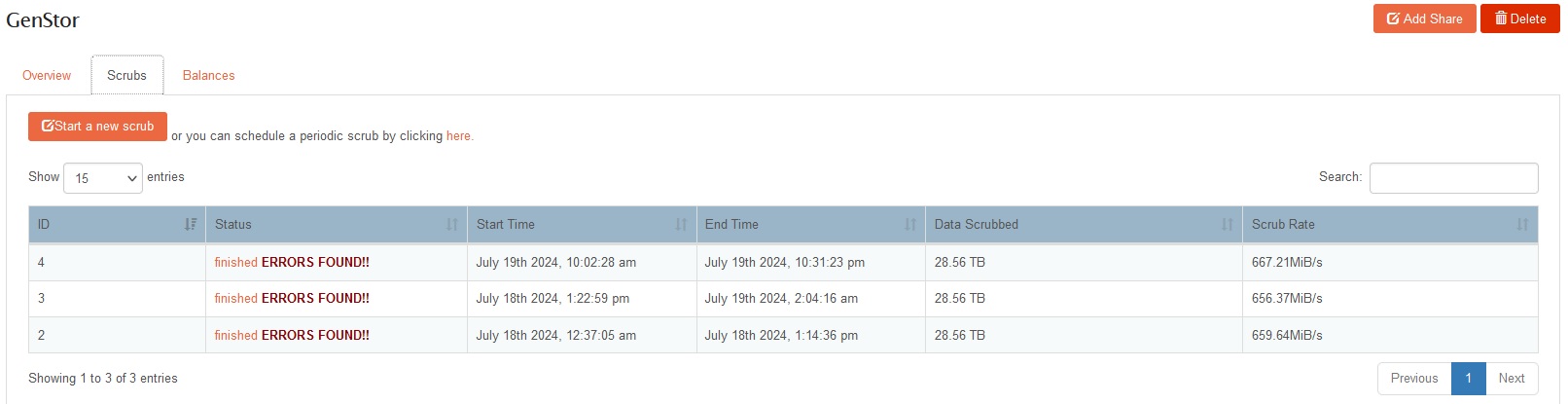
Got this:
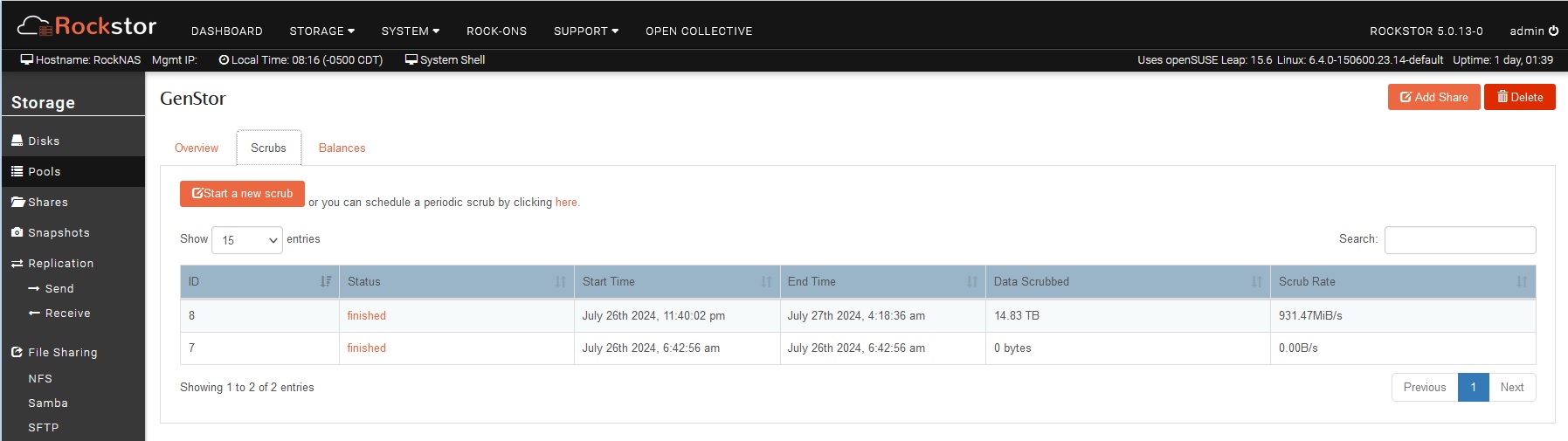
Putty root connection shows this:
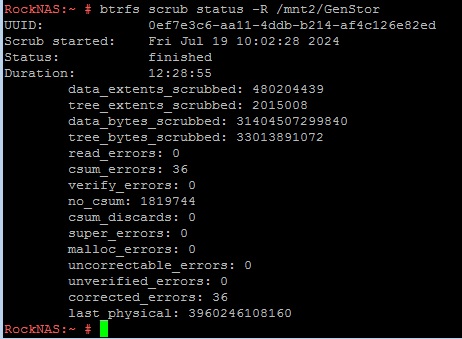
Tried to run this:
btrfs device stats --reset /mnt2/GenStor
And it won’t clear the csum_errors count or the corrected_errors count…
Running latest 5.0.13
help pweeze!
