Brief description of the problem
I have a single pool called Main on six LUKS-encrypted 6TB HDDs.
I have a few users and shares set up, among them this share called Media and a user named media that used to own the share.
At some point, “something happened” that caused all my shares to be reset to owner root and group root. I believe that they were also renumbered, in the incident.
Now, when I try to change the ownership of share Media back to media, I get an error message about an internal error with an empty traceback.
Detailed step by step instructions to reproduce the problem
I don’t know exactly how this happened.
I believe that the cause may have been that I tried adding an enclosure to the running system and while I was trying to plug the second SAS cable into the RAID controller, I may have bumped the first one, going to the existing, internal enclosure. So the system may have lost all the existing HDDs very temporarily.
I never saw an error message about this, though, and it’s too long ago to still find anything in the logs.
Web-UI screenshot
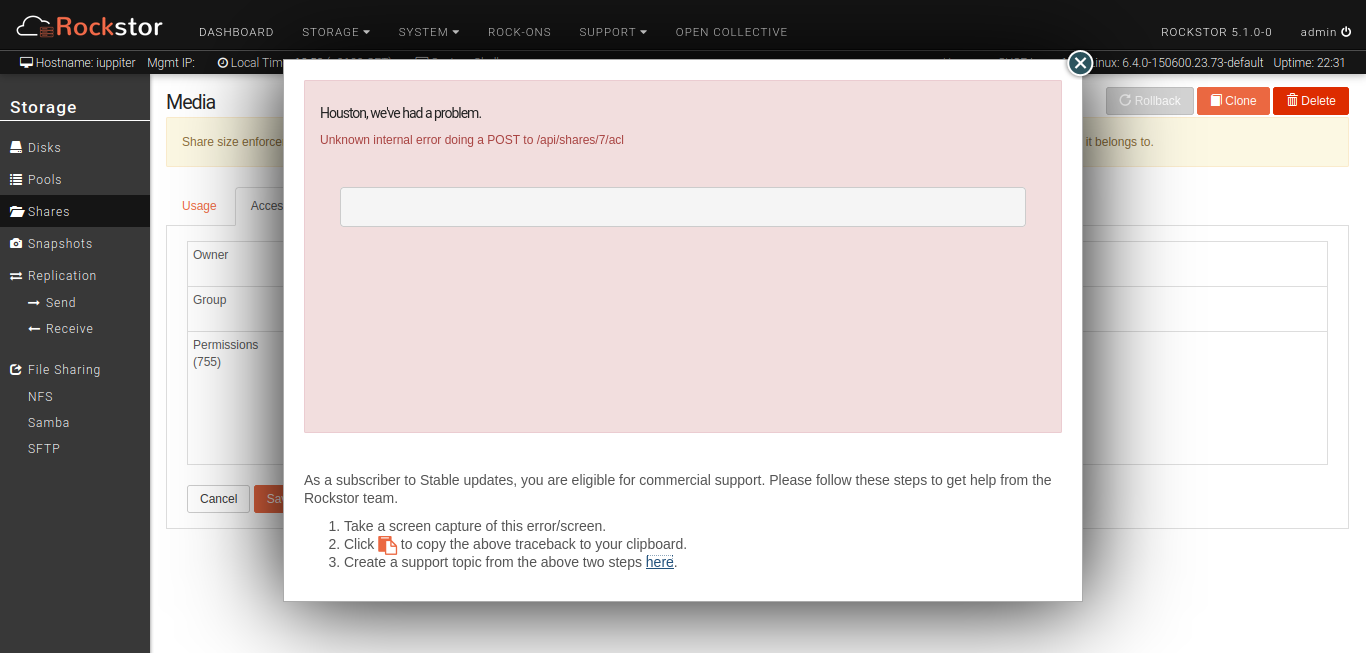
Error Traceback provided on the Web-UI is unfortunately empty
I found nothing relevant in rockstor.log, supervisord.log or other log files. Only gunicorn.log has the POST request, but nothing more:
127.0.0.1 - - [18/Nov/2025:13:54:30 +0100] "POST /api/shares/7/acl HTTP/1.0" 200 7741 "https://iuppiter.internal/" "Mozilla/5.0 (X11; Linux x86_64; rv:144.0) Gecko/20100101 Firefox/144.0" 286353ms
The only notable thing about the above log entry is that the request took over four and a half minutes…
I know this is not much to go on, but I’m willing to help in debugging this in any way I can, including not only posting log entries and configs, but running CLI commands and even going into manage.py shell and running any Python/Django commands that might help.
I have to admit, though, that I don’t really understand how share ownership actually works “under the hood” in Rockstor. I know that a pool is a btrfs filesystem and a share is essentially just a subvolume therein. But there’s more to it than that, isn’t there?
E.g. users get the shares they have access to mounted into their login dirs and things like that.
Needless to say that none of this currently works with my shares.