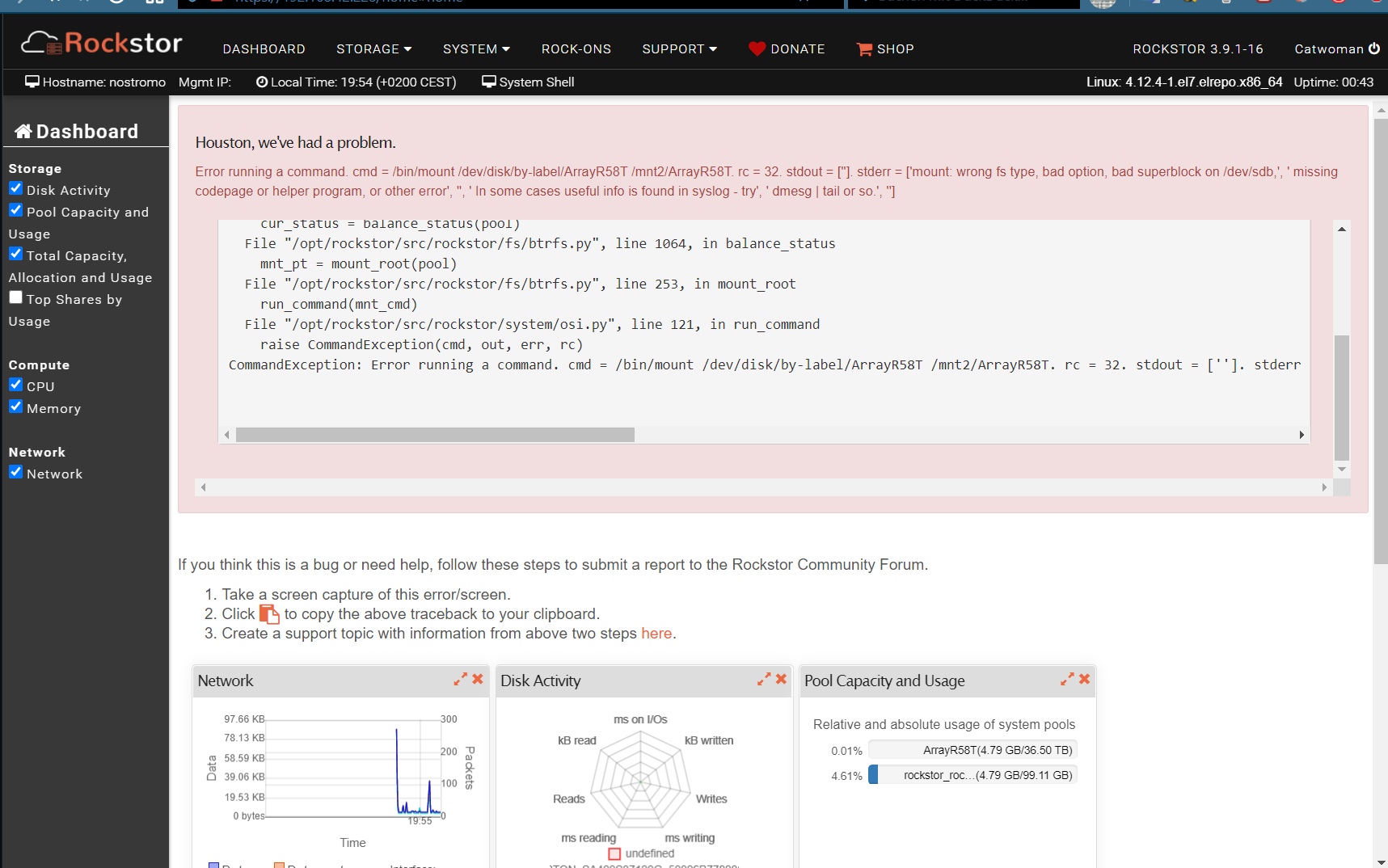
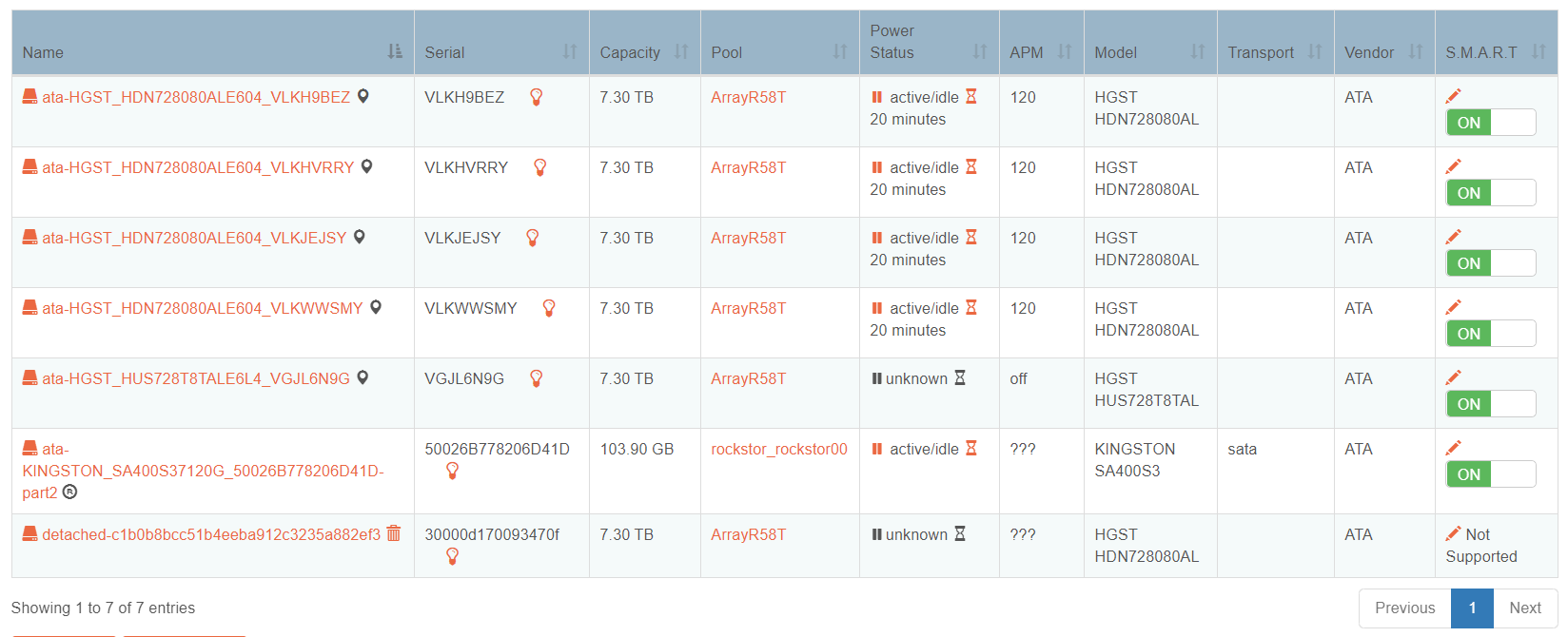
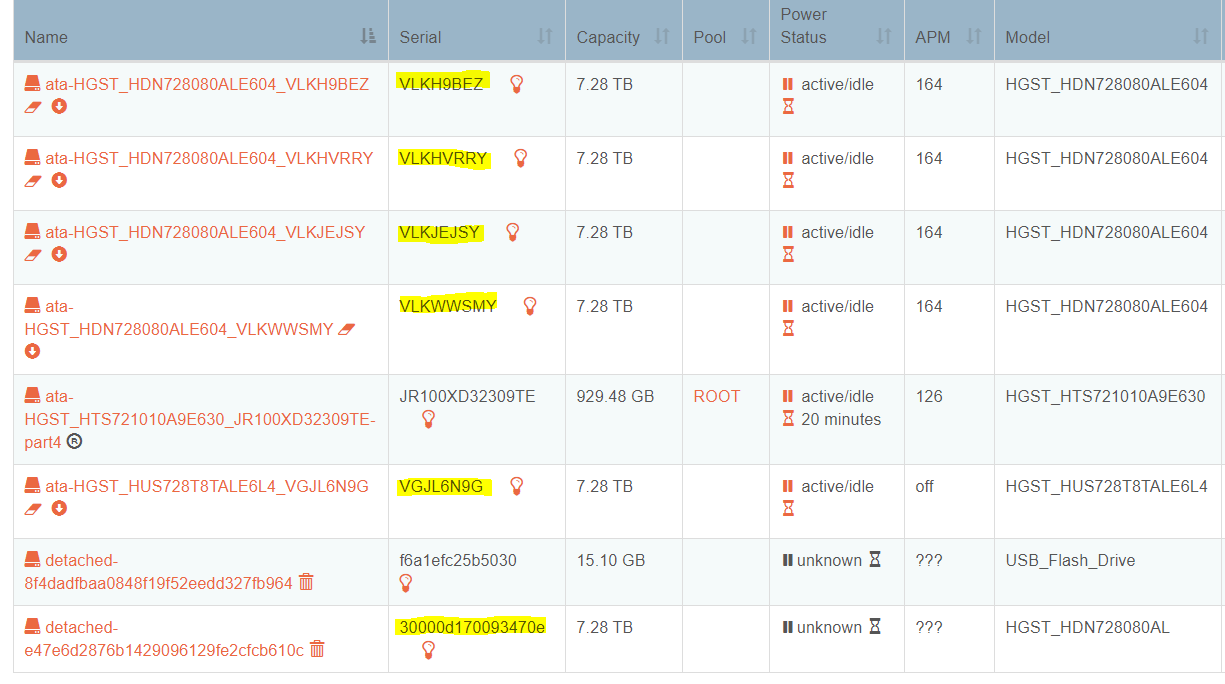
Hello, I have added a fifth hard disk to my Raid 5 pool and was in the balancing process.
I knew it was not a good idea, but I had to shut down the server even though the process was not yet finished (15%).
After rebooting, the pool and of course all the shares were gone.
As far as I understand, the pool “ArrayR58T” could not be mounted again.
The restart of the balancing obviously failed.
A new reboot brought the same result.
Can anyone give me a hint where to start troubleshooting?
I am not a Linux professional, but I will do my best.
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py", line 41, in _handle_exception
yield
File "/opt/rockstor/src/rockstor/storageadmin/views/pool_balance.py", line 47, in get_queryset
self._balance_status(pool)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/utils/decorators.py", line 145, in inner
