Brief description of the problem
Disk failed, Rockstor won’t allow to wipe or otherwise correct.
Detailed step by step instructions to reproduce the problem
Due to BTRFS issues with RAID 5/6, this is a whole-disk partition on a RAID controller. Disk failure in the RAID set caused the logical disk volume to fail. Now Rockstor won’t allow wiping and restoring the volume.
Web-UI screenshot
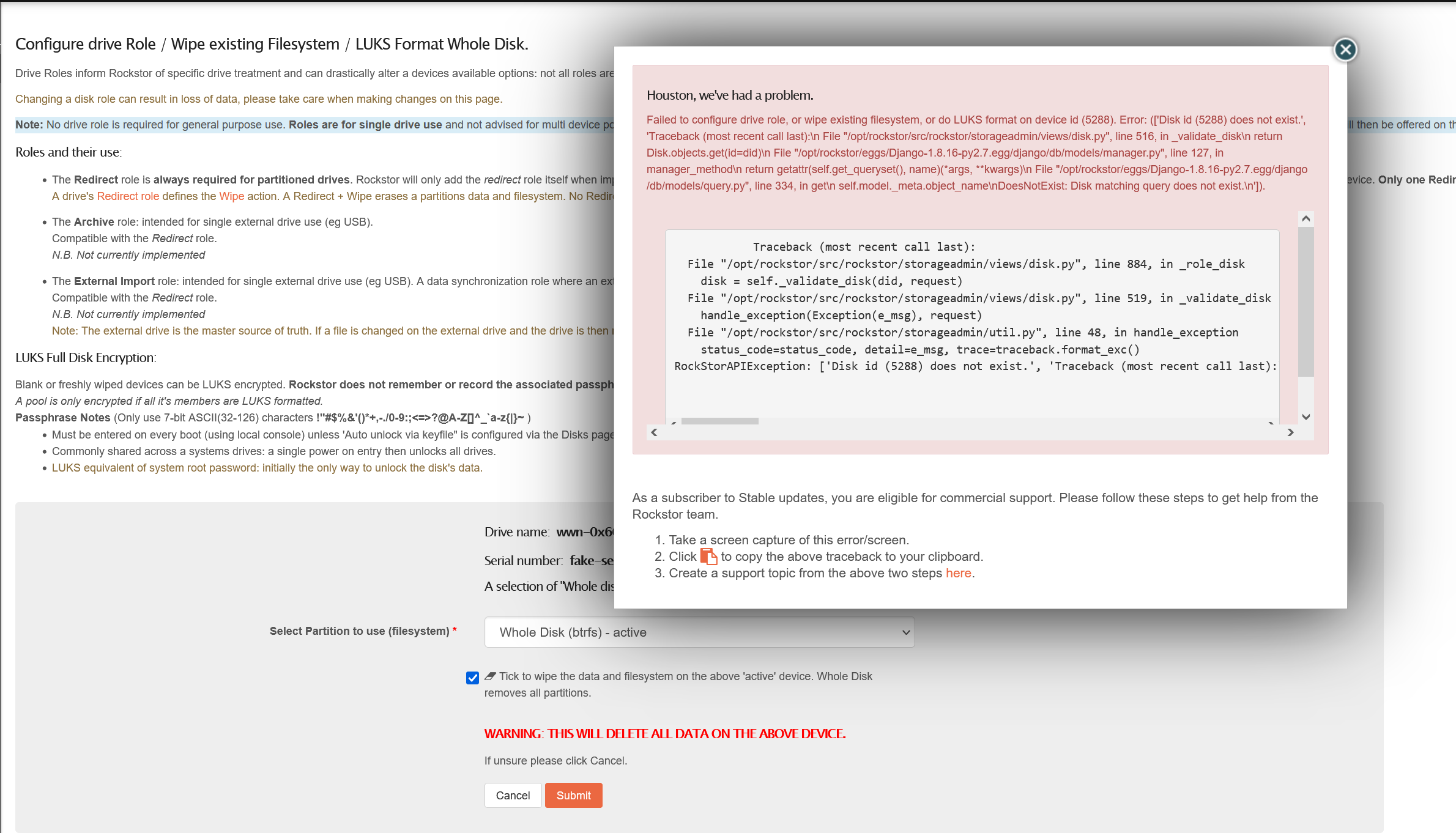
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/storageadmin/views/disk.py”, line 884, in _role_disk
disk = self._validate_disk(did, request)
File “/opt/rockstor/src/rockstor/storageadmin/views/disk.py”, line 519, in _validate_disk
handle_exception(Exception(e_msg), request)
File “/opt/rockstor/src/rockstor/storageadmin/util.py”, line 48, in handle_exception
status_code=status_code, detail=e_msg, trace=traceback.format_exc()
RockStorAPIException: [‘Disk id (5288) does not exist.’, ‘Traceback (most recent call last):\n File “/opt/rockstor/src/rockstor/storageadmin/views/disk.py”, line 516, in _validate_disk\n return Disk.objects.get(id=did)\n File “/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/manager.py”, line 127, in manager_method\n return getattr(self.get_queryset(), name)(*args, **kwargs)\n File “/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/db/models/query.py”, line 334, in get\n self.model._meta.object_name\nDoesNotExist: Disk matching query does not exist.\n’]
So Rockstor apparently needs a bit of work on the crash recovery front. I’m not sure at this point how to make that disk go away in Rockstor and re-attach the new recovered logical disk.