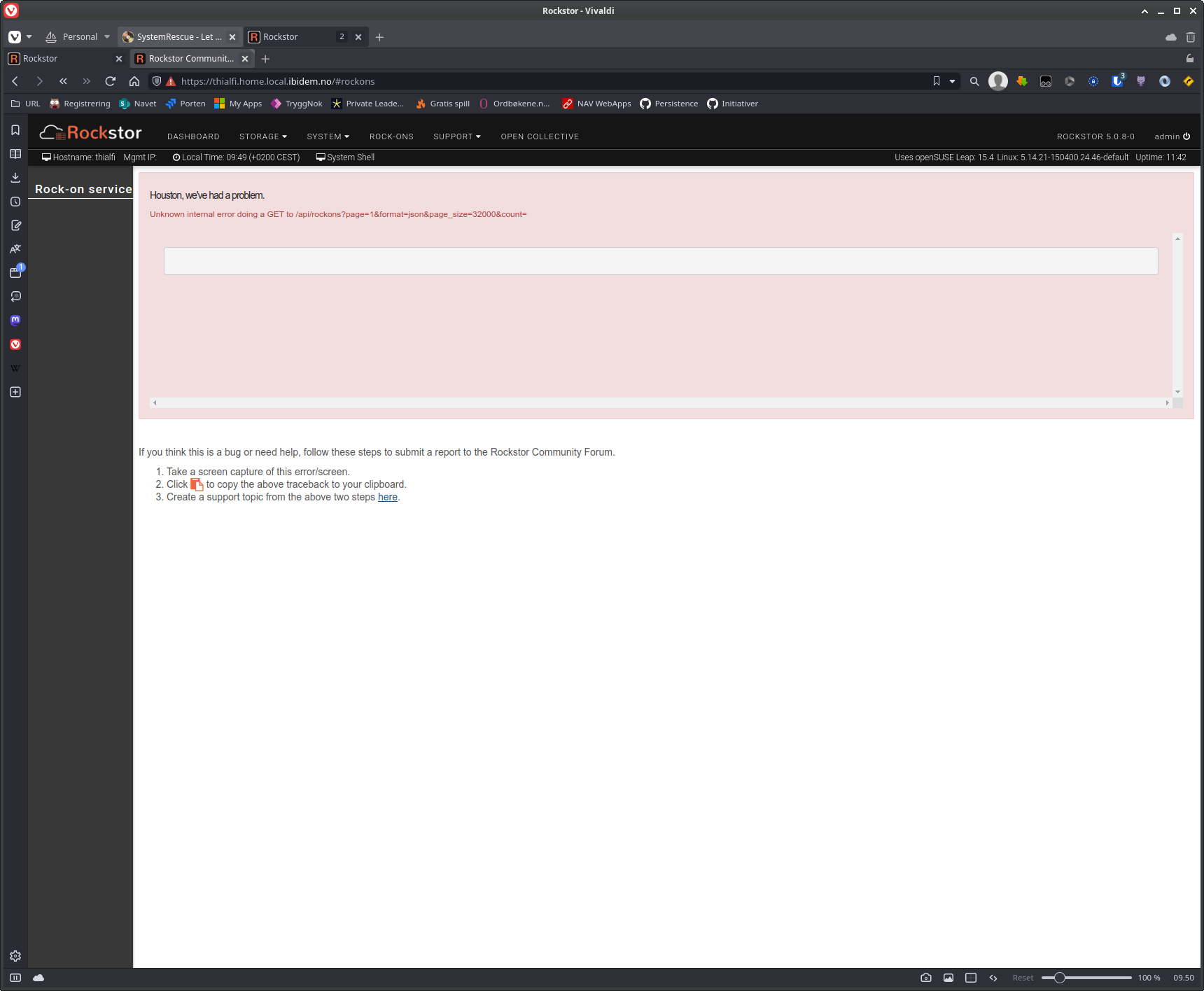
I have been poking around more, instead of doing my paid work ( ), because I thought it was weird that it seems to be only the WebUI that is slow.
), because I thought it was weird that it seems to be only the WebUI that is slow.
