I had a disk fail, removed it, cant be detected at all now.
I also attempted to update/restart the OS, then found out my motherboard failed. Replaced it.
Installed the latest rockstor(which was an upgrade from v3/centos to v4/suse)
Have not restored the backup yet as the instructions mention importing the pool should be done first.
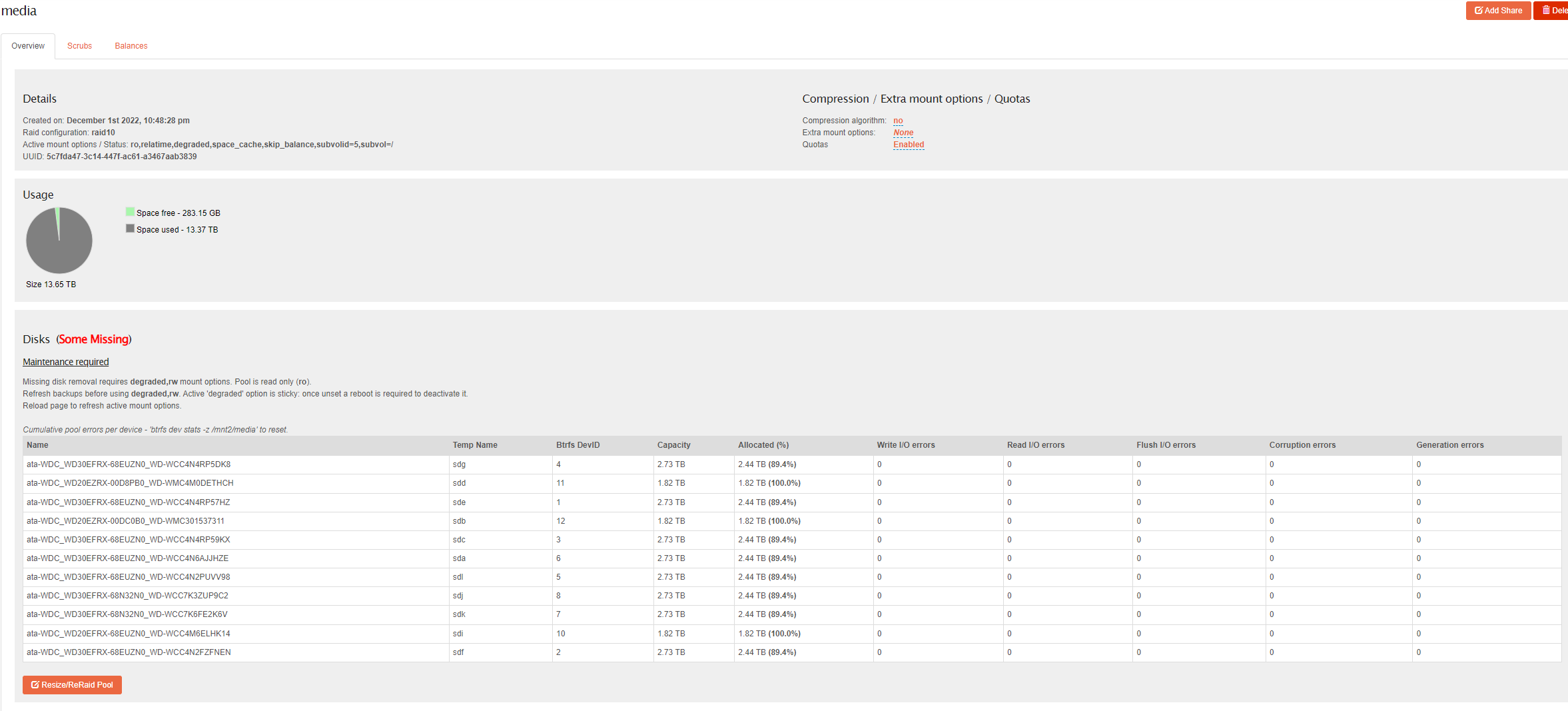
Currently I have a 12 disk (83TB + 42TB) RAID 10 pool. Minus the one disk that is missing now.
I was able to mount the pool with read-only + degraded using the docs.
