[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
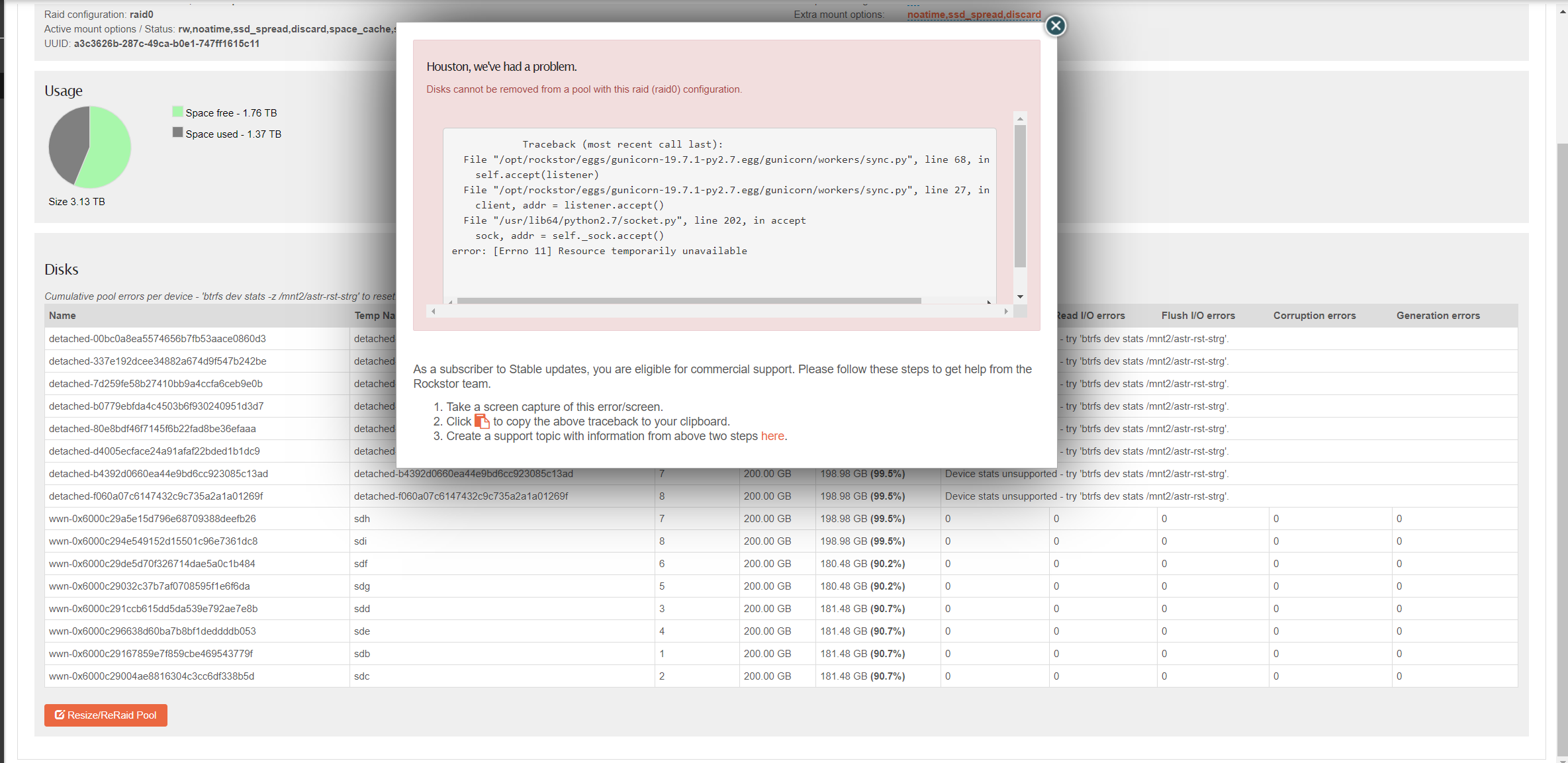
I had to restore rockstor running as a VM on ESXi from backup via Veeam B&R. Process completed successfully and all data is available, but in “Disks” I now see old disks (before restore) as “detached” along with new disks. When I try to remove them via “resize/reraid”, i get an error.
Detailed step by step instructions to reproduce the problem
“Disks cannot be removed from a pool with this raid (raid0) configuration”
It would seem, as these detached disks are still considered as part of the pool, and that the pool is raid0, which can have zero disks removed, we may be blocking on that basis prematurely. I’m due to look at this area of the code again soonish so will see if I can work out what’s going wrong.
But on a related note, from a quick look, the detached disks are no longer found as their appears to be no matching serial number. Rockstor tracks drives by their serial number. Does the backup system you used some how change device serial numbers. In which case it is not going to be suitable for Rockstor use, without caveats. Did you for instance have to re-import this pool post the restore. I’m just trying to fathom what’s happened here. Rockstor tracks devices it is asked to manage (pools created within the Web-UI and imports there in also) by their serial number so all the missing drives I’m assuming are the prior instances of what we see the newly attached disks as. But if as I suspect their serial numbers have changed they are to all intents and purposes, from Rockstor’s perspective, new disks. Hence the confusion.
