My Rockstor 4.5.8, serves as my home NAS and I have both NFS and SMB shares configured.
Ever since I upgraded to new OPENSUSE installation (from CentOS) I am facing the following strange behaviour:
Whenever I try to access smb shares from my windows machines and the server has been sitting idle for some time, I get timeout errors. Some minutes (or seconds) later, everything is back to normal.
The same time I get the “Windows can’t access shared folder” error; Rockstor web-ui is working normally and so do the NFS shares I am accessing from linux machines.
Mind you that this has not been happening before the upgrade. I should also mention that when I upgraded and imported my backup from previous installation, the smb shares where not imported and I had to setup them from scratch. The NFS were imported and working without issues.
Finally, in my windows machines I did not change a thing (credentials, shortcuts etc).
@Sky12016 on your disks to have an idle time setting that could possibly be slowing the response?
I assume, you have checked out the smb logs, and not seen anything strange on there?
either through WebUi for smbd/nmbd log files or in terminal (they’re located here: /var/log/samba/) which also can show you samba client specific log files?
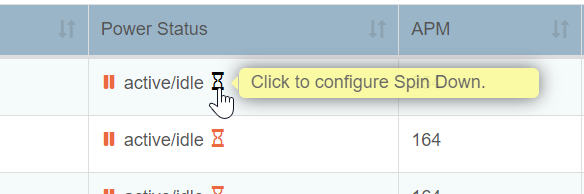
All of my data disks have the default 20 minute setting in idle spin down. It’s the same setting I had before the upgrade. And from what I read in the relevant help text, this should add only a few milliseconds.
I am facing far longer delays.
I will check the logs in /var/log/samba/ as soon as I get back home.
Where can I find the smbd/nmbd log files in the WebUI?
@Sky12016 Hello again, just chipping in on the following:
Re:
If you drives are actually the spinning sort, it’s more like seconds. We have the following text in our Web-UI on this matter:
“Please note that a drives’s initial response time when in standby mode is typically increased by tens of seconds as the disk motor takes time to re-energise the platters.”
Got to System - Logs Manager
We don’t have any active doc entry on this Web-UI element just yet - but it should be fairly self explanatory. We do now have a doc issue open for this short-fall however:
additional time could be added if your controller is set to spin up the drives one at a time. it should be the same from windows vs linux though. perhaps windows gives up sooner? doesnt really sound like it though if you are saying it could be minutes. perhaps centos is defaulting to a different version of smb? I believe there are 3, id try creating an smb share manually with the last two versions and see if this delay happens on both. or possibly your version of cifs-tools is out of date?
The thing is that the same time my windows machines are trying to access the windows shares (unsuccessfully), the nfs exports of the same shares are browsed and playing video perfectly fine from other linux machines!
How can I check that? Shouldn’t that get updated automatically from the official update method?
I will get back to you with the logs as I am still away.
not really sure how you would check it, when you make smb shares add the option vers=3.0, or 2.0. Im not 100% but im pretty sure this is referring to the smb version.
You can of course force the version, as @jihiggs indicated to see whether there is different behavior.
To check what it is using currently for your shares: on the corresponding windows machine connecting to Rockstor, open a PowerShell instance (in administrator mode) and run the command: Get-SmbConnection
The dialect column will tell you what version is being used to communicate between the windows machine and Rockstor. For this example, I had the share mapped to a drive letter on the windows box (persistent), so your mileage may vary if you’re set up differently, but it might be sufficient to have the SMB share open in windows explorer to get a meaningful output from the PowerShell command.
For the currently installed version of the samba package on Rockstor you can do (in the terminal): zypper info samba (my version is 4.15.13+git.636.53d93c5b9d6-150400.3.23.1)
One more edit:
for the above mentioned cifs-tools (aka cifs-utils) you can do the same thing: zypper info cifs-utils (my version is 6.15-150400.3.9.1)
You are correct though, that it should be up-to-date via the normal update paths (from WebUI or via terminal and zypper refresh && zypper up --no-recommends)
While you’re checking on your windows client, can you also look up what the windows side connection time out is?
In PowerShell (run as Administrator): Get-SmbClientConfiguration
One of the entries (towards the end of the list) should be something like: SessionTimeout : 60 (that’s the value in seconds it’s showing for me).
