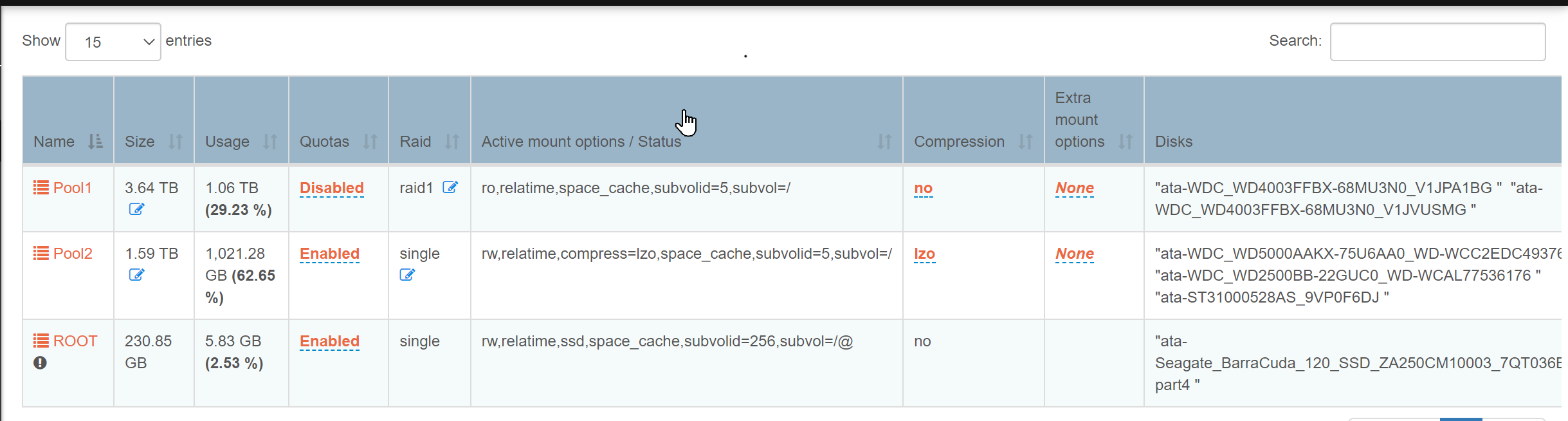
My primary data pool, “Pool1”, has become read only. Recent changes include:
-
I enabled compression and tried running a balance but it failed: Error running a command. cmd = btrfs balance start --full-balance /mnt2/Pool1. rc = 1. stdout = [’’]. stderr = [“ERROR: error during balancing ‘/mnt2/Pool1’: Read-only file system”, ‘There may be more info in syslog - try dmesg | tail’, ‘’]
Compression is now Off again. (Based on another of my recent discussions, I was going to enable quotas but have not yet done so.) -
I installed the Vaultwarden rockon but left it turned off until I have time to play with it. I subsequently found that I can’t delete one of the new shares (this was part of troubleshooting).
-
I had rescheduled some snapshots and a couple of them were set to trigger at the same time (midnight). Was this dumb and dangerous? For now, I’ve disabled snapshots tasks on that pool
-
I backed up 100GB from other computers to a share on Pool1.That’s just normal activity but it’s the only other thing I was up to yesterday.
I do have a backup but I would like to recover access to Pool1. Below is what I’ve tried so far but now i’m at a bit of a loss.
Thanks for any guidance.