return func(*args, **kwargs)
File "/opt/rockstor/src/rockstor/storageadmin/views/pool_balance.py", line 72, in _balance_status
cur_status = balance_status(pool)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1064, in balance_status
mnt_pt = mount_root(pool)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 253, in mount_root
run_command(mnt_cmd)
File "/opt/rockstor/src/rockstor/system/osi.py", line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /bin/mount /dev/disk/by-label/ArrayR58T /mnt2/ArrayR58T. rc = 32. stdout = ['']. stderr = ['mount: wrong fs type, bad option, bad superblock on /dev/sdb,', ' missing codepage or helper program, or other error', '', ' In some cases useful info is found in syslog - try', ' dmesg | tail or so.', '']
The Rockstor/Kernel version is unfortunately quite old, too. Some of the RAID5 stability (and the associated rebalancing operations) has improved with more recent Kernel versions.
I leave it to @phillxnet to offer additional advice, since he has been dealing with a few of these in the past.
Hi Dan, thanks for your reply.
I have gathered some additional info here:
[root@nostromo ~]# btrfs fi show
Label: 'rockstor_rockstor00' uuid: f1394d18-6783-4c72-a41f-7146ac165881
Total devices 1 FS bytes used 3.83GiB
devid 1 size 103.85GiB used 9.02GiB path /dev/sdf2
Label: ‘ArrayR58T’ uuid: a5d2ba05-fe4d-4217-81d6-029bbec785cf
Total devices 5 FS bytes used 21.67TiB
devid 1 size 7.28TiB used 6.98TiB path /dev/sdd
devid 2 size 7.28TiB used 6.98TiB path /dev/sde
devid 3 size 7.28TiB used 6.99TiB path /dev/sdc
devid 4 size 7.28TiB used 6.98TiB path /dev/sdb
devid 5 size 7.28TiB used 824.00GiB path /dev/sda
[root@nostromo ~]# yum info rockstor
Loaded plugins: changelog, fastestmirror
Loading mirror speeds from cached hostfile
detached-c1… appeared during balancing
The SMART values of the disks are all good.
