i am in a bit of a panic right now. went to restarting my NAS after after two new disks and the balance was complete and now all rockstor shows my share being deleted and the Pool as being virtually full.
I am running a raid 6 array with 7 drives. Can some one please help me figure out what is wrong… I had about 4-5tb of data that I cannot lose…
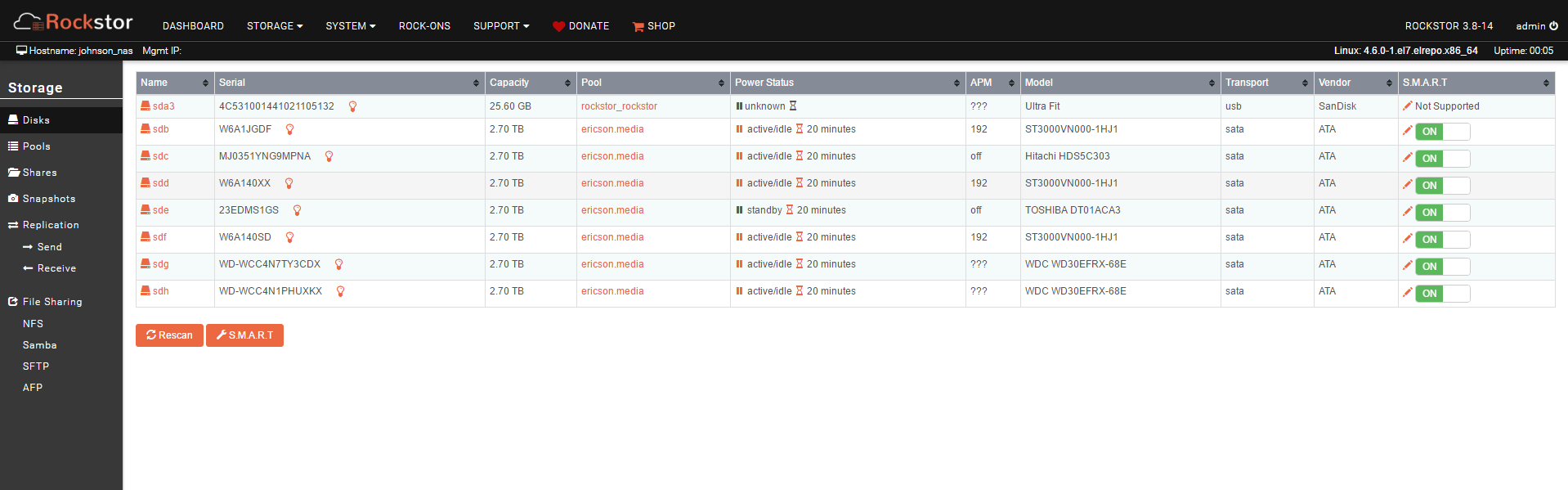
this appears to be the error that i am getting when i try to edit a share.
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 40, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/share.py”, line 170, in post
pqid = qgroup_create(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 549, in qgroup_create
mnt_pt = mount_root(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 142, in mount_root
run_command(mnt_cmd)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 98, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = [’/bin/mount’, ‘/dev/disk/by-label/ericson.media’, ‘/mnt2/ericson.media’, ‘-o’, ‘,compress=no’]. rc = 32. stdout = [’’]. stderr = [‘mount: wrong fs type, bad option, bad superblock on /dev/sdh,’, ’ missing codepage or helper program, or other error’, ‘’, ’ In some cases useful info is found in syslog - try’, ’ dmesg | tail or so.’, ‘’]
Same thing happened to me. Solved after a new balance job. After the balance i deleted the samba export and then i made a new one. Everything is back to normal now.
Another fix is to reinstall the OS, also worked for me. Data is still on the disks and you can import it very easy after installation from the disks tab. Just press the small wheel that sits next to the name of the hard drive and says import data and shares on this drive or something like that.
@soulwise I tried to do a new share and it wouldn’t change anything in the web-ui on the pool in question get the same error message as i previously stated. same for a balance or scrub or really anything touch that pool…
SO I finally got around to doing a re-install of rockstor and now everytime I try to import the new drives i get a spinning loading wheel and then a kernel panic.