rockstor:~ # btrfs filesystem show
Label: 'ROOT' uuid: d97982eb-fc92-4c35-8993-8bd2eb032704
Total devices 1 FS bytes used 5.73GiB
devid 1 size 230.85GiB used 6.80GiB path /dev/sdf4
Label: 'Pool2' uuid: 3c242b00-dfc5-4aa6-8e9c-5cff96a1c338
Total devices 3 FS bytes used 1019.78GiB
devid 1 size 931.51GiB used 730.00GiB path /dev/sdb
devid 2 size 232.89GiB used 31.00GiB path /dev/sde
devid 3 size 465.76GiB used 264.02GiB path /dev/sdd
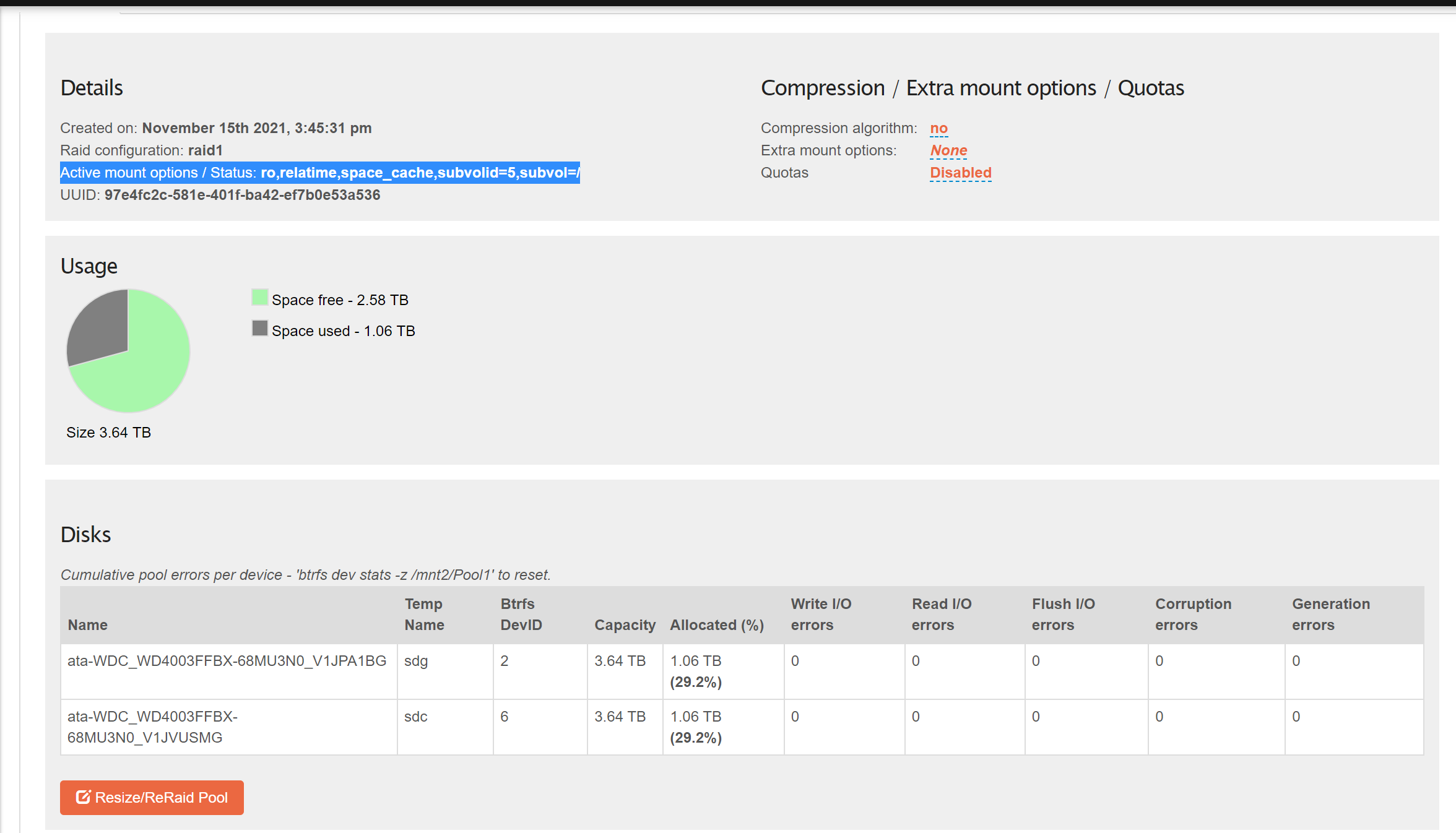
Label: 'Pool1' uuid: 97e4fc2c-581e-401f-ba42-ef7b0e53a536
Total devices 2 FS bytes used 1.06TiB
devid 2 size 3.64TiB used 1.06TiB path /dev/sdg
devid 6 size 3.64TiB used 1.06TiB path /dev/sdc
rockstor:~ # btrfs fi df /mnt2/Pool1
Data, RAID1: total=1.06TiB, used=1.06TiB
System, RAID1: total=32.00MiB, used=192.00KiB
Metadata, RAID1: total=3.00GiB, used=1.77GiB
GlobalReserve, single: total=512.00MiB, used=0.00B
rockstor:~ # btrfs fi usage /mnt2/Pool1
Overall:
Device size: 7.28TiB
Device allocated: 2.13TiB
Device unallocated: 5.15TiB
Device missing: 0.00B
Used: 2.12TiB
Free (estimated): 2.58TiB (min: 2.58TiB)
