when removing a disk from a pool
[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
the version of rockstor 3.9.1-16
Detailed step by step instructions to reproduce the problem
[write here]
Web-UI screenshot
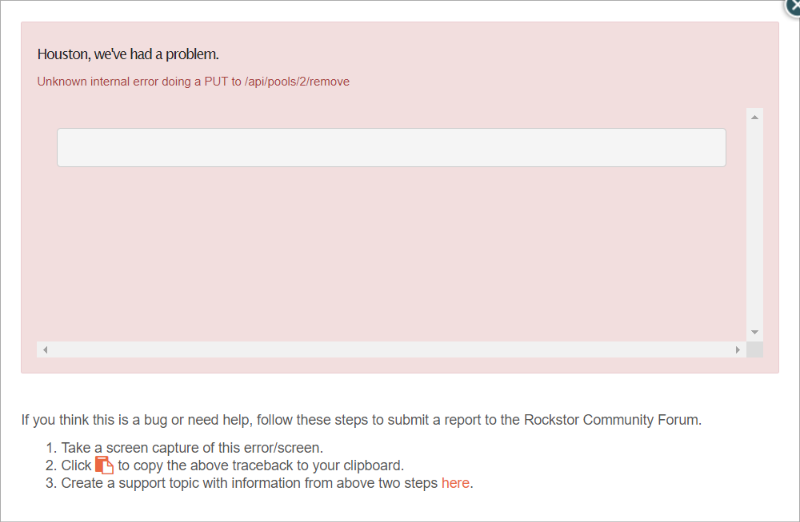
Error Traceback provided on the Web-UI
[paste here]
but it is strange that when I am trying to remove another disk
it says a removing is in process
Error running a command. cmd = /sbin/btrfs device delete /dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH /mnt2/st5000danpan. rc = 1. stdout = [‘’]. stderr = [“ERROR: error removing device ‘/dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH’: add/delete/balance/replace/resize operation in progress”, ‘’]
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool.py”, line 470, in put
resize_pool(pool, dnames, add=False)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 210, in resize_pool
return run_command(resize_cmd)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /sbin/btrfs device delete /dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH /mnt2/st5000danpan. rc = 1. stdout = [‘’]. stderr = [“ERROR: error removing device ‘/dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH’: add/delete/balance/replace/resize operation in progress”, ‘’]
the other disk I ordered to be removed before is ata-ST5000LM000-2AN170_WCJ1F9RB