This is an interesting one and I will try and fathom whats happened but it you could comment on the devices serial number stability through this ‘backup restore’ process that would help.
And if this backup restore of devices is configurable to maintain serial numbers through this process then that would probably avoid all these ghost devices appearing in the first place.
The following technical Wiki entry is our stance on device serial numbers and why:
Thanks for the details report and I look forward to hearing confirmation of if this VM based backup restore systems does in fact change drive serial numbers. If so then if their is an option to persist these that would be a pre-requisit from Rockstor’s perspective.
Hope that helps and thanks again for the report. Haven’t seen that one before.
Hi, @phillxnet!
The backup system has no option to manipulate disk’s serial numbers, or at least I was not able to find any reference to such ability in the manuals or forum posts - what it does is preserve virtual SCSI bus address. I performed a full restore (deleted the VM and restored it from a backup) and the VM just booted without requiring me to re-import the pool.
@Azzazel Thanks for this this info. So does look like it changes the serial numbers then.
If your up for a bit of experimentation you could try the same experiment, starting from a similar install but with the pool in btrfs raid1 with no detached disks. This may help to see if the raid0 warning in this case is a red herring. Btrfs raid1 does allow for disk removal from a pool, within limits, so in your case we side step this potentially bogus error message. If you can then remove the currently unavoidable with this backup/restore method ‘detached’ disks that result post restore we will have more information to work with.
Incidentally if you take the output of the following command pre and post restore method we may be able to see more what is happening with regard to drive info:
Although I suspect these drives end up not presenting their serial via lsblk and in which case via:
we retrieve it from via the following udev command:
udevadm info --name=/dev/sda
within the linked code:
So you could use this latter command on a single device pre and post its restore. Just to confirm what I suspect that it’s serial changes over that period.
Thanks again for the additional info re that VM orientated backup/restore method. I suspect that if it does in deed not persist device serials then it is essentially not compatible with how Rockstor works. But their may, within limits, be work-a-rounds. Rockstor sees one of it’s prime directives as ‘tracking’ devices irrespective of their content, to account for corruption or catastrophic failure there in, and the serials are the only way we can do that. If they get changed under it, it’s kind of all-at-sea and has to re-jig as best as it can work out.
Hi, @phillxnet!
I love experiments
So I spun up a new rockstor VM and created a raid1 from two 200G virtual drives, then backed it up with Veeam, deleted from vSphere and restored from a backup.
One thing of note is that this test VM has and reports as the latest rockstor version 3.9.1-16, probably due to the testing updates channel, while my main rockstor VM has version 3.9.2-50 with stable updates channel enabled.
After restore the detached drives were there, along with the new ones but this time I could successfully remove them.
Now, to the requested lsblk outputs.
Before restore:
So what do we do now? I would very much like these detached drives gone as they are messing up the reporting (rockstor thinks it has double the amount of disk capacity it has).
I will also keep the test VM powered off in case we need it.
Yes currently the testing channel, for our legacy CentOS base, is way behind. 3.9.1-16 was the last CentOS based testing channel release but is now over 2 years old:
It’s essentially the same as our 3.9.2 stable channel release, linked above, at that time.See the following thread for the background and some more links relating to this more recent history:
So this is good news and confirms my suspicion that we may be putting at least one cart before at least one horse; but ideally we want to confirm this with 3.9.2-50 code. For this Appman is at your service:
As a Stable subscriber you can now change your Appliance ID as and when you fancy with immediate affect. So in your case you could change it to your temporary btrfs raid1 test setup such that it can be updated to latest stable via your existing subscription: just use your existing activation code after the Appliance ID change has been entered. You would of course want to change this back to your main machine their after as otherwise it would no longer receive updates. So given this facility you can easily upgrade your temporary test machine to latest stable for the purpose of this test.
Note however that since this test machine is already on latest testing, if you move it now to the Stable subscription it will say it’s done it (instantly) but that is a bug. It’s now fixed but only in the code that it doesn’t offer to upgrade to because it thinks it’s already updated. It’s a rather dark bug that way
So make sure to run
yum update rockstor
when going from last CentOS testing (3.9.1-16) to Stable to ensure you are actually running 3.9.2-50 or later as of now. As otherwise the Web-UI states available version as installed. Not good. If going direct from a prior stable install, ie the iso itself, then now worries it should be good and should update as expected. Confirm via:
yum info rockstor
So in short, via our yet to be officially announced here on the forum (though it’s referenced in the Update Channels doc entry, through Appman you can upgrade your testing machine to latest Stable. Just remember to change your Appliance ID in Appman back to your regular machine their after. Otherwise it will receive no more updates. This new Appman facility is meant as a convenience for those that help to support Rockstor’s development and who, in doing so, have incurred an inconvenience: the whole activation code rigmarole. This was found to be required as a prior donations only system just didn’t work. I didn’t donate for one, before I became a contributor that is. So I’m hoping Appman helps to re-address this balance at least a bit.
