Just now the system restarted by itself  seems that there is no way of solving my missing HDD issue
seems that there is no way of solving my missing HDD issue
@shocker Oh dear:
I think there are as yet quite a few more options available. Given some of the work will already have been done and it may be that a restart of this procedure, if it’s not restarted itself on mount, may end up finishing. I’ve heard of that happening. Again the repair story on 5/6 is suspect. But usually doable with perseverance. How much ram do you have in this machine currently?
Maybe you should consider jumping on the Leap15.2beta as they are almost at package freeze currently. This runs a much newer kernel again as you need a following wind really given your raid 5/6 use and the very large pool. I don’t think we’ve covered this but if you also have many snapshots that can massively slow stuff down as well.
So initially try restarting the same procedure, after first ensuring it’s not restarted itself, ie take a few usage readings as a regular balance status doesn’t show the ‘internal’ balances.
On the other hand as you need a strong following wind, and you mentioned it taking potentially for ever it may not have gotten that far along anyway. So the same may well happen again. In which case maybe the Leap 15.2 beta build is not that crazy. It’s still 2 weeks from package freeze though so up updates often need a pretty regular ‘zypper refresh’ as they are changing them all the time.
If you go this route you will need to edit our instructions for the rockstor testing package repo path to 15.2 and you will need, for the time being, to use the 15.1 version of the shells repo as they haven’t yet published for 15.2. Seems to be working OK for now though and this can be switched later anyway. We only use that repo for the shellinabox and make sure to honour the priority setting or you may end up pulling in more that you want from that repo.
And since you are rather out there on the edge already we are also publishing Tubleweed rpms. But lets not go that far just yet. Our intended ‘re-launch’ target is planned to be Leap 15.2 once it’s released. So there’s that.
Hopefully that is food for though and if you go the Tumbleweed root remember you update that differently. But the beta Leap looks like the next major tool for your particular repair scenario as it has a newer kernel again than Leap15.1. But openSUSE/SUSE are pretty aggressive with the btrfs back-ports so it may not end up making that much difference. But it may be worth a try if you are ‘in a corner’.
Leap15.2 beta:
Tumbleweed:
Hope that helps, at least on the options / plans front.
1 Like
Thanks for the info.
I have just upgraded to 15.2. On my system I have 64gb DDR4 ECC.
Let’s try again to see what will happen
As repo’s I have:
[Rockstor-Testing]
enabled=1
autorefresh=1
baseurl=http://updates.rockstor.com:8999/rockstor-testing/leap/15.2/
type=rpm-md
And for shells:
[shells]
enabled=0
autorefresh=1
baseurl=http://download.opensuse.org/repositories/shells/openSUSE_Leap_15.1/
type=rpm-md
priority=105
Is that all right?
i can see this error on gui under balances errors or notes:
Error running a command. cmd = /usr/sbin/btrfs device delete missing /mnt2/storage. rc = 1. stdout = [’’]. stderr = [“ERROR: error removing device ‘missing’: no missing devices found to remove”, ‘’]
but the devices are still missing:
devid 19 size 12.73TiB used 11.87TiB path /dev/sdb
devid 20 size 12.73TiB used 11.87TiB path /dev/sdf
*** Some devices missing
now seems that the missing decreased from -6.17 TiB (before system restart) to:
missing 1.11TiB
That’s strange, I have no idea what is happening
Staring again the delete process. Seems that it’s not eating up more than 2.17 GB of ram.
The sys load increased from 0.6 to 6.76
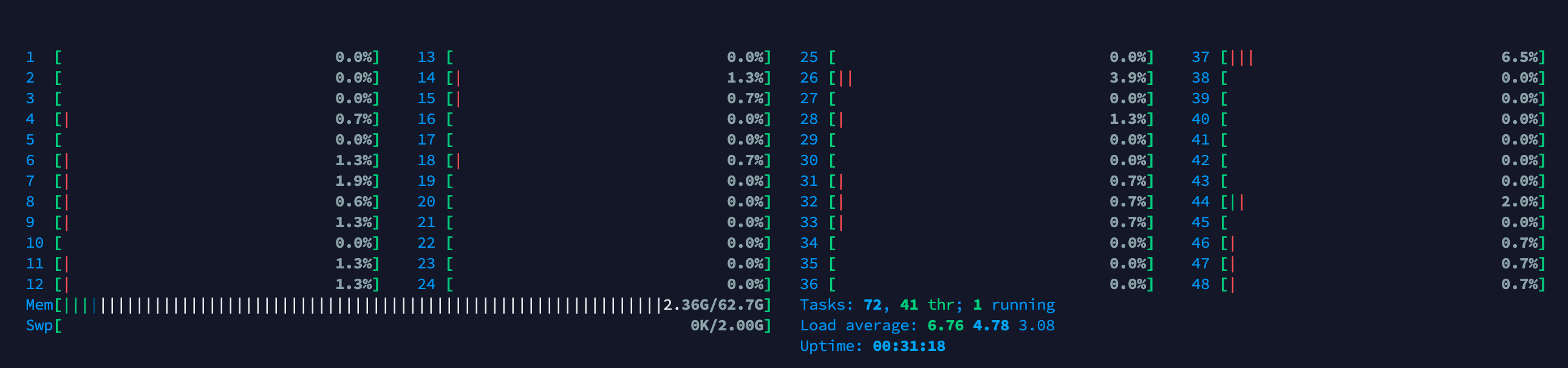
Even that I have started the process from web gui, seems that now it doesn’t read that the process is running anymore
ps aux|grep -i delete
root 19924 55.0 0.0 16116 1236 ? R 23:49 2:32 /usr/sbin/btrfs device delete missing /mnt2/storage
And now again the missing is back on track: missing -6.16TiB
I think the delete process corrected the values and added to correct one. As mentioned above before running the delete command I had 1.11 TiB but 6.16 is the correct value as before restart it was 6.16 TiB.
