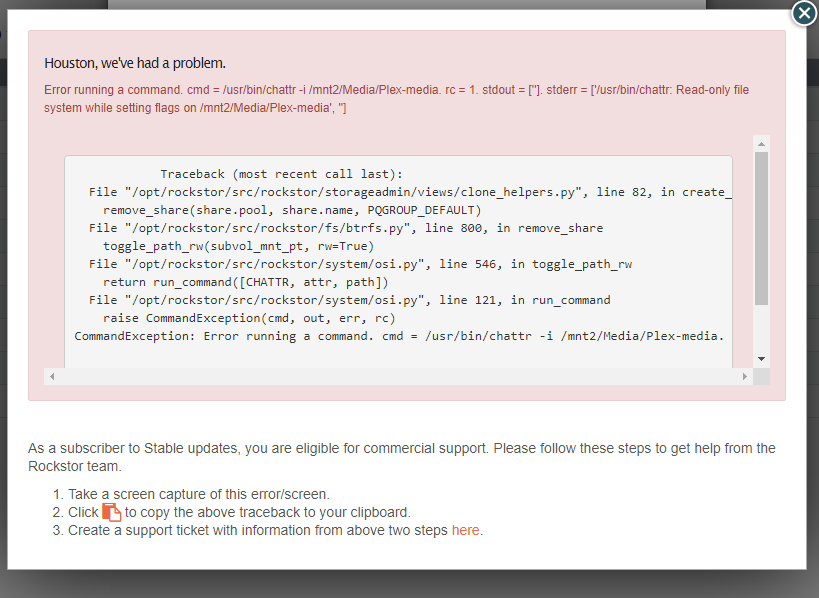
I lost my write acces to my shared folder from my Rockstor operated unit. This has worked fine for a long time, but when trying now, i do not have acces. I have tried to delete the samba share without any help. Tried now to go back to a previous snapshot and got the following message. It seems like the whole share (Plex-Media) has write protection. How to gain acces to this again?
It may just be that the pool concerned is poorly. Btrfs will turn a pool read only if it finds issues to protect the existing date. I you pool is in deed read only across all it’s contents then you might want to look to refreshing backups and seeing if it can be repaired or if a re-create and re-populate is required.
If the pool is in fact read only due to errors found then it’s not really a Rockstor specific issue, but a btrfs one. and the:
does make it look that way.
In which case you are best to lookup generic btrfs repair scenarios. but refresh your backups first.
But note that when you say ‘whole installation’ there are typically 2 pools on a system. The system pool and the data pool. Although folks often have more than one data pool. I’m assuming only your data pool has gone read only.
What is the output of:
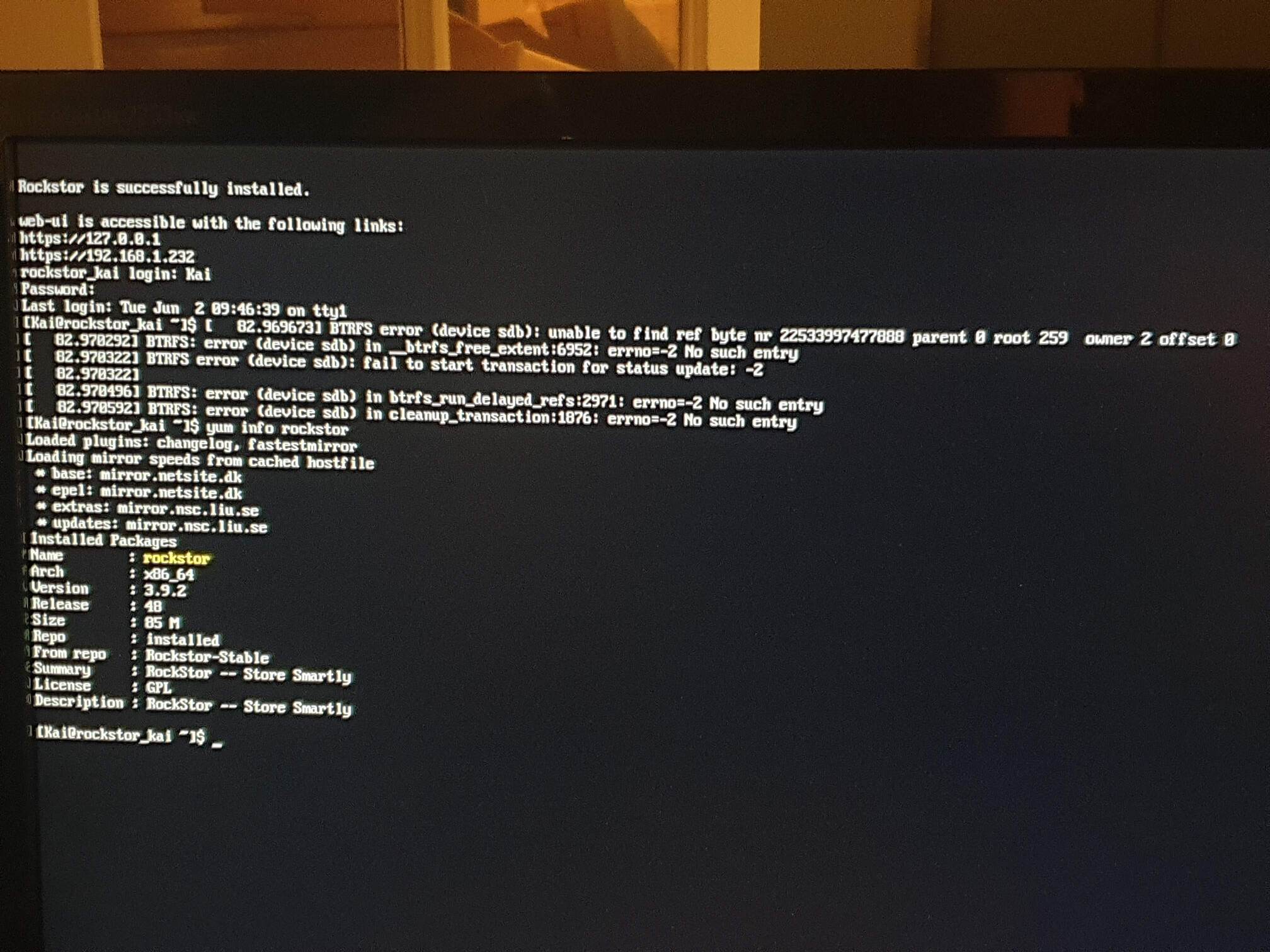
yum info rockstor
Our prior, now old, CentOS based testing channel has very little in the way of pool health feedback within the Web-UI. Our current Stable channel offering of source builds have a lot more info within the Web-UI on pool health.