As expected, when I started integrating the new disk, the dashboard showed an additional 7.4TB of free space because the pool was already close to full.
After a few hours of balancing, I noticed that 14.xTB of free space was displayed. I thought it was possibly an error in the dashboard display.
However, I found a hint that one of the old disks had problems several times during balancing in the rockstor.log:
...
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 364, in _update_disk_state
do.name, do.smart_options)
File "/opt/rockstor/src/rockstor/system/smart.py", line 320, in available
[SMART, '--info'] + get_dev_options(device, custom_options))
File "/opt/rockstor/src/rockstor/system/osi.py", line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/sbin/smartctl --info /dev/disk/by-id/ata-HGST_HDN728080ALE604_VLKJEJSY. rc = 2. stdout = ['smartctl 7.0 2018-12-30 r4883 [x86_64-linux-4.12.4-1.el7.elrepo.x86_64] (local build)', 'Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org', '', 'Smartctl open device: /dev/disk/by-id/ata-HGST_HDN728080ALE604_VLKJEJSY failed: No such device or address', '']. stderr = ['']
...
I can not explain this.
I would now update kernel and rockstor and maybe add an additional power line to the backplane (because of the disk error) but I’ll hold off until I hear your opinion.
You may be swimming against the tide some what with the older CentOS based Rockstor variant. And even if you upgraded to our Stable offering in that now legacy variant the kernel is not updated. So you might well be better off attempting this ‘recovery’ scenario using an instance of our Rockstor 4 ‘Built on openSUSE’. No installer downloads as of yet, available soon hopefully, but you can build your own fully updated version via the instructions available in our GitHub repo for this:
This will put you in better ‘hands’ re the capabilities of the less well developed parity raids within btrfs, i.e. 5 & 6, but obviously doesn’t address any hardware strangeness such as your reported smart drive error where smartmontools couldn’t find the stated drive. It may be you have a flaky connection to the drive. this would also explain the ‘rough’ detached devices. It may well help those here help you if we can also see the name mapping between what Rockstor references as the ‘temp’ name of sd* and the by-id names. Temp name is used by Rockstor as they can change from boot to boot.
So if you could post the output of the following two commands executed on the same boot:
btrfs fi show
ls -la /dev/disk/by-id/
Normally if there is a detached disk then btrfs fi show indicates a missing disk. And the fact the smartmontools program reported a missing device by it by-id name, which doesn’t change, suggests that you may have an intermittent drive connection. Or, as you suggested, a drive that comes and goes.
Drives in Rockstor are tracked via their serial number, see:
But that serial number doesn’t look like any of the others. So I’m a little confused by that currently.
Best see about building a Rockstor 4 installer and using a resulting install of that to do any pool repair I think. You will likely want to continue using this instance there after but if needed you can always revert back to your existing install if need be. Just don’t have both system disks attached at the same time as this has known confusion issues.
Also if you are to use a newer instance for the pool recovery (advised due to parity raid having known problems in repair) and want to use the Web-UI to do this, as opposed to the command line only, then you will have to first mount the poorly pool first via the command line as Rockstor can’t yet import poorly pools that can only mount ro, which may be the case with your current pool.
mount -o ro /dev/disk/by-id/<any-pool-member-by-id-name> /mnt2/<pool-label/name-here>
N.B. as the balance was ongoing when you shutdown, it may want to resume, and in turn cause problems. So you could add to the optinos (the following -o) a skip_balance, so that you have “-o ro, skip_balance” and out of interest if you also have a missing disk, indicated by btrfs fi show, then you will also need a ‘degraded’ in there too.
Once you have a successful mount in place a Rockstor import (via any disk member) should work as expected. This is helpful as you can then ‘deal’ with things in the newer install where the Web-UI has far greater capabilities for reporting issues and helping with repair etc and sits on top of a years newer kernel and btrfs-progs.
I am unfortunately no expert in any of these areas so if anyone else has further suggestions here then please chip in. But the simply act of a shutdown during a balance is not expected to fail so there may well be something else a-foot here.
