[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
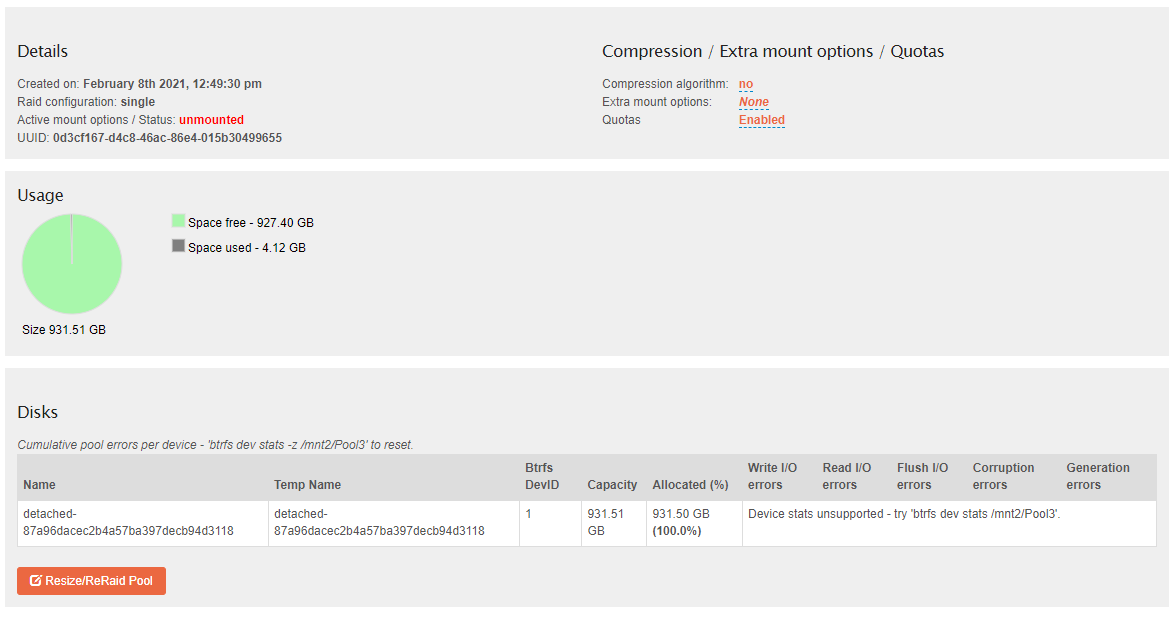
Trying to remove a single disk from a pool that contains only the one disk. Which is detached, as it is defective.
Just Trying to delete the disk from the list of disks.
Detailed step by step instructions to reproduce the problem
Add a USB drive, create a new pool containing the whole disk.
Physically remove the disk .
Try and remove the disk using the resize/reraid option in the linked pool page.
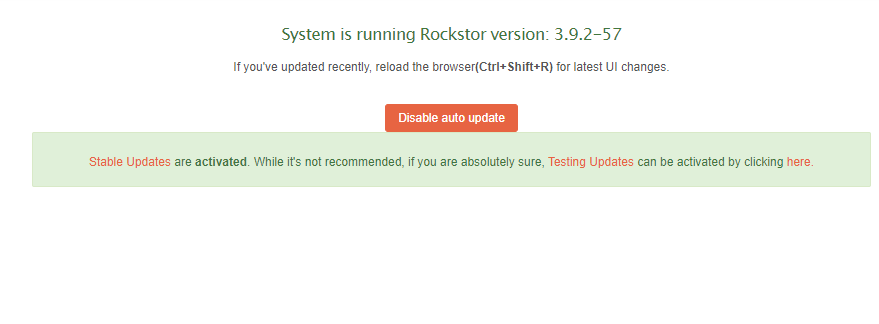
This was an issue fixed quite some time ago. Are you running a v4 “Built on openSUSE” Rockstor version or are you still using the now legacy / deprecated v3 (CentOS based) variant.
We can’t auto upgrade from CentOS to openSUSE unfortunately. But all old pools and config saves can be imported identically to in our CentOS based variant. 3.9.2-57 was our last stable release build on CentOS.
If you have created no shares (btrfs subvolumes) on your old system pool (rockstor_rockstor in those days) then this will make things easier. Always best to leave the system pool to the system, and have add-on data pools completely independant. If you have done this, and take care during the re-install, then you can simply import your old pools. Config restore is expected to work to restore all that was saved, but now-a-days there is more saved than in our CentOS days. There are know issues that we are working through in the config restore but they are likewise mirrored in our older code so do represent a differences but just a state of the code generally.
You can take a look at the following how-to to see the entirely of the new install process:
Take care, if you are preserving the old system disk, i.e. if you are using a new system disk for the new v4 install, that you don’t leave the v3 disk attached. It confuses things. Not an issue if you are installing over the top of the old system disk. But then of course you have to way-back other than another re-install of the old system which is very long winded given it’s years vintage.
The new installer is much faster than our old installer and your system is up-and-running before even the first reboot.
Well worth the pain of a re-install thought as we have fixed many things since 3.9.2-57 and now have a far newer (by years) btrfs base which is well maintained by our new upstream of openSUSE/SuSE. So we can run the default OS kernel from our upstream.
With regard to your particular report we have the now closed issues of:
and
which were both addressed by pull request:
which was merged in v 3.9.2-60 June 2020 (3 releases after we could no longer build for CentOS):
Our downloads now start out at 4.0.9-0 and are considered Release Candidate 10. We don’t yet have even a placeholder for the Leap 15.3 stable but should have very soon. There is no harm in subscribing using your existing stable subscription to the stable updates channel as for now, given it doesn’t exist, it will just be ignored. But when it does your system should offer that rpm when it’s released to that channel.
A little note on Appliance ID’s. In our new “Built on openSUSE” variant they are always lowercase. As they should be. In our early CentOS variants they were also lower case; but later for a while the kernel generated uppercase. So depending on your existing subscription you may just have to edit to lowercase your Appliance ID within Appman:
Assuming your Appliance ID remains unchanged bar the case. Otherwise a simple edit to whatever the new installer assigned as you new Appliance ID should render your old activation code usable.