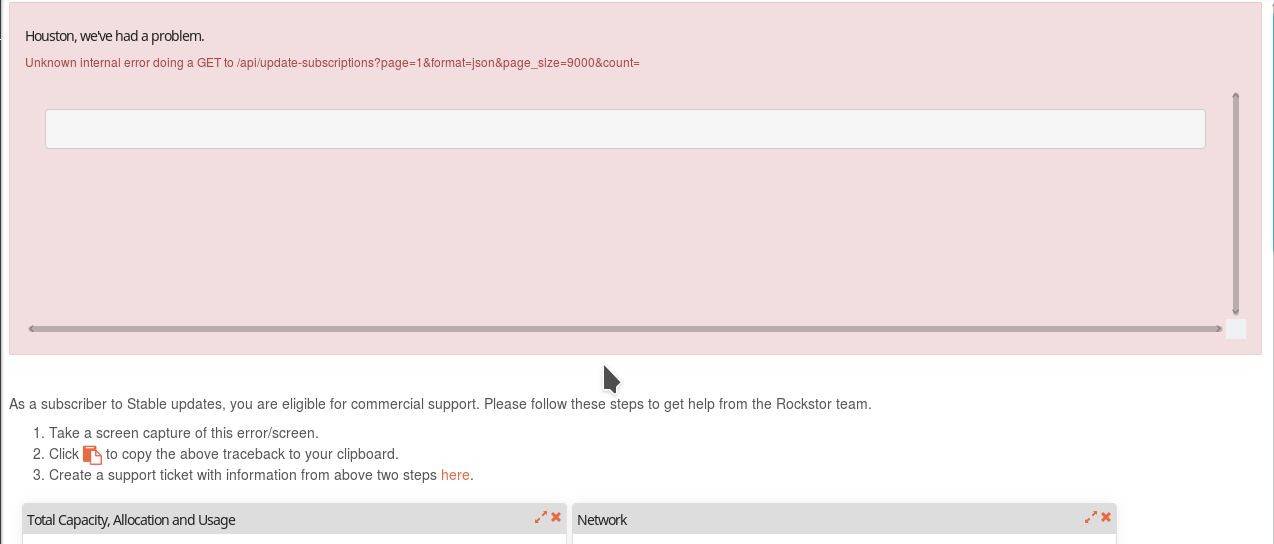
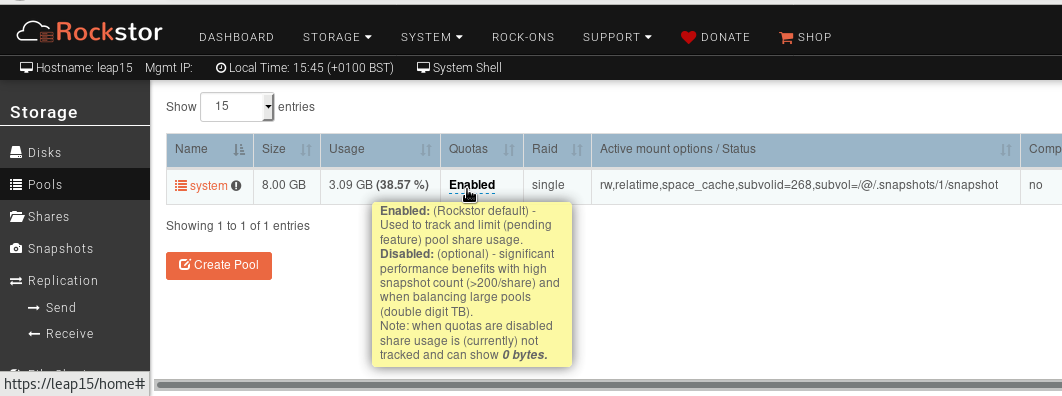
Thank you for the kind advice, Flox. I double checked the disk usage, and capacity doesn’t look to be the issue on my system.
Bellow shows the size of the two pools in this Rockstor instance:
Filesystem Size Used Avail Use% Mounted on
devtmpfs 12G 0 12G 0% /dev
tmpfs 12G 0 12G 0% /dev/shm
tmpfs 12G 8.8M 12G 1% /run
tmpfs 12G 0 12G 0% /sys/fs/cgroup
/dev/sdc3 128G 5.4G 121G 5% /
/dev/sdc3 128G 5.4G 121G 5% /home
/dev/sdc1 477M 139M 309M 32% /boot
/dev/sdb 5.1T 185G 4.4T 4% /mnt2/RAID1-A
/dev/sdc3 128G 5.4G 121G 5% /mnt2/rockstor_rockstor
tmpfs 2.4G 0 2.4G 0% /run/user/0
...