1 Like
Went also to the “dark side” wihout any system responsive improvement. It will be nice to be able to use system in decent way during the delete as everything is taking ages
ionice was set to 3, nice to 19 and played with fire:
sysctl -a | grep -i dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 50
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 99
vm.dirty_writeback_centisecs = 500
vm.dirtytime_expire_seconds = 43200
I can see spikes to the ram usage from 2.6GB to 6-7Gb from time to time but still I’m loading a NFS mounted folder in ~7 seconds as average, writing is almost impossible and reading is degraded to max 28MB/s from 800MB/s-1GB/s.
The NFS server is unresponsive from time to time:
Apr 16 09:41:05 kernel: nfs: server 10.10.2.2 not responding, still trying
Apr 16 09:41:15 kernel: nfs: server 10.10.2.2 not responding, still trying
Apr 16 09:41:25 kernel: nfs: server 10.10.2.2 not responding, still trying
Apr 16 09:42:02 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:42:02 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:42:02 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:42:02 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:42:02 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:43:08 kernel: nfs: server 10.10.2.2 not responding, still trying
Apr 16 09:43:26 kernel: nfs: server 10.10.2.2 not responding, still trying
Apr 16 09:43:56 kernel: nfs: server 10.10.2.2 OK
Apr 16 09:43:56 kernel: nfs: server 10.10.2.2 OK
And the BTRFS is doing his best:
[34428.832966] BTRFS info (device sdh): relocating block group 224807624638464 flags data|raid6
[34562.582707] BTRFS info (device sdh): found 85 extents
[34606.999702] BTRFS info (device sdh): found 85 extents
[34651.044506] BTRFS info (device sdh): relocating block group 224796753002496 flags data|raid6
[34881.482326] BTRFS info (device sdh): found 85 extents
[34945.006739] BTRFS info (device sdh): found 85 extents
[34991.012719] BTRFS info (device sdh): relocating block group 274991484370944 flags data|raid6
[35059.415995] BTRFS info (device sdh): found 69 extents
[35094.111887] BTRFS info (device sdh): found 69 extents
[35135.281770] BTRFS info (device sdh): relocating block group 224851111182336 flags data|raid6
[35240.605588] BTRFS info (device sdh): found 118 extents
[35290.565006] BTRFS info (device sdh): found 118 extents
[35334.166054] BTRFS info (device sdh): relocating block group 224840239546368 flags data|raid6
[35454.168116] BTRFS info (device sdh): found 175 extents
[35493.149862] BTRFS info (device sdh): found 175 extents
[35524.296048] BTRFS info (device sdh): relocating block group 274983028654080 flags data|raid6
[35629.021858] BTRFS info (device sdh): found 84 extents
[35660.882455] BTRFS info (device sdh): found 84 extents
[35709.688994] BTRFS info (device sdh): relocating block group 224872854454272 flags data|raid6
[35811.380871] BTRFS info (device sdh): found 741 extents
[35867.991877] BTRFS info (device sdh): found 741 extents
[35910.092497] BTRFS info (device sdh): relocating block group 224861982818304 flags data|raid6
[36056.325761] BTRFS info (device sdh): found 123 extents
[36245.628393] BTRFS info (device sdh): found 123 extents
[36386.202130] BTRFS info (device sdh): relocating block group 274974572937216 flags data|raid6
[37009.927896] BTRFS info (device sdh): found 76 extents
[37362.075607] BTRFS info (device sdh): found 76 extents
No idea what to do next, I’m starting to hear voices in my head: “go back to ZFSssss”
Cheers
@shocker I’ll have to be brief right now but:
Yes looks right. We build each rpm on the respective platform.
There have been some command formatting changes that trip us up on recognising some stuff. Easy fixes but still pending.