Anyway if you could please repeat this experiment but with the 2 years newer code of 3.9.2-50 which, most relevant in this case, has very many changes to device management (hopefully only improvements), that would be great. Sorry to ask this of you but you do seem to be up for it
Thanks for these:
using different quotes to ease comparing them here and omitting the partitions for clarity,
and ordering them as sda, sdb, sdc we have:
We have confirmation that all 3 drives have effectively been replace by, from Rockstor’s perspective, 3 new drives. And this is what it indicates within the Web-UI also. So it is behaving exactly as expected. This situation does not, as far as I’m aware, have a parallel with real disks/devices. And Rockstor’s remit is to track real devices. So yes your backup restore system is at least confusing for Rockstor as it works to track devices irrespective of their content, at least once a pool is request as managed via creation within the Web-UI or import.
An interesting test case as it goes. Do please consider re-running, via the Appman trick, on our latest code if you would. I’m expecting the same behaviour re detached disks but would like to have confirmed that the newer code also lets you remove those ‘detached’ disks post restore as per your testing code experiement, ie with btrfs raid1.
You could, for the time being, by way of a work around, convert the pool to raid1 via the Web-UI and once that has finished it’s potentially lengthy balance, remove the detached disks their after. I’m not likely to get to look more closely at that code for a bit but your report has highlighted a potential improvement. But the consequences in your case are due to a corner case of all drives being supplanted by re-incarnations of themselves. And our current blanket ban on removing a device from a raid0 pool is legitimate as that is not something that is possible under any circumstances (other than the group simultaneous re-incarnation scenario your have reproduced). If we were to allow the removal of a device from a btrfs raid0 only when it was detached then in the scenario where a SATA cable becomes detached a user may inadvertently think they can just remove that disk. But they cannot. Re-attaching it and then changing the raid profile to one with redundancy is their option. I’ll have a think as their are likely many more common corner cases than yours that we are probably missing and I’m hoping to start the testing channel off again soon to explore these, as well as required modernisation, and as these are potentially non trivial critical code changes we have to tread carefully.
But if you are really game (read you have good and proven backups) the following code segment is what is giving your grief (correct as of posting this but may change later):
this is true for stable channel only as there have been many changes throughout since testing.
You might also note a further constraint in place just before the above code here:
Hope that helps and thanks for helping to test Rockstor’s limits re drive re-incarnation
@Azzazel Thanks for the further testing. Much appreciated. And glad Appman served as intended.
OK, thank. That’s good to know. Pretty sure I can reproduce this scenario here and this looks like a bug in our newer disk handling re removal of detached disks. As such I’ve created the following issue:
On first guess I would say this newer code has taken 2 steps forward and one back. Our prior disk removal code failed for attached disk from a Web-UI perspective, but worked a treat for the detached disks. And the new code now works for attached disks and can further monitor the (attached) disk removal’s data egress. But I now suspect fails for detached disks.
Once I’m done with my current release backlog and doing a couple of announcements I due again to look at this code. This issue looks like a good place to start.
Thanks again for this report, in a round about way I think you’ve hit on a relatively easy to reproduce issue. Apologies for not catching this earlier but I’m hoping it should be a relatively easy fix. My focus on the last fairly major revamp, and one of it’s dependencies, was on sorting the attached disk removal and I now suspect I’ve overlooked making a special case for detached disks and failing through silently without actually removing the said detached disk.
I’ve put a note on the issue to update this thread upon it’s resolution so ‘watch this space’.
Thanks again for your diligent testing and reporting, I’m really hoping to get some openQA based automated end to end testing in place in the not to distant future so that silly omissions such as this can be caught earlier, or at least so that anyone can submit new tests to catch such things and serve as regression testing for the future.
@Azzazel, Re removing detached disks in a raid0, the existing block is a valid safeguard but even if defeated, such as removing the indicated code doing this block, it’s the same code later on that is failing to remove detached drives of any sort. At least that’s my initial guess before I look properly into the issue I’ve now created for this bug. But I hope to get to this when time allows and will update here appropriately. We have to tread carefully here as this is sensitive code in a key area. So in short I now suspect it’s the same problem, ultimately, where we fail on pool resize remove detached disks. I intend to look to this in our up and coming testing channel; still working towards my:
Hopefully you will be up for a spot more testing once I’ve had a look? As this backup restore arrangement you are using is quite the full on test as it goes given that it requires Rockstor to re-jig it’s entire device db. But I suspect you are always going to have to remove ‘detached’ disks their after given how Rockstor tracks disks. But assuming the buggy removal of detached disks can be sorted you may have a workable arrangement which would be good.