Brief description of the problem
Processing: Screen Shot 2023-09-25 at 11.30.22 PM.png…
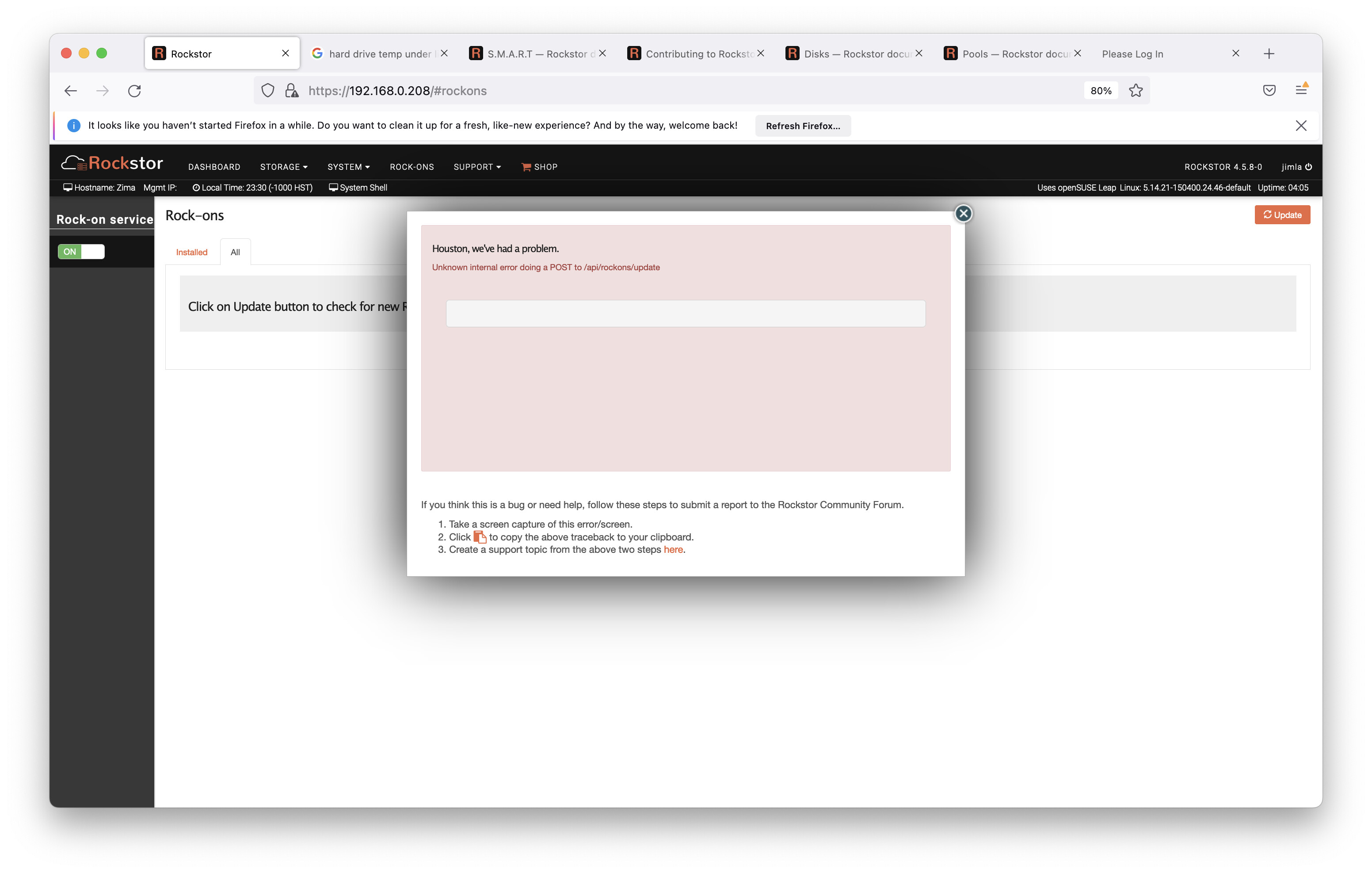
ROCK-ONS non-functional, can not complete Rock-Ons Update to load in list of docker programs. Suggested fix for this problem no longer available. Lost ability to start all my rockons after updating system - #8 by sanderweel
Old fix install an older version of docker:
sudo zypper install --oldpackage docker-19.03.15_ce-lp152.2.9.1.x86_64
“Package ‘docker-19.03.15_ce-lp152.2.9.1.x86_64’ not found.”
Detailed step by step instructions to reproduce the problem
Installing Rockstor-Leap15.4-generic.x86_64-4.5.8-0.install.iso
Done three clean installs to 8gb ZimaBoard, installing exactly as YouTube video did, install to home directory. Another clean Install I created a special Rock-Ons-root share on a non-boot SSD as Rockstor online doc suggested. With all the installs I noticed on the Rock-Ons tab page it says Rock-Ons service is not running, even when Services and the Rock-Ons tab page say it is on. So I turn it off and then back on to make it happy so I can get to the Update button. I press the Update and after a long wait I get the unknown error. I tried the suggest fix for the problem and the old docker file is no long available.
Even work around on how to remove the Rockstor docker software and installing standard docker alone avoiding the problem would be helpful.
Web-UI screenshot
[Drag and drop the image here]
Error Traceback provided on the Web-UI
none