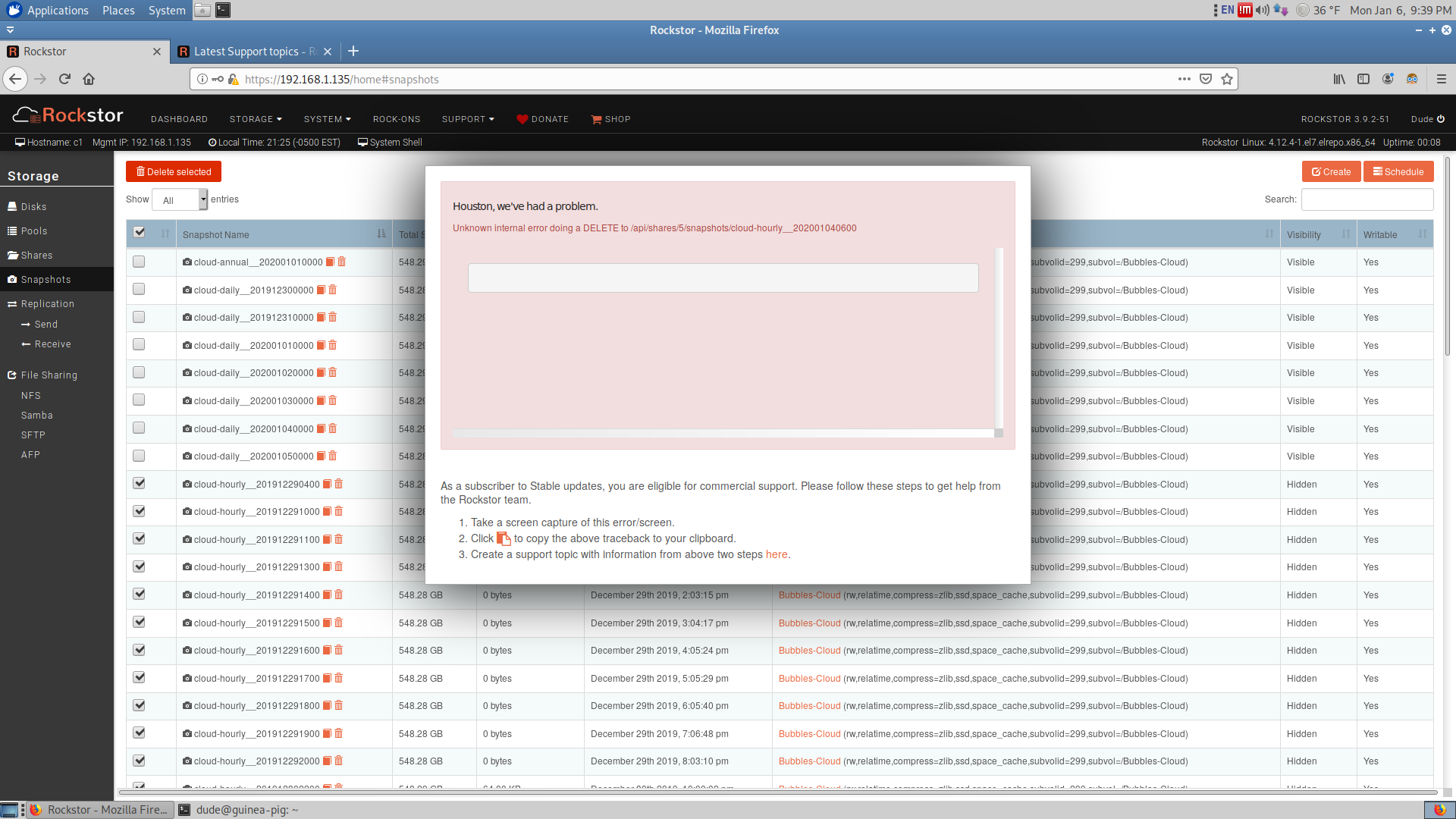
Gracias Flox. Quotas were enabled on the boot pool (rockstor_rockstor), which I disabled. The main file share pool (Bubbles-Cloud) already had quotas disabled in the anticipation that (in my [lack of] understanding of BtrFS snapshots) I would be having numerous instances of snapshots taking place on the shared pool in use.