I mainly need help with the overall approach I should take to recover this. The pool is pretty full at the moment also. Would just re-sizing it as is work ? If I got a new drive and popped it in, could I just add it and rebalance ?
Detailed step by step instructions to reproduce the problem
Lose a disk in a raid10 array, reinstall rockstor and import the pool by mounting it with read-only and degraded.
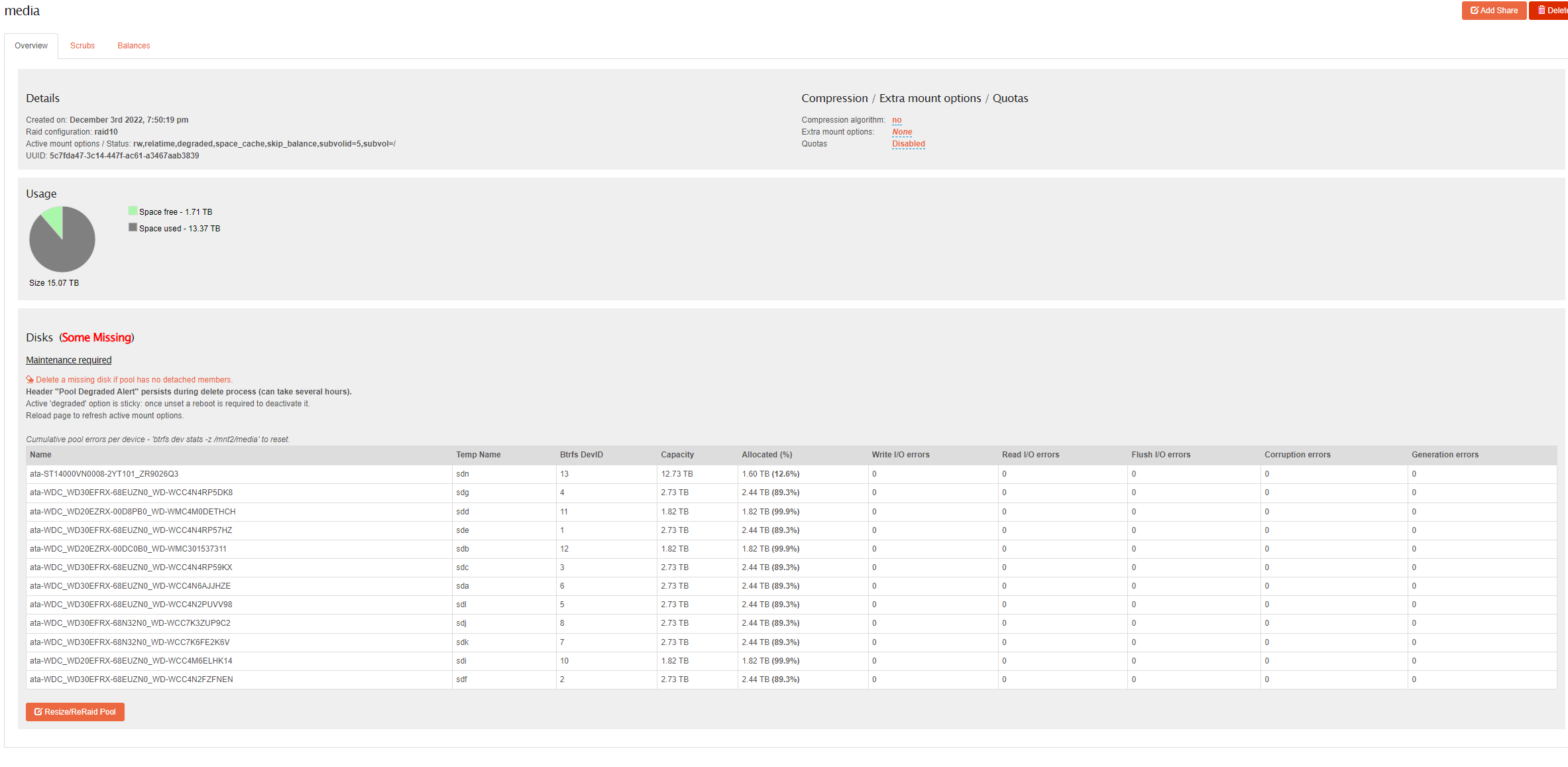
Thank you. I had seen that page but before I could make use of it I needed to mount rw. I just re-used all options it already had active but swapped ro for rw. Was unsure if it was any different from regular mount and read warnings about only having one chance to mount rw so was wary.
