I would like to point out a couple things, especially about SSDs as boot disks.
As mentioned in another post, current MLC,TLC, QLC etc. consumer SSDs have TBW between 400 and 700. The SIZE of the SSD has to be taken into consideration as well for the TeraBytesWritten value to make sense.
In the old days with SLC, we had fairly fast reads (250-325MBs) and slow writes (65-95MBs).
Modern SSDs use higher voltages, 3D structures and multiple bits per cell to achieve more symmetrical and faster throughput. Typical flash endurance in the old SLC days was 1000 writes per bit (cell) and they largely performed that well. (I still have many and none have failed yet!)
So, since we are talking about BYTEs, an SLC could live up to 1000 writes assuming well devised write balancing in the device. (Big ASSUME!)
So a typical old days 40G SLC SSD could in theory live up to 40 TBW.
A new modern SSD can live up to 400 TBW for a typical 512G SSD which is sadly LOWER than what used to be. In fact, it works out to be about 22% less TBW life. However, they live in style and are drag racers compared to the old 1955 Volkswagen Bug SLC drives.
I see BOTH my Rockstor setups write about 5.5 GBytes/Day. So how many days will my 80 TBW 240G SSD last?
80e12 (TBW) / 5.5e9 (GBday) is about 14545 days or about 39 years.
WHAT?!!? 39 years? Well, it’s only a rough calculation because the controller or/and other ICs used in construction could die any time. Also, this doesn’t take into account that many modern CHEAPER SSDs use a portion of the flash itself as a buffer. Better SSDs use DRAM for buffering and house keeping.
Also, when you fill up the SSD enough to interfere with that internal flash buffer, performance drops to pencil & paper speeds.
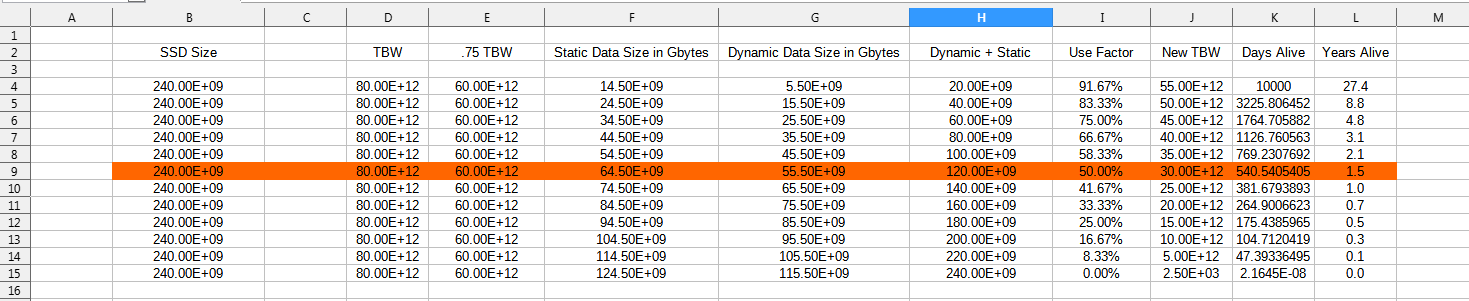
Good rules of thumb for longevity is use an SSD that is at least twice what the STATIC + Dynamic data is expected to be. (I prefer a factor of 10 or better myself!)
Also, take that 39 year expected lifetime and subtract 25% for flash buffer use.
Also, assume inefficient wear leveling and subtract the static + dynamic data size from the SSD size and multiply diff % times the new TBW.
Now I come up with (80 * .75 TBW) * ((240 - 20G)/240) = .60TBW * .92 = 55.2 TBW
Finally, do first calc using modified values.
55.2e12 (TBW) / 5.5e9 (GBday) is about 10036 days or about 27 years.
I don’t expect my Rockstor Boot SSD’s to die in my remaining lifetime!
Check out this spread sheet: ( open in new tab for full size)
Notice how the life goes to hell when you cross 50% utilization? Guess what, I totally destroyed one SSD and about hit TBW (Write performance seriously degraded) on two others in 59 days using them to 80% utilization testing them as a Raid0 buffer!
It isn’t magic, the numbers don’t lie and actual testing has proven this formula I use.
Soooo, only a few GB a day on lightly static loaded SSD? No worries!

PS: I’ve pretty much decided that unless you are rich and buy Intel Optane SSDs, using consumer SSDs as a cache or buffer of any kind is simply out of the question. Systems will try to use them to 100% as things stand and they will NOT work that way!