Repeating what our Web-UI and docs suggest, the btrfs parity raid levels of 5/6 and not considered read for production and actually lack some features in comparison to the raid 1/10 variants. They are simply younger within the fs. Hence the suggestion to use a Rockstor 4 instance to gain whatever advantage / fixes you can from the aggressive btrfs back-port work done by the SuSE/openSUSE folks that we base our Rockstor 4 instance on. Plus that kernel gets updates and our legacy CentOS one in Rockstor 3 does not.
And be sure to look at your general system log also via the “journalctl” command i.e. for a live feed of this from a terminal you can do
journalctl -f
and there are many other options to that command.
Hope that helps and let us know how you get along.
Thank you for looking at this.
After having to wait a few days because I ordered parts for the NAS, I started the restore today.
As you suggested, I reinstalled Rockstor. The current state is this:
I then reconnected the 5 hard drives.
Here is a screenshot of the disks right after the first boot.
The new entries are highlighted in yellow.
I didn’t do anything in the GUI, but tried to mount the disks via the cli right away. nostromo:~ # btrfs fi show
Label: ‘ROOT’ uuid: 3cc0f894-0f0a-494c-9043-5ee552e82f7a
Total devices 1 FS bytes used 1.62GiB
devid 1 size 929.48GiB used 2.77GiB path /dev/sda4
Label: ‘ArrayR58T’ uuid: a5d2ba05-fe4d-4217-81d6-029bbec785cf
Total devices 5 FS bytes used 21.67TiB
devid 1 size 7.28TiB used 6.98TiB path /dev/sdb
devid 2 size 7.28TiB used 6.98TiB path /dev/sdf
devid 3 size 7.28TiB used 6.99TiB path /dev/sdc
devid 4 size 7.28TiB used 6.98TiB path /dev/sdd
devid 5 size 7.28TiB used 824.00GiB path /dev/sde
nostromo:~ # mount -o ro,skip_balance /dev/disk/by-id/ata-HGST_HDN728080ALE604_VLKH9BEZ /mnt2/ArrayR58T
mount: /mnt2/ArrayR58T: mount point does not exist.
nostromo:~ # mount -o ro,skip_balance /dev/disk/by-id/wwn-0x5000cca260f13b3f /mnt2/ArrayR58T
mount: /mnt2/ArrayR58T: mount point does not exist.
Embarrassingly I got stuck already at the first try.
However, I’m not sure if I tried the right ID, because two entries for /sdb are shown:
But the real problem seems to be that there is no ArrayR58T pool: nostromo:~ # cd /mnt2
nostromo:/mnt2 # ls
ROOT home
Apparently I haven’t quite understood something yet, or overlooked it.
Now I am tempted to just try ‘import data’ in the web GUI, because here, as far as I understood, a new pool is created based on the label.
But I hesitate because I don’t want to start a process that may destroy more than it improves. That’s why I’m asking for your opinion.
P.S.
The disc in question is the third from the top in the first discs screenshot, sorry about the poor resolution image. Unfortunately the upload is downsizing it.
@musugru Hello again, and well done on getting Rockstor 4 build and installed.
Re:
I must apologies; this is as a result of my incomplete instructions. I’d completely forgot that the mount point (read directory) must first exist prior to using it as a mount point. That’s what the error message is attempting to convey.
You can trivially create that directory as follows:
mkdir /mnt2/ArrayR58T
Which stands for Make Directory. Sorry about that. Do that first then do the mount commands. You should then be able to import the pool via the Web-UI. Note however that if the pool will only mount ro, or with other special options, they will not be ‘known’ to Rockstor on reboot. But once the first import is completed this way you can always add the required mount options as custom mount options within the Web-UI so that they can be automatically applied by Rockstor on reboot.
It’s actually just the directory that is created and a mount similar to what you are attempting, only we don’t yet have the ability to have special mount options during import. So we can’t import poorly or read only pools yet. But if the pool is already mounted with it’s special options Rockstor sees the mount (and mount point) and merryly goes about creating it’s representation of the pool.
Note that the pool itself exists on the disks entirely. Only Rockstor’s representation of the pool is created for the Web-UI’s use during an import. New pools are only created during the pool create mechanism. Imports simply read what is already on-disk/disk-set and build a database for the Web-UI to function. The source of truth for that database is always the on-disk information. Every time you refresh many of the web pages within the Web-UI the system checks to see if the Web-UI database is still reflecting the on-disk truth. We can’t represent all btrfs states so there are some limitations but if the pool (btrfs Volume) and shares (btrfs sub-vols) are created by a prior Rockstor instance, or in the same location / structure as Rockstor does it, then imports should work.