I primairly use this as a plex server so sadly my knownledge of this should have been better. Either way it seems like you are correct with regards to the write only applicable for my media share. However i seem to have problems going back to my stable updates after changing to testing updates just to verify i could change it. I will ask that in another tread to make this not to messy.
Normally, in our now legacy CentOS variants, the testing channel can be selected with no effect as it’s more than 2 years older than Stable. So selecting testing after having been on Stable in the interim is likely to not do anything. Plus it looks like currently have a Stable release version 3.9.2-48 installed. There are many more updates available and you can hopefully get those once we sort:
Your stable subscriptions updates out. Best just PM me on the forum with your current Appliance ID and activation code and I’ll look into it. But don’t post these in the public part of the forum.
As to repairing your pool, that is, I’m afraid, a generic issue that you can find more expert help with elsewhere, ie btrfs specific forums. We use the filesystem extensively but are less qualified to help than many more solely btrfs focused forums / irc rooms. It may be someone can step up here to help but I’m afraid I can’t myself currently. But that message is definitely an indicator, as you suspected, that you pool is poorly.
It would help folks to know the arrangement of your btrfs and so the output from the following would help:
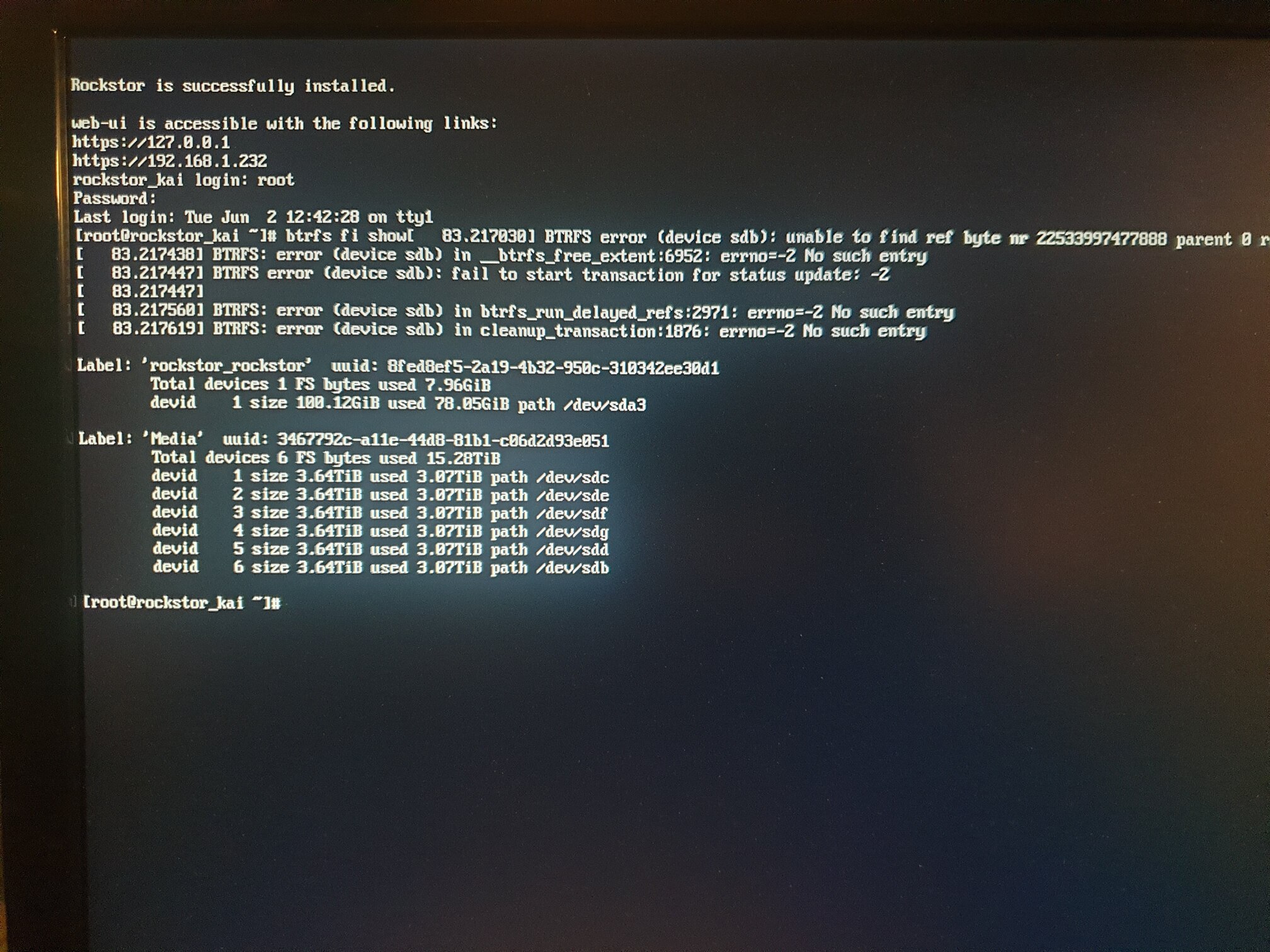
btrfs fi show
which is short for “btrfs filesystem show”. It will given an overview of all known pools. That way folks can see if you have pools with many drives or not etc.
Sorry to not be of more help here, but I can hopefully get you system further upgraded once you contact me. That way the Web-UI of rockstor may be able to tell you more of the pool health. Especially if you have multiple drives as it may be you then have a failed drive which is causing this and a repair may then be more likely as if you chose a btrfs raid level that has redundancy there may be a greater chance that another copy of the ‘broken’ bit is retrievable.
I have tried some comments, but no luck yet. My Media pool consist of 6 discs in a raid 5. I am not worried about loosing some of it, just not all Seems like there is a problem with the disc named sdb when i am starting up. I have attached both photos. If anybody know how to proceed please just speak up
The parity versions of btrfs, ie btrfs raid 5 and 6, are known not to be particularly good in repair scenarios. They are much younger than the non parity variants. But do give more space of course.
In which case I would advise, given you seem to currently have at least read only access, that you update you backups fist before trying anything else. Especially given you could make things worse in trying to repair them. The fact that btrfs has gone read only suggests that it was not able to ‘fix’ things itself, although this is weak in the parity raid levels, hence the grab what you need while you can still see it, even if only in read only mode.