Sorry for the piecemealing here. Finally, I know you mentioned you’re using NFS to connect linux machines to Rockstor. After looking for obvious log entries to see whether you can identify what’s going on, may be you can also use one of your linux instances to connect to Rockstor using samba and see whether you’re also running into that timeout/hanging issue. This might help to identify whether it’s a server vs. client issue …
I assume, for your windows clients you’ve also been doing the normal update/upgrade maintenance over time, so it will be reasonable to assume that those are fairly updated with the most recent patches.
Retrieving repository ‘Rockstor-Stable’ metadata …[error]
Repository ‘Rockstor-Stable’ is invalid.
[Rockstor-Stable|http://b7679531-0bbc-d8f9-536b-a85e45604eb0@updates.rockstor.co m:8999/rockstor-stable/leap/15.4?credentials=/etc/zypp/credentials.d/Rockstor-St able&auth=basic] Valid metadata not found at specified URL
History:
Please check if the URIs defined for this repository are pointing to a valid rep ository.
Warning: Skipping repository ‘Rockstor-Stable’ because of the above error.
Some of the repositories have not been refreshed because of an error.
And after that:
Information for package samba:
Repository : Update repository with updates from SUSE Linux Enterprise 15
Name : samba
Version : 4.15.13+git.636.53d93c5b9d6-150400.3.23.1
Arch : x86_64
Vendor : SUSE LLC https://www.suse.com/
Installed Size : 1.7 MiB
Installed : Yes (automatically)
Status : up-to-date
Source package : samba-4.15.13+git.636.53d93c5b9d6-150400.3.23.1.src
Upstream URL : https://www.samba.org/
Summary : A SMB/CIFS File, Print, and Authentication Server
gives the same error as above
and right after:
Information for package cifs-utils:
Repository : Update repository with updates from SUSE Linux Enterprise 15
Name : cifs-utils
Version : 6.15-150400.3.9.1
Arch : x86_64
Vendor : SUSE LLC https://www.suse.com/
Installed Size : 214.3 KiB
Installed : Yes
Status : up-to-date
Source package : cifs-utils-6.15-150400.3.9.1.src
Upstream URL : http://www.samba.org/linux-cifs/cifs-utils/
Summary : Utilities for doing and managing mounts of the Linux CIFS filesystem
is the same for me at 60 seconds.
Ok so now for the logs. What should I be looking for exactly here?
It seems like the “stable channel” repository is active in your system. However, the current stable 4.1.1-0" only" runs under Leap 15.3, and the above error message indicates it’s looking for the rockstor-stable repository under Leap 15.4 (which it won’t find for now, since we’re still working through the Release Candidates on the testing channel before the next stable version is release in the stable channel, hopefully shortly).
You mentioned above that you have 4.5.8-0 installed. After the installation of 4.5.8 did you set the stable channel or the testing channel?
ah, ok. That’s the discrepancy then. 4.5.8-0 is the prior Release Candidate from the testing channel. To avoid this error and get the next Release Candidate 4.5.9-1 with the latest fixes you should probably switch to the testing channel.
Once, the next stable release (soon) is out, you could then switch back to the stable channel. That way the error message during zypper updates (for all other Leap packages) will not occur anymore. I’ll let @phillxnet comment further on that.
On the files in the samba directory, I would look at the newest smbd and nmbd log files, as well (if you have them) new files that contain the windows computer name that you’re connecting to Rockstor from.
You can probably ignore looking at files with the extension xz and that contain date stamps, as far as I know these are part of the log rotation, and since the symptom you’re seeing occurs all the time, looking at the most recent ones (e.g. today’s date) is probably the easiest (using e.g. ls -ll to see the last modified dates)
Nothing more to say really: bar the (soon) should be in the next few days where I’m hoping we are basically there on the next release which is likely to be 4.6.0-0. If all goes well that will also be ‘promoted’ the being our first stable release and thus we will, finally, be kicking of the next stable channel. We didn’t want to populate the 15.4 repo before we had a ‘proper’ stable release to pop in there. Hence it’s just not htere yet. I should likely have created an actual empty repo but but given we sign our repos and it’s all automated during the publishing of our also signed rpms it actually a little tricky: plus we are so nearly there now: fingers crossed. When will publish the next Release Candidate (RC7) into testing there will be an accompanying post here:
Hope that helps,and my apologies for the non-existent stable repo situation, things have just taken longer than intended. But we are a hairs width away now .