Thanks, I’m not doing very well here I’m afraid. But lets muddle through and hopefully others can chip in here as we go.
Once you have an initial import done the pool will be known to Rockstor as a managed pool, i.e. one that it should concern itself with. Otherwise it simply ignores pools that exist outside of what it has imported. That import should help with leveraging the Web-UI’s more accessible capabilities with helping to show what’s going on.
And if you manage to establish a ro mount then you can at least refresh your backups prior to moving on.
Incidentally you can safely remove the USB Flash Drive 'detached-*" disk as that is simply left over from a prior device attachment.
As before, let us know how you get on, and again appologies for missing the mkdir command. We need a documentation entry to allow for read only mounts of poorly pools in our docs really. I’ve now created the following issue to address this short fall:
Hope that helps and apologies again for holding up proceeding here. But now you have a working Rockstor 4 install and your drives attached and recognised you are more than half way home as our Leap 15.2 base has many modern curated back-ports to it’s btrfs stack, curtsy of the openSUSE/SuSE folks so you at least now have that on your side with regard to moving forward.
Hello @phillxnet sorry that my response again took a while.
In fact, I continued right after your post, but then had an unexpected setback.
So I was glad that I had to work the night shift on the weekend and I could get some distance from the problem.
That is what I did:
I created the folder /mnt2/ArrayR58T (I would never have guessed that the solution would be so simple) Thanks for explaining the background.
And started mounting the drives, trying the ro and skip_balance option.
That ended for all five drives (with different IDs of course) in: nostromo:~ # mount -o ro,skip_balance /dev/disk/by-id/ata-HGST_HDN728080ALE604_VLKH9BEZ /mnt2/ArrayR58T
mount: /mnt2/ArrayR58T: wrong fs type, bad option, bad superblock on /dev/sdb, missing codepage or helper program, or other error.
Where each command sent generated the exact same set of messages: … May 28 21:08:00 nostromo kernel: BTRFS info (device sdb): disk space caching is enabled
May 28 21:08:00 nostromo kernel: BTRFS info (device sdb): has skinny extents
May 28 21:08:01 nostromo kernel: BTRFS error (device sdb): bad tree block start, want 28577100398592 have 4532272716066425894
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): parent transid verify failed on 28576587202560 wanted 40633 found 40395
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): bad tree block start, want 28577086390272 have 16296381892167134805
May 28 21:08:02 nostromo kernel: BTRFS info (device sdb): bdev /dev/sdc errs: wr 8640361, rd 9182552, flush 424, corrupt 0, gen 0
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): bad tree block start, want 28576872759296 have 13496996367675712334
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): bad tree block start, want 28576872759296 have 0
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): failed to read block groups: -5
May 28 21:08:02 nostromo kernel: BTRFS error (device sdb): open_ctree failed
I didn’t think the simple mount command for a volume would do a search for its “former pool mates”. (I assume that’s what happened)
So I guess I should try the degraded option to prevent that.
But I am puzzled. I was prepared to mount /sdc with degraded, since that was the flapping drive during balancing. I didn’t expect to find btrfs errors on /sdb. At least I was hoping not to find any.
If I now proceed by trying to mount /sdb with ‘-o degraded,ro,skip_balance’, should I continue to mount the other drives without the degraded option?
This is probably not possible.
If I am then forced to mount all drives with ‘-o degraded,ro,skip_balance’ - and that actually works, can the gui still provide me with the “import pool (and magically fix this mess)” button, even though all former pool members have then left?
And by the way. If I use ‘-o degraded,ro,skip_balance’, isn’t skip_balance actually unnecessary?
What else can I do? Fix the btrfs errors before I move on? I googled extensively on this and found no real success story. Even experienced users ended up in a trial and error attempt that too often ended in rebuild and backup restore. At least that is my impression after several hours of reading.
This leaves me in the state that I really have no choice but to try to mount the drives somehow and hope for rockstor/btrfs repair capabilities.
Still, some reassurance would be appreciated.