This element of our ‘discovery’ does have bugs but in your case we need to get you pool healthy again.
Given you last missing removal ended in some what of an emergency bail out on the kernel (could have been OOM killer or the like) elements of yours info were likely out of wack. The restart of the prior procedure likely fixed those as you indicated.
On this point and:
I must apologise a I completely forgot about space_cache=v2. For most of it’s history btrfs has been plagued by performance issues, as ZFS was in it’s early history incidentally. And this most affected all pools with quotas enabled and there have been many fixes on that front more recently but we have seen to that by disabling them in your case. But the thing I missed / forgot about was this space_cache thing. It is not yet the default but is particularly pertinent on large pools and yours qualifies. It can have a dramatic performance improvement which is relevant in your case. The catch here though is that to change over to it is a one-off set of mount options (not yet supported by Rockstor’s Web-UI). There after the pool will default to using this new space cache method every time it mounts, hence then not an issue that the Web-UI doesn’t support it yet. However it does mean you will need to stop all rockstor services
rockstor-pre
rockstor
rockstor-bootstram
Do the space cache transition deed. And given it’s sticky and resets the pool so in future it will default to the new space cache method on all subsequent Rockstor mounts as it’s the pool default. At least that is my reading of this. But I wouldn’t go back further than Leap15.2 from then on with this pool.
But you will need to read up on this procedure to make sure I have it right. I believe the btrfs wiki is now out of date on this so that’s a wrinkle.
https://btrfs.wiki.kernel.org/index.php/Manpage/btrfs(5)
But look to the following recent posts on the btrfs mailing list:
Zygo Blaxell references/explains this option in a recently btrfs mailing list thread:
https://marc.info/?l=linux-btrfs&m=158640676810559&w=2
I see that ‘space_cache=v2’ has already been suggested. That usually
helps a lot especially on big filesystems. space_cache=v2 does an
amount of work proportional to committed data size during a commit, while
space_cache=v1 does an amount of work proportional to filesystem size
(and committed data size too, but that is usually negligible if your
workload is nothing but write and fsync).
And Chris Murphy earlier in that same thread covers the transition procedure:
Another thing that might help, depending on the workload, is
space_cache=v2. You can safely switch to v2 via:mount -o remount,clear_cache,space_cache=v2 /
This is a one time command. It will set a feature flag for space cache
v2, and it’ll be used automatically on subsequent mounts. It may be
busy for a minute or so while the cache is rebuilt.
Note that you will have to change the pool mount point in your case, ie /mnt2/pool-name-here. And another wrinkle is you are mid disk removal !! I’m unsure what a remount will do in that case. But you’ve already continued on from what looks to have been more severe and you are now familiar with what to look for re on going operation.
But of course I’ve dropped the ball in that you are already mid procedure as I bring this up. So apologies for that. But this definitely looks like a key element in your speed / lowering overhead issues. Both for this repair and for ongoing performance given your large pool size.
No idea why this hadn’t occurred to me earlier as I’ve seen it mentioned numerous times on the btrfs mailing list but there we do, another human failing to chalk up.
So I hope this helps, at least if things go south again and you have the change to remount. Or whatever.
Let us know how it goes and well done on the Leap15.2 move. I think it’s going to be a nice new home for us.
1 Like
Thank’s for sharing this, I’ll give a quick try. As of no I have disabled the delete missing process and I’ll retry somewhere next week, so it will be safe to try this mount option.
Quick question, not sure if I understood right, after I’m enabling space_cache I cannot use rockstor anymore as rockstor will fail to show them mount or rockstor will remove this mount flag and it will remount without it?
One last thing, I discovered a new bug on rockstor and this happened to me 3 times, I’ll start explaining by providing an example.
- Reboot system
- Manually mount FS in degraded state
- Open Rockstor WebUi → Storage → Nfs
- Due to automatic failed mount, I guess on hares column is empty, only the Host String, Read only, Sync/Async and Actions is populated. Manually checking the /etc/exports everything is there.
- Edit the line, add the shares, hit save. Then I’m getting an error and Rockstor Web becomes unusable as hostnamectl is not working. Checking the webgui, indeed the hostnamectl command is not working. Checking the logs the systemd-hostnamed crashed. Restarting the systemd-hostnamed fixed the issue.
First time I tought that it’s a coincidence, but also the second and the third time happened only when I’m editing the line and hit save.
I don’t know if point 4 is a feature or a bug ![]() but point 5 for sure is a bug.
but point 5 for sure is a bug.
Hope that helps and thanks again for the feedback and involvement.
One remark, seems that the space_cache (v1 I guess) is already added by defualt:
/dev/sdh on /mnt2/mount type btrfs (rw,relatime,degraded,space_cache,subvolid=263,subvol=/mount)
I guess because I manually mounted as degraded and it was not managed by Rockstor.