Data ratio: 2.00
Metadata ratio: 2.00
Global reserve: 512.00MiB (used: 0.00B)
Data,RAID1: Size:1.06TiB, Used:1.06TiB
/dev/sdc 1.06TiB
/dev/sdg 1.06TiB
Metadata,RAID1: Size:3.00GiB, Used:1.77GiB
/dev/sdc 3.00GiB
/dev/sdg 3.00GiB
System,RAID1: Size:32.00MiB, Used:192.00KiB
/dev/sdc 32.00MiB
/dev/sdg 32.00MiB
Unallocated:
/dev/sdc 2.57TiB
/dev/sdg 2.57TiB
rockstor:~ # btrfs scrub status -R /mnt2/Pool1
scrub status for 97e4fc2c-581e-401f-ba42-ef7b0e53a536
scrub started at Mon Nov 15 15:36:23 2021 and was aborted after 00:00:00
data_extents_scrubbed: 0
tree_extents_scrubbed: 0
data_bytes_scrubbed: 0
tree_bytes_scrubbed: 0
read_errors: 0
csum_errors: 0
verify_errors: 0
no_csum: 0
csum_discards: 0
super_errors: 0
malloc_errors: 0
uncorrectable_errors: 0
unverified_errors: 0
corrected_errors: 0
last_physical: 0
rockstor:~ #
rockstor:~ # btrfs scrub start /mnt2/Pool1
scrub started on /mnt2/Pool1, fsid 97e4fc2c-581e-401f-ba42-ef7b0e53a536 (pid=5351)
rockstor:~ # btrfs scrub status -R /mnt2/Pool1
scrub status for 97e4fc2c-581e-401f-ba42-ef7b0e53a536
scrub started at Mon Nov 15 15:57:44 2021 and was aborted after 00:00:00