Also the indication of drive in those error messages is not necessarily the actual drive concerned; it may just be the current handle btrfs is using. One can often address a pool my any of it’s current members. But the following command may be of more use to see if you have a drive that has partially failed and lead, in part, to your current problems:
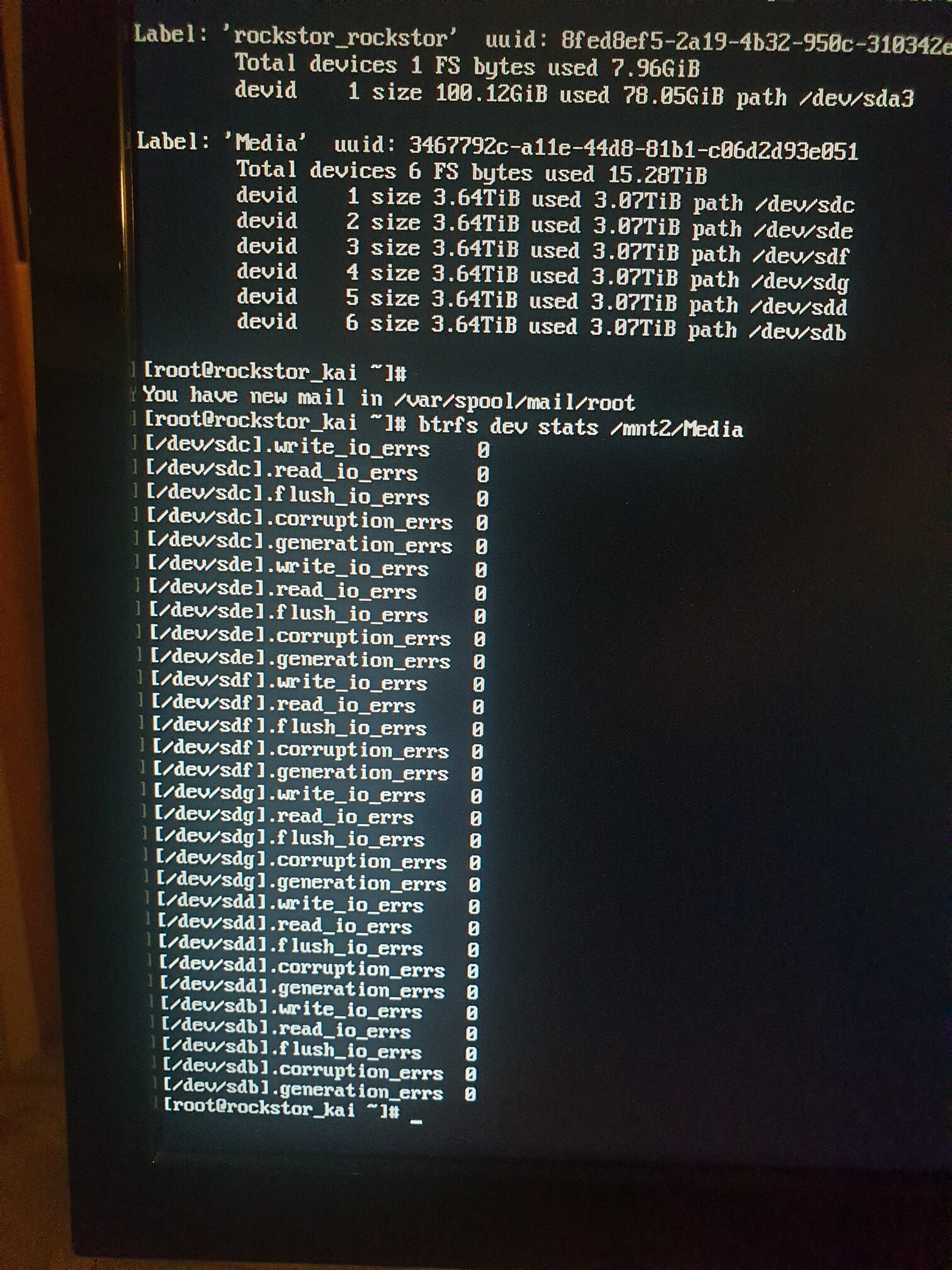
btrfs dev stats /mnt2/Media
It gives the error ‘tally’ to date (since the last stats reset), per device member, of the indicated Pool mount.
Might help at least with information. I.e. you may have a failing drive that has corrupted your pool and in which case it may show up in that commands output.
Hope that helps. And sorry I can’t put much time into this but others may well be able to chip in also. However if you can get the data off, given the pool is a parity raid level, that would seem like the best way to go. And if you do end up re-building then consider raid 1 as only looses half the space and is far more robust / mature than either of 5 or 6.
Thanks i will check it out, might have been damaged during this time of use, but the system has been unchanged for the last 4 years so strange that it suddenly have an issue now, but open for all options
Just to attest to @phillxnet statement that the memory might be a root cause for this situation:
After running my system for over four years now and the only changes being a replacement of all my drives with higher capacity ones and early on a faulty power supply, I recently started encountering “untraceable” (at least for me) system hangs, that could only be remedied by hard booting the server. Lucky enough, the btrfs was never negatively impacted (like read-only, etc.). I could never find any messages that indicated memory problems because it seemed to affect the kernel/system before any logs could be written to that effect. However, upon testing the memory with the latest memtest86+ version that came out just a few weeks ago (if you go to the links posted by @phillxnet) I found the offending memory stick rather quickly… even though my Motherboard/memory etc. is over 4 years old the older versions of memtest didn’t work for me (as you will notice they have published a windows-based USB installer version which I used).
So, the memory can go bad due to a variety of reasons, even if you don’t substantially change your build (localized high temperatures, bad connections on the substrate, etc. that’s doesn’t become apparent until after a long “burn-in” time.
On a side note, when I ran memtest, I did open up my server (since it’s a small housing) to ensure that I didn’t damage anything because of the test due to high temperature