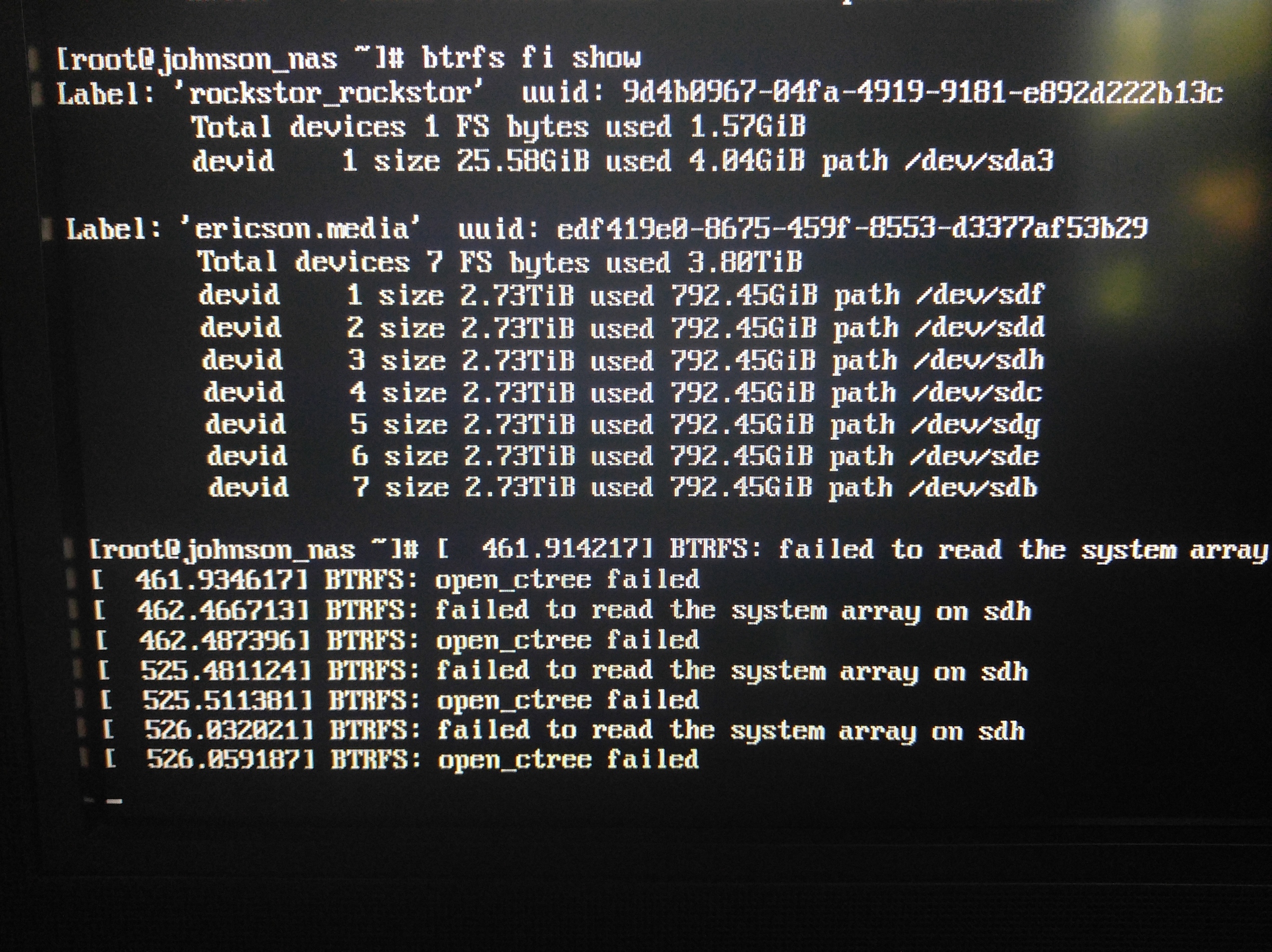
@Eric_Johnson By “new drives” I’m assuming you mean you previous problematic pool. And from the looks of the output from your previous:
btrfs fi show
command all is not well with your pool, ie the messages that related to the drive that was then sdh which may now have a different name.
I would say you look into checking the health of that pool as that does look like the cause of your issues. Ie anything touching the pool previously was problematic and now the admittedly inelegant handling of the failed import attempt. There are moves withing Rockstor to improve elegance in this respect; the start of which is the expansion of our unit testing to incorporate the lower level btrfs command wrappers so that we might improve their resilience without breaking what we already have working. But your issue remains the pool state and currently you are going to have to approach this via the command line. Once the pool is healthy / sorted again, or you have retrieved what data you need from it, you can return to the Web-UI for you management. Currently there are no Rockstor Web-UI tools for pool repair.
Hope that helps.
As a side note how much RAM does this machine have? There are known issues with btrfs raid5/6 that relate to large memory requirements during repair. If that was the router you were to pursue.
@phillxnet yes, the new drives are referring to the old pool. How do I go about checking the health of the pool via CLI.
From what i understand (as i know very little command line) the data is still on the drives, in some sort of state, it’s just finding the proper way to access them.
it only has 4gb which I don’t think qualifies as large amount of RAM.
Only if you are lucky. The production readiness of the parity raids has been at question since it’s introduction and Rockstor’s own documentation (see Redundancy Profiles) has never recommended it for such use and recent bugs found in these parity raid levels have only helped to enforce this. So If the data is no where else and important, as your fist post in this thread indicates, then you best bet is to first attempt data retrieval prior to pool recovery. In brtfs-progs (the non kernel part of btrfs) this is refered to using the term ‘restore’: see Restore - btrfs Wiki
where this option is documented. The basic idea is that you have another known good mount point that is to receive whatever data can be restored / retrieved from the pool, obviously this also needs to be big enough.
The fact that you reported earlier a kernel panic on an attempted import, which involves a mount, would also suggest this is the way to go first.
Hope this points you in the right direction,
As to the ram question, you could see how it goes. If this turns out to be a limiting factor then you can either add more RAM or create a large swap file on an SSD to help mitigate memory pressures if you run into it.