P.S. @phillxnet No need to apologize, it’s certainly not easy to adjust to the different skill levels in each case and where I’ve read other threads I think you manage that very well. In fact, I am grateful that you are helping me at all. Besides, it’s about my private NAS, which serves as an archive. So i can take my time and proceed carefully.
Yes, on a healthy pool one only needs to specify a single member of the pool and all it’s prior ‘mates’, read pool members, will be invoked automatically in that mount command. In some cases a btrfs rescan command can be needed for the system to know those prior members are even attached, but that is less common these days.
It may well be, and looks a little like, you have 2 drives with reported errors, or at least recorded failures in the past while members of this pool, and as such this pool is outside the single drive failure capability of raid5. Also, given your pool is of the younger parity raid levels of 5/6, the repair capability is less well developed, but getting much better more of late.
And of particular note, if you have had a dive ‘coming and going’ that is actually a very difficult scenario for raid to handle and a particular weakness of the parity raids within btrfs, again I think due mainly to their less production quality at the moment. This on top of what looks like a drive with additional errors and you may be simply out of luck on this one.
But many btrfs commands require first a mount of some sort.
One mounts the volume as a whole, via an one, or more, of it’s members specified at your option. The pool itself is mounted with the specified options. Further mount commands of the same pool via other members is not going to work out as that pool is already mounted, or not in this case. Rockstor itself actually initially tries to mount by label first, and thereafter, if a failure is sensed, will try to mount the same pool by each of it’s known members in turn until no more members are left. But upon the first sucessfull attempt no more attempts are made as the mount is then achieved.
Se how you get on with the degraded option as that is definitely required if a device is missing, but again 5/6 raid levels in btrfs are not at their best in this last ditch scenario.
If you do really need something from this pool and all mount attempts fail, although there are many for recovery, but you do appear to be out-of-bounds with 2 disks having potentially failed, there is also the btrfs restore command. But it can take a very long time and you want to stack you changes in you favour first. Which may be to have the known problem drive disconnected and do a degraded mount. And only if that doesn’t work do you try for a restore procedure which is generally only resorted to in extreme conditions:
We don’t, unfortunately have such a magic button, at least not yet. But repair scenarios/options are every expanding wtihin btrfs. But yes, if you can achieve a mount of any type at the expected /mnt2/ then an import should work there after. Assuming the reported subvols (shares) are not too scrambled. But usually any mount has some degree of sanity as that is what usually prevents a successful mount. The btrfs restore command is thus used as a last stop in this respect as it scrapes data where it can ignoring errors that would normally fail a ‘sane’ mount.
Hope that helps and my apologies for not being more expert in this area. There are options to mount that attempt to use older ‘versions’ of the master key organisation stash for the pool but that is more relevant to btrfs specific forums. And note that if you can get a read write mount degraded mount a typical scrub is the tool to get things back in order. But if there were 2 unrelated failures here you will likely be swimming upstream.
And as you say, this is a less critical scenario that is good to gain some working knowledge within but it may also be stacked against you re parity raid / intermittent drive connection / disconnection live, and potentially 2 members with reported issues.
Try having the minimum number of your thouight to be best drives left where you don’t exceed the maximum of the raid level for missing devices and go for ro degraded and skip_balance mount. if that works then you can import and take things from there and refresh your backups and move to rw degraded and start repair / scrub etc. And likely either add a disk so degraded isn’t required or move to a raid level where the remaining disk numbers are acceptable. But that’s getting ahead of where you are currently, as Rockstor itself can tell you little without at least having seen the pool at least once mounted.
Thanks for your comments and hopefully others can chip in here with further assistance. And do keep us posted on how things work out. If you had critical data that lived no where else I would advise utilising the linux-btrfs mailing list. But given this is not the case, in my understanding, it may not be worth potentially ‘bothering’ the btrfs world experts available there. On a related note. given you failure to mount to date, and if this continues with other options such as degraded and dropping as many dodgy drives as you can (1 in this case) you could also, mainly out of interest likely, try the latest release of Tumbleweed to attempt your mount/repair. You can always, once the pool is again mountable, return to the more predictable quality of the ‘Build on openSUSE’, Leap 15.2 in this case, Rockstor ‘helper’. Just a thought, and do keep us posted on your progress.