mount -o remount,rw,relatime,degraded,space_cache,skip_balance,subvolid=5,subvol=/ /dev/sde /mnt2/media
I clicked on [ Delete a missing disk if pool has no detached members.](https://asdallnas01/home#) and it ran for a long time, about a day before it errored out with:
Traceback (most recent call last): File "/opt/rockstor/eggs/huey-2.3.0-py2.7.egg/huey/api.py", line 360, in _execute task_value = task.execute() File "/opt/rockstor/eggs/huey-2.3.0-py2.7.egg/huey/api.py", line 724, in execute return func(*args, **kwargs) File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1787, in start_resize_pool raise e CommandException: Error running a command. cmd = /usr/sbin/btrfs device delete missing /mnt2/media. rc = 1. stdout = ['']. stderr = ["ERROR: error removing device 'missing': Input/output error", '']
I don’t know how, but I inadvertedly added a new disk at the same time, im trying to phase out the 2/3tb drives as part of the recovery/rebalance/replacement.
Okay, I think you should give it a shot “by-hand”.
Assuming the pool is still ro mounted and you have added a new disk which is at least as big as the failed one btrfs device usage /mnt2/media
get the device-id of the missing one
btrfs replace start *X* /dev/*Y* /mnt2/media
where *X* stands for the failed HDD’s device-id and
*Y* stands for the new HDD’s device-id (check dmesg or fdisk -l)
So e.g.: btrfs replace start 6 /dev/sdk /mnt2/media
If this doesn’t work you should try to add a new disk (instead of replacing): btrfs device add /dev/*Y* /mnt2/media
Then you should do a btrfs balance start /mnt2/media
Afterwards you should be safe to remove the failed disk btrfs device remove *X* /mnt2/media
Just to make sure: I would avoid replacing other working disks in you current situation. This will end in data loss.
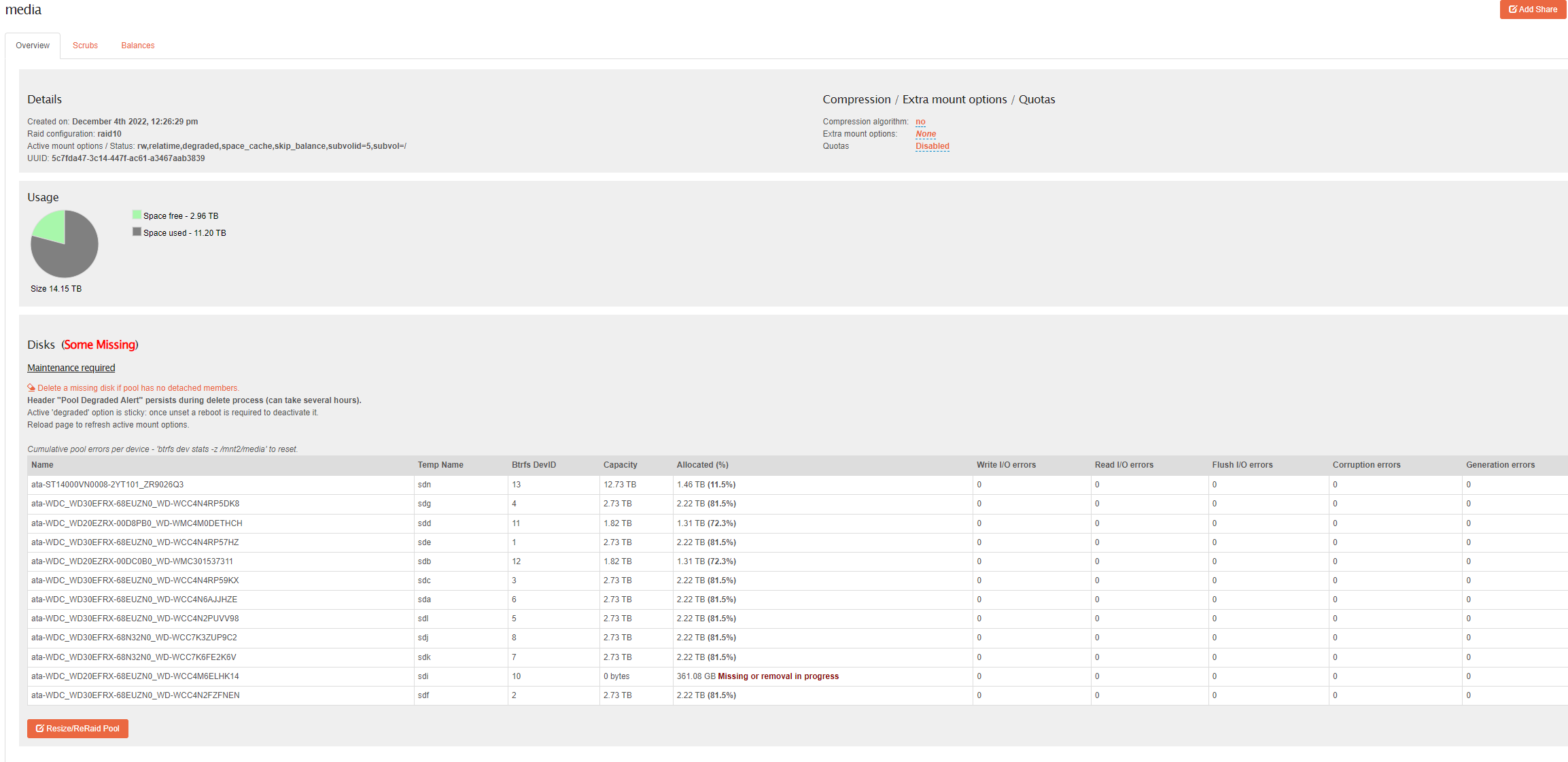
Hhahaha, that was exactly what I decided to do. I have some bigger new 14tb drives and I am planning on replacing the current 3/2TB array with 5*14TB. Right now it is doing the removal/rebalance. After it is done(assuming it lets me remove that one 2tb disk) the plan is to use the slot that one occupied to create a single disk pool with a 14TB one, then copy the data over and delete the old array/pool, then replace it. The setup I had occupied every available slot.
