@Tex1954 I can chip in a little here hopefully.
Firstly I second all that @Flox stated. In the early days, i.e. when MFM/RLL/IDE was the hardware port, hda etc were predictable per hardware port. That disappeared as SATA came in, and now the sda (from the earlier SCSI layer naming) is essentially random on each boot, depending on drive appearance/readiness I think. This created an early adaptation requirement at the time, where some systems had made assumption about the tally of sda type names to their wired ‘position’, in part based on earlier kernel & bios behaviour left over from the earlier hardware interfaces. Rockstor itself, very early on, made some false assumptions in this area: now resolved by using the by-id naming as canonical, as that was, in part, why the by-id names were created. And we track serials (also used in by-id name creation) to handle drives migrating from one interface to another.
The following is a recent kernel referenced used in fixing our TW drive activity widget. It contains the device names associated with drive interface types:
https://www.kernel.org/doc/Documentation/admin-guide/devices.txt
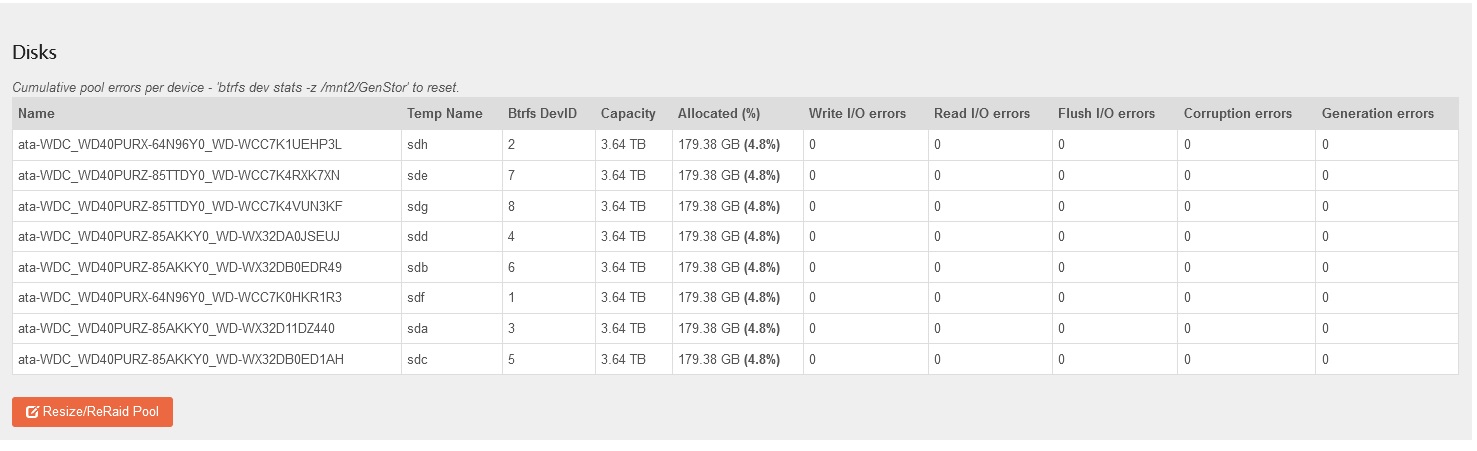
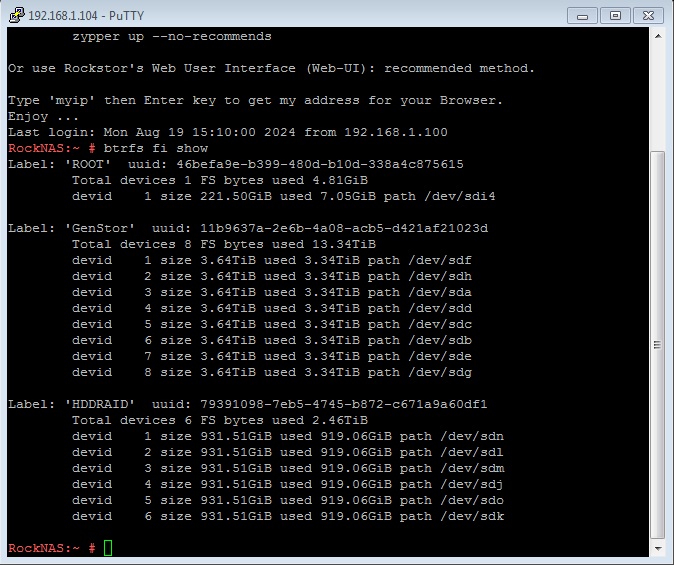
You are correct, and when you add a drive it gets the next number available: dev id is purely at the btrfs level. First Pool member to be formatted as such gets id 1. If it is removed from the pool, member ids start at 2. So not arbitrary but dependant on the order of addition to the Pool.
A conseptual element missing here re raid10 vs btrfs-raid10 use is that we are strictly, and currently soley aware of btrfs-raid10. The key difference is that btrfs profiles are akin but not the same as traditional hardware & md/dm raid setups. Btrfs raid is at the chunk level (1 GB sections) but drive aware. I.e. btrfs-raid1 ensures there are two copies on two different devices of each chunk. With 3 drives, say 1, 2, 3, chunk 1 may be on drive 1 & 2. But chunk 2 may be on drive 2 & 3. Ergo chunk not drive based: but drive aware for device redundancy.
The by-id names may well contain info about which hardware port they are attached to though. That may help regarding what drive is attached to what controller. Take a look at the drive overview, it also contains the associated Pool that each drive is a member of.
In part this is addressed by our use of by-id names. Does this pan-out in your current setup? If so we may have a Web-UI improvement where we can add to the disk table on the Pool details page to surface the port redundancy elements at play: if any.
Some NAS cases purposefully expose the end of the drive to inspection: this generally exposes a serial number sticker. Another option, if the drive can still be read from, is to use our flashing-light facility:
https://rockstor.com/docs/interface/storage/disks.html
See the Table links from left to right where we have:
- Bulb Icon - flash drive’s activity light to identify its physical location.
Which of course assumes there is an interface disk activity light paired with each associated drive, or a drive resident light is visible.
I.e. btrfs-raid does not account for interface redundancy, only drive (and at the chunk level). Interface redundancy can be accommodated, kernel wise, via multi-path: but that is more associated with enterprise drives that have two interfaces each. One attaches each drive to two independent controllers. Providing for controller fail-over. Rockstor is unaware, and currently incompatible, with this arrangement. But were I to have local access to such a system (cost constraints currently) I’d like to try to add this capability  time allowing. And of course our underlying openSUSE entirely supports such a thing. But again there would need to be a significant re-work of our lowest level disk management code to accommodate multi-path. However with the recent major clean-ups/modernisation enacted as part of: 5.0.9-0 this is now way more approachable: again assuming I had the necessary enterprise hardware.
time allowing. And of course our underlying openSUSE entirely supports such a thing. But again there would need to be a significant re-work of our lowest level disk management code to accommodate multi-path. However with the recent major clean-ups/modernisation enacted as part of: 5.0.9-0 this is now way more approachable: again assuming I had the necessary enterprise hardware.
Hope that helps, if only for some context.