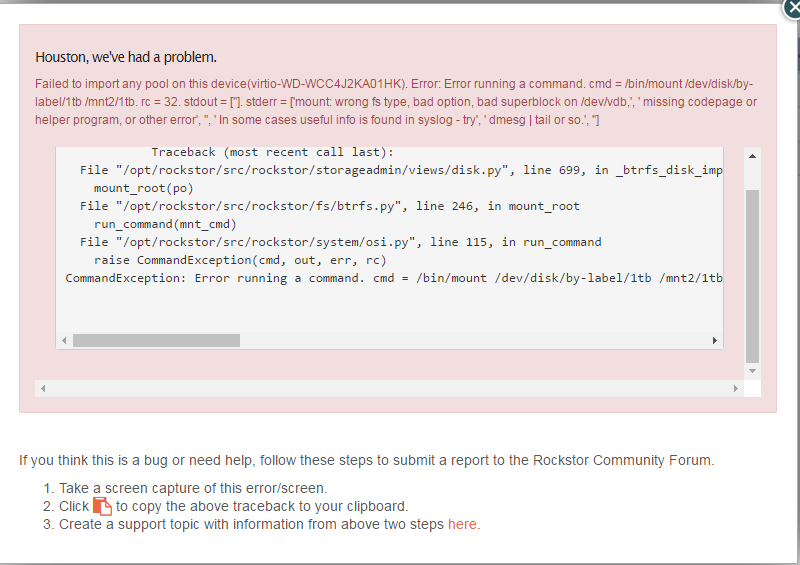
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/storageadmin/views/disk.py", line 699, in _btrfs_disk_import
mount_root(po)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 246, in mount_root
run_command(mnt_cmd)
File "/opt/rockstor/src/rockstor/system/osi.py", line 115, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /bin/mount /dev/disk/by-label/1tb /mnt2/1tb. rc = 32. stdout = ['']. stderr = ['mount: wrong fs type, bad option, bad superblock on /dev/vdb,', ' missing codepage or helper program, or other error', '', ' In some cases useful info is found in syslog - try', ' dmesg | tail or so.', '']
Thanks!
EDIT: Tried running the following command:
[root@rockstor ~]# btrfs check /dev/vdb
checksum verify failed on 883916800 found EC6DD33F wanted 000002A8
checksum verify failed on 883916800 found EC6DD33F wanted 000002A8
bytenr mismatch, want=883916800, have=68719477456
Couldn’t read tree root
ERROR: cannot open file system
[root@rockstor ~]#
Is it safe to run a btrfs restore?
EDIT2: I manages to mount the drive manually using:
mount -o rw,degraded,recovery /dev/vdb /mnt2/1tb
Then, I was able to import the Pool in the GUI.
This thread can be closed. I’ll leave this here, for anybody having the same problem.
Could somebody explain, why and how this could happen?
@JannikJung0 Hello again and thanks for the report.
Were the drives part of the same pool I’m assuming so. If so then your first error:
CommandException: Error running a command. cmd = /bin/mount /dev/disk/by-label/1tb /mnt2/1tb. rc = 32. stdout = ['']. stderr = ['mount: wrong fs type, bad option, bad superblock on /dev/vdb,', ' missing codepage or helper program, or other error', '', ' In some cases useful info is found in syslog - try', ' dmesg | tail or so.', '']
Can result from a know issue with mount by label (which we initially try) on multi disk pools:
That issue references the btrfs wiki that describes this known behaviour / bug.
As it goes this is what I’m working on currently. Essentially if one first executes a:
btrfs device scan
then the issue is averted. As this is overkill for every pool mount ‘on the fly’ which is where we are heading capabilities wise, I’m implementing an ‘all pool disks only’ scan first, rather than a system wide one. So given you may have effectively ‘live plugged’ some disks via your use of a VM that command may have helped to avert this problem.
Often if time permits (it can take ages) and the only copy of the data resides on the normally un-mountable pool then the restore feature is the first port of call as any repair actions can make things worse. See: https://btrfs.wiki.kernel.org/index.php/Restore
The btrfs restore utility is a non-destructive method for attempting to recover data from an unmountable filesystem. It
makes no attempt to repair the filesystem, which means that you cannot cause further damage by running it. It is
available as part of btrfs-progs.
You state having first tried:
We have to be very careful recommending such action as in some circumstance this is a one shot deal, ie you get one attempt to make repairs in rw mode to the mounted pool. If those repairs are not enacted in that first rw,degraded mount then you will there after not be able to remount the pool in any mode other than ro. Also recovery is a deprecated option: https://btrfs.wiki.kernel.org/index.php/Mount_options
recovery (since 3.2)
(Deprecated in 4.6-rc1) Enable autorecovery upon mount; currently it scans list of several previous tree roots and tries
to use the first readable. The information about the tree root backups is stored by kernels starting with 3.2, older
kernels do not and thus no recovery can be done. Replaced by usebackuproot in 4.6-rc1, but still works.
If you in fact mounted one drive rw,degraded as the other was not yet visible to the system (see above btrfs device scan) then you could have inadvertently put the two drives out of sync, as suggested by the btrfs check command. But this is not consistent with your reported order.
Btrfs the filesystem and Rockstor, each for their own reasons (some interrelated), have issues with dynamic drive arrangements. I suspect your Proxmox use and lack of a reboot / use of btrfs device scan after disk changes, may have lead to this issue, ie only one drives btrfs nature visible (no indications of such between steps 2 and 3). There are also know issues with udev in this circumstance but I’m pretty sure we have those sorted now via, please see:
for where we demonstrated the effect of btrfs formats not showing up. That however should have been addressed in the consequent changes in:
which should have already been in your Rockstor version, unless you used a really old one of course.
Dynamic drive management and filesystems on top of such is not an easy problem. Always best to have the final hw arrangement established on a fresh boot prior to an import, especially on multi drive pools. But as indicated we are working towards greater robustness in such situations and this is also a focus at Facebook this year for the btrfs team, ie multi disk pools.
Hope that helps and I realise this is not an explanation but I am not a btrfs expert. Just wanted to chip in on advising against the order you promote here.
I’m chuffed you have your data access up and running again however I would caution, given the above, that you make sure your backups are in place and up to date prior to a reboot / re-mount. Just in case. Especially given the rw,degraded mount execution.
Well done on getting it sorted, can be quite a worry but we have many moving parts here, however btrfs raid1 is normally pretty forgiving, especially while current drive count meets or exceeds the minimum of 2 and hopefully I’ll have the additional use of ‘btrfs device scan’ in Rockstor ready for review shortly.
Obviously the longer term aim is to have Rockstor’s Web UI help more ‘guidance wise’ in these failure scenarios. However it is not an easy problem to solve elegantly across all scenarios but the work towards this is under way.