[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
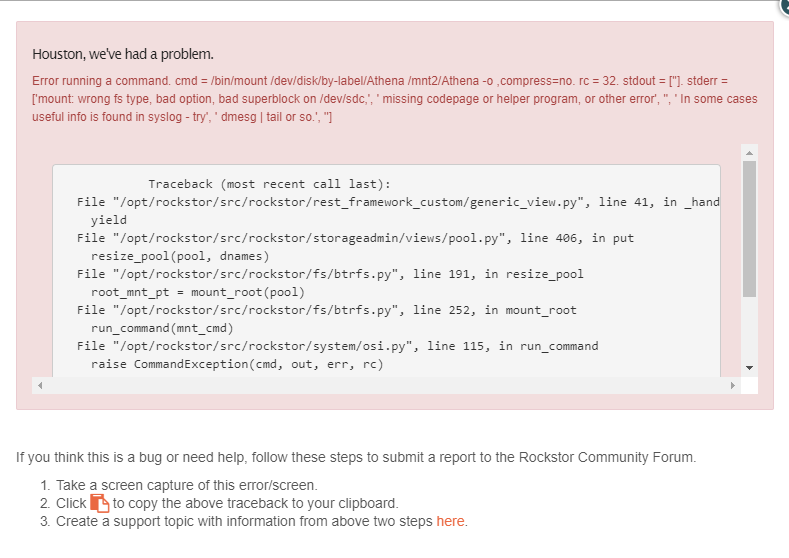
RAID 5 setup, one disk went bad. Was able to successfully remove and delete bad drive, but I cannot resize the pool to add the new drive.
Detailed step by step instructions to reproduce the problem
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py", line 41, in _handle_exception
yield
File "/opt/rockstor/src/rockstor/storageadmin/views/pool.py", line 406, in put
resize_pool(pool, dnames)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 191, in resize_pool
root_mnt_pt = mount_root(pool)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 252, in mount_root
run_command(mnt_cmd)
File "/opt/rockstor/src/rockstor/system/osi.py", line 115, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /bin/mount /dev/disk/by-label/Athena /mnt2/Athena -o ,compress=no. rc = 32. stdout = ['']. stderr = ['mount: wrong fs type, bad option, bad superblock on /dev/sdc,', ' missing codepage or helper program, or other error', '', ' In some cases useful info is found in syslog - try', ' dmesg | tail or so.', '']
How did you go about this. I ask as current Rockstor’s UI falls sort in this regard, we have some pending issues to address this, such as:
which I have earmarked in my personal queue and hope to embark upon soon. So as it stands it is required that repair scenarios such as applying / employing degraded mount options and using “btrfs device delete mountpoint missing” or the like have to be done ‘by hand’ at the command line. Likewise, although we track drives (via their serial number) we only flag them as “detached-…” and offer to remove them from the system but don’t yet perform the pool delete side of this operation: ie they are only removed from Rockstor’s db not from the pool. Hence the requirement to manually do the pool maintenance.
I mention this as your given error message can indicate a pool that is not yet healthy again as the message: "
can be mounts/btrfs response to an attempt to mount a pool that has, for example, a missing device.
The following command should indicate any missing devices in the observable pools:
btrfs fi show
This pool may still mount under a degraded mount option but note that in some circumstances you only get one shot at mounting degraded and rw (the default). And the write capability is required to enact a device missing or any other repair. Given you are using one of the currently risky parity raid levels (5 and 6) you might first want to mount degraded,ro and retrieve what data you may otherwise put at risk, if any; prior to attempting any repair via a rw mount. On the other hand it also depends on your Rockstor version as improvements have been made more recently on pool mount logic and for that matter on surfacing, in the UI, the mount status. So what update channel and version of Rockstor are you running. Currently only the latest testing channel surfaces the nature of a pool / share mount and will thus indicate if a pool is in fact mounted.
So in short I suspect your pool is not mounted, hence the inability to resize it. Also keep in mind the minimum drive count for the given raid level, especially during the repair / resize procedure.