![]()
Got this:
Putty root connection shows this:
Tried to run this:
btrfs device stats --reset /mnt2/GenStor
And it won’t clear the csum_errors count or the corrected_errors count…
Running latest 5.0.13
help pweeze!
![]()
@Tex1954 Hello there.
Re:
In your screen grab you show a btrfs scrub status -R /mnt2/GenStror this given a report of the last scrub. That is not cleared by the btrfs device stats --reset /mnt2/GenStor as it’ what was found at the time.
btrfs device stats --reset /mnt2/GenStor
should clear the device stats that btrfs keeps a tally of. We then present this tally at the bottom of the Pool details page. After this reset command that tallyl should be clear: but not the scrub report. Both the last from btrfs as per your image, and our stashing the same info after each scrub summarised in your first pic. Also note you can click on the “finished” entries in the status to get a Web-UI representation of scrub status.
So in short, the device stats --reset is accumulative on all operations and stored by btrfs against each pool member - we just report it in pool details disk table (bottom on page) for the parent pool. Where-as scrub reports are static (once the scrub is finnished): they show the info for that scrub only. This does not change as it is historical.
To see the device stats per drive one can:
btrfs device stats /dev/sda3
Where you would replace the “/dev/sda3” with the drive you are interested in. Or use the Pool mount point for all members.
Once you have reset device stats for a pool, all disk members ‘stats’ should then show zero.
See: btrfs-device(8) — BTRFS documentation for the upstream docs.
Hope that helps, and my apologies if I’ve got the wrong end of the stick on this one.
Okay, I have checked SMART on every HD in the pool and there are ZERO errors shown. However, experience teaches that isn’t necessarily the whole picture. A simple com (SATA) error in the hardware can cause such errors. Also, as I have observed in the past, erasing a file that just may be in the process of being scrubbed can cause such errors. Also, the errors seem random at times (again, usually when I am doing something in the pool) and it isn’t on the same disk “usually”. However, this time it seems to be mostly on one drive (/dev/sdo).
Then I tried the btrfs check --force /dev/sdo command and it ran fine with no errors discovered or corrected.
I will try to do some more digging and see what I can find out…
Trying a “balance” now to see what happens and will get back to you.
Thanks!
![]()
Okay, deleted and recreated the Raid-10 pool, restored all the data, then ran a scrub and balance with no errors. The only difference is I wasn’t working/changing/erasing anything while doing scrub/balance stuff.
In between, did every hardware test I could think of (booted windows and ran a lot of tests) and couldn’t find ANY real errors or problems. However, in case of some weird problem, I ordered a new HBA and will install with new cables in the near future. PSU & UPS is working fine as well.
I still think there is a possibility that some hardware component is misbehaving, but we will see. I do have several spare HDD’s if some weird fault is present…
At this point, ANY idea’s on how I can prove there is a software glitch or hardware glitch would be much appreciated. It bothers me that this has happened intermittently over the last few years and never a hardware problem found… It ONLY seems to happen if I do a balance or scrub and then work on files/directories at the same time.
![]()
@Tex1954 Hello again, and thanks for the ongoing updates on this mistery.
Re:
Have you recently done a RAM test? I.e. such as is detailed in our PBP:
https://rockstor.com/docs/installation/pre-install-howto.html
That might explain your issues. Bit of a shot-in-the-dark as is often the case with highly intermittent issues: but might help to explain where this failure is comming from.
Do heed the warnings there re system stress/heat etc: but I know you are already familiar with such things :).
Hope that helps.
Hmmm, the setups use ECC memory and I’ve never seen any indication of a problem.
I do own Memtest-86 Pro and can run that easily… I’ll give that a shot when the new HBA arrives so I don’t have to open the setup multiple times because I also want to change the HDD out just in case…
I’ll let y’all know!
![]()
Did further testing and Memtest86 Pro V11 passed with flying colors.
Next tested one of the two HBA’s I have (again!) and the 2 channel HBA is failing!!!
The 8 channel one is still okay.
To solve the problem, I did order a new HBA that should arrive soon. The NEW HBA can control 16 channels in IT mode and will replace the original 2 HBA’s in the setup.
Problem solved. (I hope!)
![]()