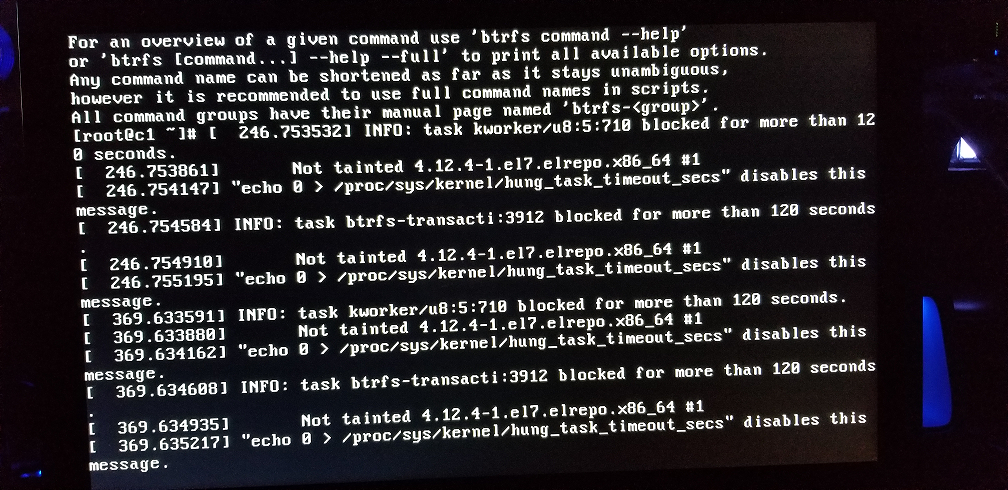
I forgot to mention that typically when I’m making use of the shell or web GUI I notice as the slow down/lock up occurs, the HD LED activity increases until solid for a few moments, then goes dark as a further data point. If I reboot the NAS without establishing a connection initially, I’m simply unable to connect though intermittent/sporadic HD LED activity still occurs (which is the state the NAS is in currently).  I’m reluctant to reboot to reconnect further until either directed to, or my Pez dispenser full of xanax runs out… whichever takes place first (and my monthly Pill Pack just arrived).
I’m reluctant to reboot to reconnect further until either directed to, or my Pez dispenser full of xanax runs out… whichever takes place first (and my monthly Pill Pack just arrived).
The statements I was able to execute:
btrfs subvolume list /mnt2/Bubbles-Cloud/ | wc -l
btrfs fi usage /mnt2/Bubbles-Cloud/
btrfs subvolume list /mnt2/rockstor_rockstor/ | wc -l
btrfs fi usage /mnt2/rockstor_rockstor/
The statements I was unable to execute:
btrfs subvolume list /mnt2/home/ | wc -l
btrfs fi usage /mnt2/home/
btrfs subvolume list /mnt2/Cloudy-Bubbles/ | wc -l
btrfs fi usage /mnt2/Cloudy-Bubbles/
The results of the cli commands are:
Boot Device:
root@c1 ~]# btrfs subvolume list /mnt2/rockstor_rockstor/ | wc -l
3
root@c1 ~]# btrfs fi usage /mnt2/rockstor_rockstor/
Overall:
Device size: 110.94GiB
Device allocated: 8.06GiB
Device unallocated: 102.88GiB
Device missing: 0.00B
Used: 2.50GiB
Free (estimated): 106.49GiB (min: 55.06GiB)
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 16.00MiB (used: 0.00B)
Data,single: Size:6.00GiB, Used:2.38GiB
/dev/nvme0n1p3 6.00GiB
Metadata,DUP: Size:1.00GiB, Used:57.83MiB
/dev/nvme0n1p3 2.00GiB
System,DUP: Size:32.00MiB, Used:16.00KiB
/dev/nvme0n1p3 64.00MiB
Unallocated:
/dev/nvme0n1p3 102.88GiB
RAID5:
root@c1 ~]# btrfs subvolume list /mnt2/Bubbles-Cloud/ | wc -l
67
root@c1 /]# btrfs fi usage /mnt2/Bubbles-Cloud/
Overall:
Device size: 4.66TiB
Device allocated: 1.38TiB
Device unallocated: 3.27TiB
Device missing: 0.00B
Used: 1.29TiB
Free (estimated): 3.37TiB (min: 1.73TiB)
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 512.00MiB (used: 1.39MiB)
Data,single: Size:1.38TiB, Used:1.28TiB
/dev/md127 1.38TiB
Metadata,DUP: Size:4.00GiB, Used:2.55GiB
/dev/md127 8.00GiB
System,DUP: Size:40.00MiB, Used:176.00KiB
/dev/md127 80.00MiB
Unallocated:
/dev/md127 3.27TiB