Found some logs that I think are strange, but I don’t know what could cause it, or if it is related to the problems I’m seeing.
From /opt/rockstor/var/log/supervisord_data-collector_stderr.log:
Traceback (most recent call last):
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connectionpool.py", line 536, in _make_request
response = conn.getresponse()
^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connection.py", line 461, in getresponse
httplib_response = super().getresponse()
^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.11/http/client.py", line 1378, in getresponse
response.begin()
File "/usr/lib64/python3.11/http/client.py", line 318, in begin
version, status, reason = self._read_status()
^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.11/http/client.py", line 279, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), "iso-8859-1")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib64/python3.11/socket.py", line 706, in readinto
return self._sock.recv_into(b)
^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib64/python3.11/site-packages/gevent/_socketcommon.py", line 696, in recv_into
self._wait(self._read_event)
File "src/gevent/_hub_primitives.py", line 317, in gevent._gevent_c_hub_primitives.wait_on_socket
File "src/gevent/_hub_primitives.py", line 322, in gevent._gevent_c_hub_primitives.wait_on_socket
File "src/gevent/_hub_primitives.py", line 313, in gevent._gevent_c_hub_primitives._primitive_wait
File "src/gevent/_hub_primitives.py", line 314, in gevent._gevent_c_hub_primitives._primitive_wait
File "src/gevent/_hub_primitives.py", line 46, in gevent._gevent_c_hub_primitives.WaitOperationsGreenlet.wait
File "src/gevent/_hub_primitives.py", line 46, in gevent._gevent_c_hub_primitives.WaitOperationsGreenlet.wait
File "src/gevent/_hub_primitives.py", line 55, in gevent._gevent_c_hub_primitives.WaitOperationsGreenlet.wait
File "src/gevent/_waiter.py", line 154, in gevent._gevent_c_waiter.Waiter.get
File "src/gevent/_greenlet_primitives.py", line 61, in gevent._gevent_c_greenlet_primitives.SwitchOutGreenletWithLoop.switch
File "src/gevent/_greenlet_primitives.py", line 61, in gevent._gevent_c_greenlet_primitives.SwitchOutGreenletWithLoop.switch
File "src/gevent/_greenlet_primitives.py", line 65, in gevent._gevent_c_greenlet_primitives.SwitchOutGreenletWithLoop.switch
File "src/gevent/_gevent_c_greenlet_primitives.pxd", line 35, in gevent._gevent_c_greenlet_primitives._greenlet_switch
TimeoutError: timed out
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/adapters.py", line 486, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connectionpool.py", line 844, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/util/retry.py", line 470, in increment
raise reraise(type(error), error, _stacktrace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/util/util.py", line 39, in reraise
raise value
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connectionpool.py", line 790, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connectionpool.py", line 538, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File "/opt/rockstor/.venv/lib/python3.11/site-packages/urllib3/connectionpool.py", line 370, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPConnectionPool(host='127.0.0.1', port=8000): Read timed out. (read timeout=2)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/cli/api_wrapper.py", line 66, in set_token
response = requests.post(
^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/api.py", line 115, in post
return request("post", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/.venv/lib/python3.11/site-packages/requests/adapters.py", line 532, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPConnectionPool(host='127.0.0.1', port=8000): Read timed out. (read timeout=2)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "src/gevent/greenlet.py", line 908, in gevent._gevent_cgreenlet.Greenlet.run
File "/opt/rockstor/src/rockstor/smart_manager/data_collector.py", line 1048, in prune_logs
self.aw.api_call(
File "/opt/rockstor/src/rockstor/cli/api_wrapper.py", line 85, in api_call
self.set_token()
File "/opt/rockstor/src/rockstor/cli/api_wrapper.py", line 81, in set_token
raise Exception(msg)
Exception: Exception while setting access_token for url(http://127.0.0.1:8000): HTTPConnectionPool(host='127.0.0.1', port=8000): Read timed out. (read timeout=2). content: None
2024-04-02T13:30:34Z <Greenlet at 0x7f1e4a4e76a0: <bound method SysinfoNamespace.prune_logs of <smart_manager.data_collector.SysinfoNamespace object at 0x7f1e5069f5d0>>> failed with Exception