data_extents_scrubbed: 0
tree_extents_scrubbed: 0
data_bytes_scrubbed: 0
tree_bytes_scrubbed: 0
read_errors: 0
csum_errors: 0
verify_errors: 0
no_csum: 0
csum_discards: 0
super_errors: 0
malloc_errors: 0
uncorrectable_errors: 0
unverified_errors: 0
corrected_errors: 0
last_physical: 0
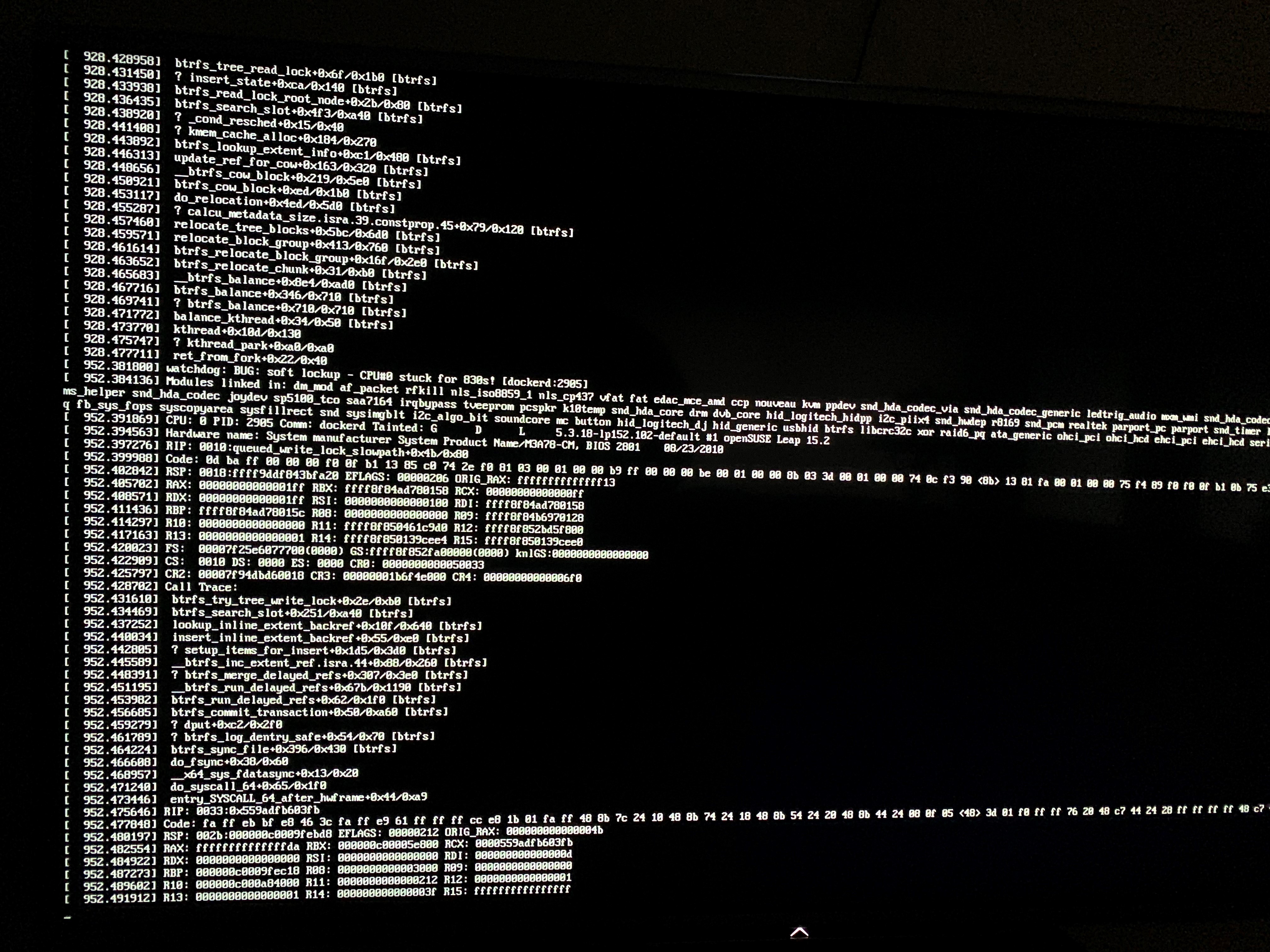
rockstor:~ # dmesg | tail
[ 1209.087029] BTRFS info (device sdg): use no compression, level 0
[ 1209.087260] BTRFS info (device sdg): disk space caching is enabled
[ 1209.114138] BTRFS info (device sdg): use no compression, level 0
[ 1209.114370] BTRFS info (device sdg): disk space caching is enabled
[ 1209.141664] BTRFS info (device sdg): use no compression, level 0
[ 1209.141893] BTRFS info (device sdg): disk space caching is enabled
[ 1209.169733] BTRFS info (device sdg): use no compression, level 0
[ 1209.169965] BTRFS info (device sdg): disk space caching is enabled
[ 1209.197352] BTRFS info (device sdg): use no compression, level 0
[ 1209.197584] BTRFS info (device sdg): disk space caching is enabled
rockstor:~ #