As long as it lets that disk get removed, and keeps it atleast ro after, I should be able to copy the data over. It looks to be running along fine, the allocated % on the disk to be removed has been slowly going down since last night.
Turns out I had more than 1 drive failing there… could not get any operation to complete. I remembered I still had a sata port empty on the motherboard so just connected a 14tb disk to it, made a single disk pool and rsync’ed stuff over.
Then just deleted the fubar’ed pool, swapped hdds for the new ones and then I found out I cant convert a single disk pool to raid 10, so created a new raid 10 pool and now I am rsyncin stuff back to it.
I think this post should be marked as closed. I had that array in a precarious situation and had neglected it for a long time, letting multiple disks fail without taking any action(I also complicated it by reinstalling in the middle). Lesson learned is to not do that.
@fulanodoe Thanks for the ongoing update on your story here. Glad you finally got sorted, even if via a work-around rather than an in-place fix.
Re:
Yes, pools with this many members are key candidates for the only btrfs-raid options that allow for multiple drive failure. See the following doc on the recommendation here regarding pools with many members:
Some noted caveats regarding Rockstor’s Web-UI limitations there but definitely worth considering, at least until our default upstream kernel and btrfs userspace can support these more exotic raid variants.
Once we are settled on our current move to a new build system I’m hoping to pop in some improvements in mixed raid surfacing within the Web-UI, so we will of course welcome testing in that area if that works for you also.
Again, glad you got sorted and it was unfortunate that you got cornered there. Hence the doc pointer on large count pools. As pool member count grows the need to 2 disk failure grows with it.
Also in your case the skip_balance option may have covered up an ongoing balance event, but these events are often the ones that show up issues anyway. So it can at least allow for a ro mount in problem cases that can then, in-turn, help with getting the data off poorly pools.