Hello and happy new year! 
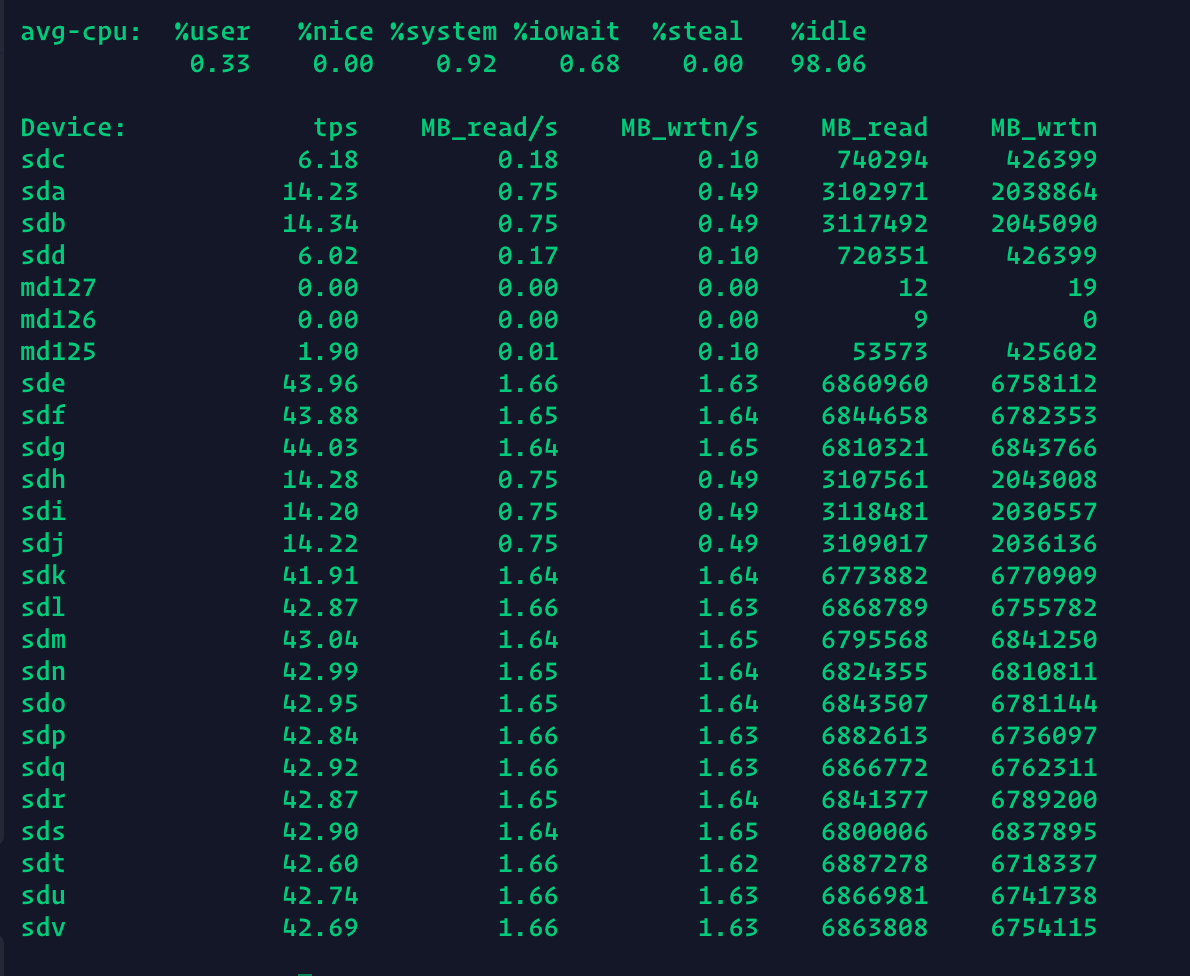
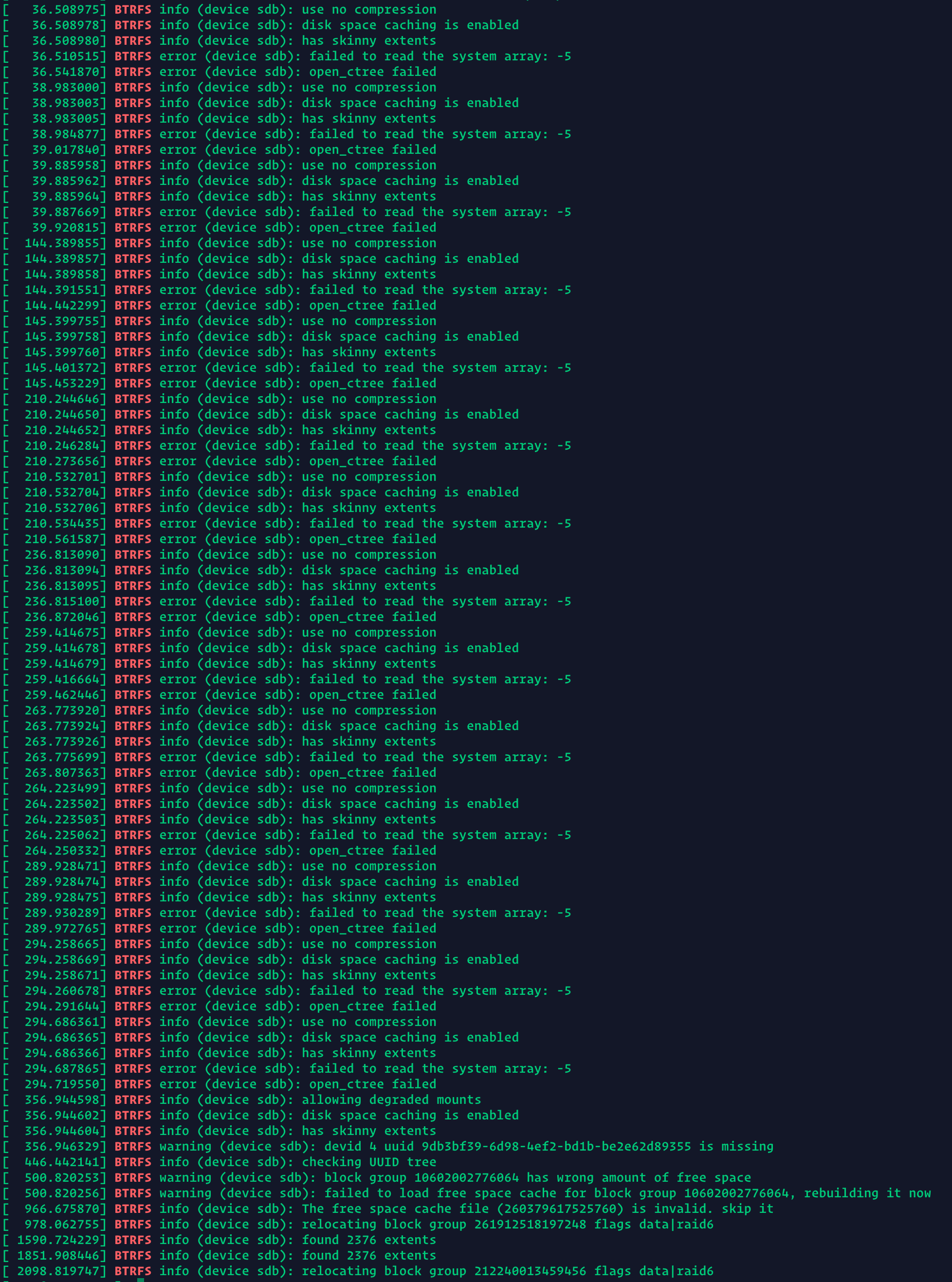
I’ve been observed for the last week the system becomes unresponsive for some seconds but only when I’m copying something over NFS. There is no error in the btrfs dash but when I’ve checked the /var/log/messages I’ve seen that there are some pending sectors with a HDD.
smartd[6711]: Device: /dev/sdk [SAT], 104 Currently unreadable (pending) sectors
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0
2 Throughput_Performance 0x0005 134 134 054 Pre-fail Offline - 104
3 Spin_Up_Time 0x0007 170 170 024 Pre-fail Always - 371 (Average 403)
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 31
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 128 128 020 Pre-fail Offline - 18
9 Power_On_Hours 0x0012 096 096 000 Old_age Always - 30983
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 31
22 Helium_Level 0x0023 100 100 025 Pre-fail Always - 100
192 Power-Off_Retract_Count 0x0032 098 098 000 Old_age Always - 2641
193 Load_Cycle_Count 0x0012 098 098 000 Old_age Always - 2641
194 Temperature_Celsius 0x0002 222 222 000 Old_age Always - 27 (Min/Max 2/48)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 104
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
# btrfs device stats /dev/sdk
[/dev/sdk].write_io_errs 0
[/dev/sdk].read_io_errs 0
[/dev/sdk].flush_io_errs 0
[/dev/sdk].corruption_errs 0
[/dev/sdk].generation_errs 0