[2023/05/29 22:41:58.885344, 3] …/…/source3/smbd/smb2_server.c:3956(smbd_smb2_request_error_ex)
smbd_smb2_request_error_ex: smbd_smb2_request_error_ex: idx[1] status[STATUS_NO_MORE_FILES] || at …/…/source3/smbd/smb2_query_directory.c:160
[2023/05/29 22:42:09.049905, 3] …/…/source3/smbd/service.c:1131(close_cnum)
windows-pc (ipv4:ipaddress:1969) closed connection to service IPC$
In another log from a different windows machine I find different errors:
[2023/05/29 17:45:13.636038, 3] …/…/lib/util/util_net.c:257(interpret_string_addr_internal)
interpret_string_addr_internal: getaddrinfo failed for name RockstorNAS (flags 34) [Temporary failure in name resolution]
[2023/05/29 17:45:13.636082, 3] …/…/source3/lib/util_sock.c:1036(get_mydnsfullname)
get_mydnsfullname: getaddrinfo failed for name RockstorNAS [Unknown error]
[2023/05/29 17:45:13.565541, 3] …/…/source3/smbd/smb2_server.c:3956(smbd_smb2_request_error_ex)
smbd_smb2_request_error_ex: smbd_smb2_request_error_ex: idx[1] status[NT_STATUS_OBJECT_NAME_NOT_FOUND] || at …/…/source3/smbd/smb2_create.c:337
[2023/05/29 17:45:13.568645, 3] …/…/source3/smbd/smb2_server.c:3956(smbd_smb2_request_error_ex)
smbd_smb2_request_error_ex: smbd_smb2_request_error_ex: idx[1] status[NT_STATUS_ACCESS_DENIED] || at …/…/source3/smbd/smb2_tcon.c:151
[2023/05/29 21:47:40.720251, 3] …/…/source3/smbd/smb2_server.c:3956(smbd_smb2_request_error_ex)
smbd_smb2_request_error_ex: smbd_smb2_request_error_ex: idx[1] status[NT_STATUS_CANCELLED] || at …/…/source3/smbd/smb2_notify.c:126
I also see that there are two log files that are named after the name computer but the one has the local ip address and the other the hostname. The one with the ip address contains multiple appearances of the following:
[2023/05/29 18:19:55.245479, 3] …/…/lib/util/util_net.c:257(interpret_string_addr_internal)
interpret_string_addr_internal: getaddrinfo failed for name RockstorNAS (flags 34) [Name or service not known]
[2023/05/29 18:19:55.245571, 3] …/…/source3/lib/util_sock.c:1036(get_mydnsfullname)
get_mydnsfullname: getaddrinfo failed for name RockstorNAS [Unknown error]
and there are also some login errors:
[2023/05/29 22:05:24.299035, 2] …/…/source3/auth/auth.c:348(auth_check_ntlm_password)
check_ntlm_password: Authentication for user [nistsio] → [nistsio] FAILED with error NT_STATUS_WRONG_PASSWORD, authoritative=1
which are incomprehensible since the user/password combination is correct and moments later the login goes through!
A quick thought that may deserve to be ruled out:
How is the windows machine showing this issue connected to your LAN?
The reason I’m asking is that these errors and the symptoms you describe seem to indicate a connection failure between the client and server, and I know Windows can sometimes be aggressive in disabling some devices for the sale of power savings.
I’m especially wondering about Ethernet/wifi/USB adapter, etc…
It’s a long shot but worth ruling out now.
EDIT: similarly, any relevant detail on your network could prove useful: local DNS server or anything of the sort, by any chance?
is actually not an error, it means success … I believe it essentially just states that no more files were found when looking in a given directory, after listing all the existing ones (like an eof within a file).
the NT_STATUS_OBJECT_NAME_NOT_FOUND had some bug associated with it last year, that was apparently fixed in the 4.14 Samba version (not sure this is the same thing), but in some other instances they apparently pointed to some permission issues not being visible correctly in samba or messed up in the actual share… I assume, the files on your samba shares have the “appropriate” user/group setups, so a logged in user has the correct access and is not timing out. Though this is a long shot, since you’ve mentioned that this is an intermittent state and then you have access like usual.
So, back to @Flox question whether you have anything specific set up in your network that might interfere …