[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
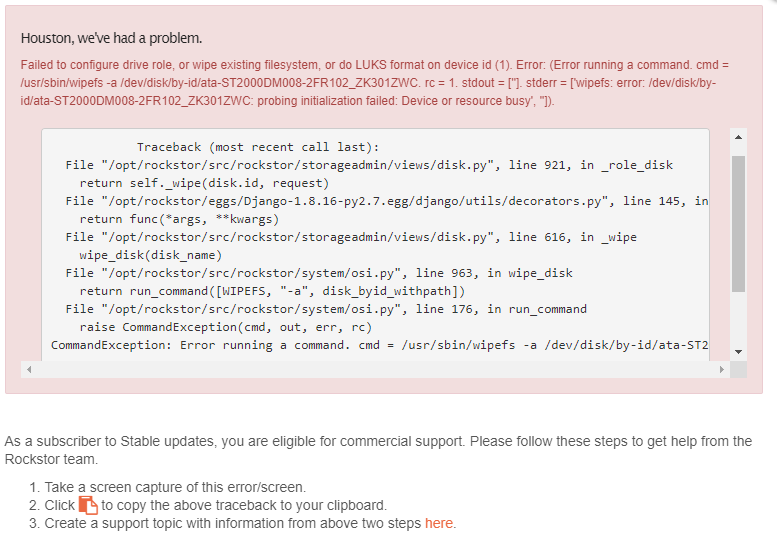
I can’t wipe disks.
Detailed step by step instructions to reproduce the problem
I initially used RAID 5 despite the warning but after some experimentation and more reading I’ve now decided to go with RAID10.
I removed the installled Rock-On, deleted all the SFTP and Samba shares I had created, deleted the Shares and the Pool.
When I tried to create a new pool there were no disks available so I selected a disk and chose to wipe it (tick box).
Yes, this can happen. Btrfs can often fail to ‘drop’ a drive from the ‘busy’ list even when the pool has been deleted. It’s OK when removing a single drive from a pool via resize but when dropping an entire pool a reboot is often required. There is kernel work on-going to improve this type of drive management and that should, in time, make such operations as you did make more sense rather than throwing these resource busy errors.
All in good time and thanks for reporting your findings. Glad you got it sorted. And yes the raid1/10 within btrfs is far more mature, and faster, than the parity raids of 5/6. It’s a little like 2 file systems in one really as the parity raids don’t fully conform to the main remits of btrfs so should probably not have been added. But it’s often easier to fix something that exists than to start over. But we will have to see how things pan out for the parity raids. There is some work going on in that direction but most work seems to be on the 1/10 and there will soon be the btrfs Raid1c2 and Raid1c3 variants that may be interesting. Plus we hope in time to support the capability to pick both data and metadata raid levels independantly. This should help to enable the parity raids feasability a little as then one can use say Raid1c3 for metadata and raid6 for data. Again, all in good time and we are not quite there just yet. And our next move in this area would be to surface within the Web-UI what data and metadata are actually stored in first. The we can use that to proof expanding our capabilities re user configurable data/metadata raid levels down the road.
I haven’t looked into Raid1c2 and Raid 1c3 yet. I remember when there were 5 RAIDs and that was enough for anybody, damn it!
I’m also used to hardware-based RAID but I can see, now, that doing it in software has pros and cons so I have to adapt - and learn.
Also thanks for a great product which, ironically, I came to because it was based on CentOS (which I have a passing familiarity with) at around the time it is moving to SUSE. Not that that will deter me now.