/dev/sdb 5.1T 185G 4.4T 4% /mnt2/A1-RockOns
Hopefully your advice help someone. I’m still searching. And looking for anything that could give more clues, I tried running the following script from /var/rockstor/bin which shows a possible network issue. But I haven’t installed any firewall manually over the base install. The only packages I recall installing may be vim, nmap, and netcat.
~ # ./bootstrap
BTRFS device scan complete
Error connecting to Rockstor. Is it running?
Exception occured while bootstrapping. This could be because rockstor.service is still starting up. will wait 2 seconds and try again. Exception: HTTPConnectionPool(host='127.0.0.1', port=8000): Max retries exceeded with url: /api/commands/bootstrap (Caused by <class 'httplib.BadStatusLine'>: '')
Error connecting to Rockstor. Is it running?
Anyway, the rockstor service appears to be running. So I’m still searching ATM:
~ # systemctl status rockstor
● rockstor.service - RockStor startup script
Loaded: loaded (/etc/systemd/system/rockstor.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2018-09-23 16:49:58 PDT; 31min ago
Main PID: 2984 (supervisord)
CGroup: /system.slice/rockstor.service
├─ 2984 /usr/bin/python /opt/rockstor/bin/supervisord -c /opt/rockstor/etc/supervisord.conf
├─ 2995 nginx: master process /usr/sbin/nginx -c /opt/rockstor/etc/nginx/nginx.conf
├─ 2996 /usr/bin/python /opt/rockstor/bin/gunicorn --bind=127.0.0.1:8000 --pid=/run/gunicorn.pid --wor...
├─ 2997 /usr/bin/python /opt/rockstor/bin/data-collector
├─ 2998 /usr/bin/python2.7 /opt/rockstor/bin/django ztaskd --noreload --replayfailed -f /opt/rockstor/...
├─ 2999 nginx: worker process
├─ 3000 nginx: worker process
├─22505 /usr/bin/python /opt/rockstor/bin/gunicorn --bind=127.0.0.1:8000 --pid=/run/gunicorn.pid --wor...
├─29403 /usr/bin/python /opt/rockstor/bin/gunicorn --bind=127.0.0.1:8000 --pid=/run/gunicorn.pid --wor...
└─29405 /sbin/btrfs fi show /dev/disk/by-id/ata-TOSHIBA_MD04ACA500_35OBK0EWFS9A
Sep 23 16:49:58 r2d2 supervisord[2984]: 2018-09-23 16:49:58,365 CRIT Server 'unix_http_server' running witho...cking
Sep 23 16:49:58 r2d2 supervisord[2984]: 2018-09-23 16:49:58,365 INFO supervisord started with pid 2984
Sep 23 16:49:59 r2d2 supervisord[2984]: 2018-09-23 16:49:59,368 INFO spawned: 'nginx' with pid 2995
Sep 23 16:49:59 r2d2 supervisord[2984]: 2018-09-23 16:49:59,370 INFO spawned: 'gunicorn' with pid 2996
Sep 23 16:49:59 r2d2 supervisord[2984]: 2018-09-23 16:49:59,371 INFO spawned: 'data-collector' with pid 2997
Sep 23 16:49:59 r2d2 supervisord[2984]: 2018-09-23 16:49:59,373 INFO spawned: 'ztask-daemon' with pid 2998
Sep 23 16:50:01 r2d2 supervisord[2984]: 2018-09-23 16:50:01,384 INFO success: data-collector entered RUNNING...secs)
Sep 23 16:50:01 r2d2 supervisord[2984]: 2018-09-23 16:50:01,384 INFO success: ztask-daemon entered RUNNING s...secs)
Sep 23 16:50:04 r2d2 supervisord[2984]: 2018-09-23 16:50:04,388 INFO success: nginx entered RUNNING state, p...secs)
Sep 23 16:50:04 r2d2 supervisord[2984]: 2018-09-23 16:50:04,388 INFO success: gunicorn entered RUNNING state...secs)
Hint: Some lines were ellipsized, use -l to show in full.
And strange enough, the port seems to be open. So perhaps it’s just not operating as needed:
~ # nmap -p 8000 -P0 127.0.0.1
Starting Nmap 6.40 ( http://nmap.org ) at 2018-09-23 17:30 PDT
Nmap scan report for localhost (127.0.0.1)
Host is up (0.000061s latency).
PORT STATE SERVICE
8000/tcp open http-alt
I’m turning on debugging and will reboot to look further at the logs:
~ # ./debug-mode on
DEBUG flag is now set to True
I’ll keep this post updated on any further details.