From the manual: ( nospace_cache since: 3.2, space_cache=v1 and space_cache=v2 since 4.5, default: space_cache=v1 ), so somehow till now I’ve been using some kind of space cache
I have activated it now: /dev/sdh on /mnt2/mount type btrfs rw,relatime,degraded,space_cache=v2,clear_cache,subvolid=265,subvol=/mount)
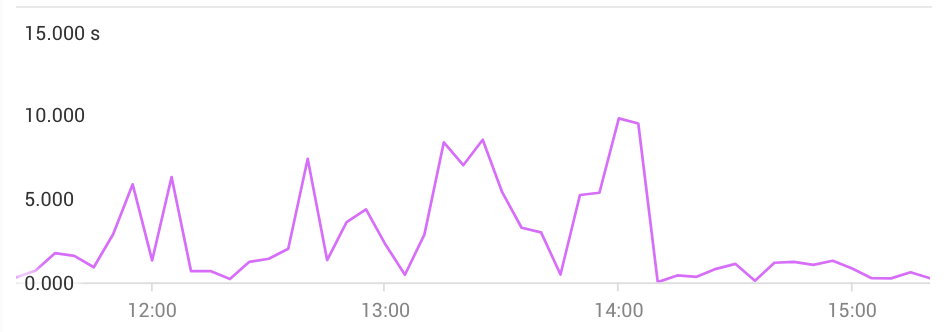
I’ll monitor the latency graph to see if there is any improvement so far (considering that de delete device missing is not running now).
So far rockstor gui is working fine, no issues as of now with this new mount:
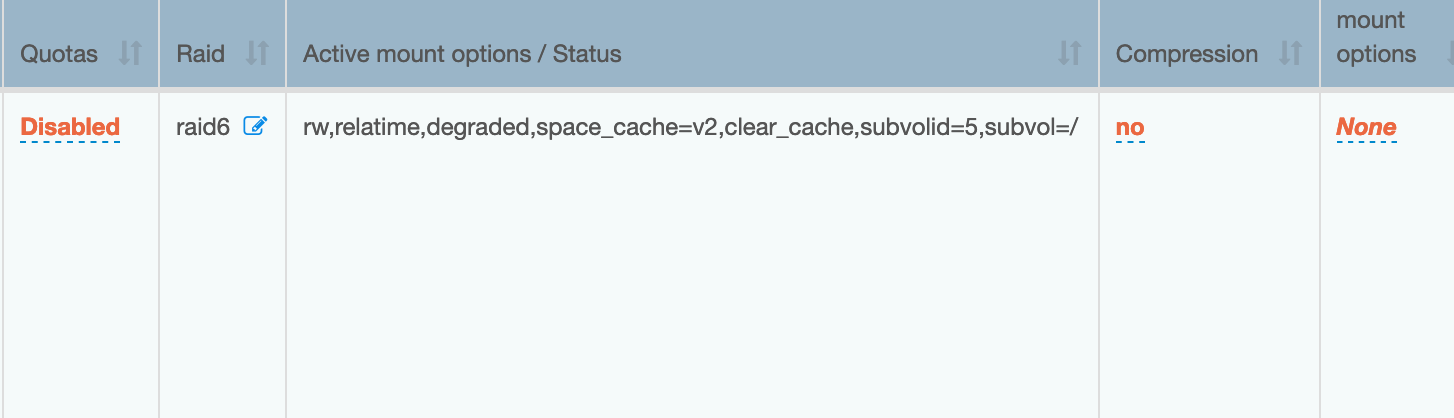
Seems that the latency improved for the last hour ![]() so I think this should be enabled by default on Leap 15.2 as I cannot see no reason why for kernel 5.x.
so I think this should be enabled by default on Leap 15.2 as I cannot see no reason why for kernel 5.x.
That’s not my understanding. Once you’ve done the suggested remount or a mount with the 2 options, one to wipe the existing cache and one to specify the v2 version. There after all mounts will default to to using the new v2 version and so Rockstor will simply honour this as it has not specific preference either way. It just goes with the default. But you can’t use the Web-UI to administer this change as it doesn’t know about this option and so will reject it. Hence the need to do a one off mount / remount at the command line to move the new default over to the v2 space cache. There after all regular mounts will just use the new default. Hope that clear enough.
Haven’t seen this before, I wonder if this is a beta issue in 15.2 only. Lets see if this settles down with some updates and if not then open a GitHub issue on it and specify the exact way to reproduce and your disto variant and testing channel rpm.
It’s the default but I don’t believe we add it. But as it’s the default I’m guessing it being shown as such. Still you can use that to see if the change ‘takes’ and is in play there after.
All btrfs mounts by default use space_cache is my understanding. But v1 only. And one has to explicitly state, at least once and wipe the old v1 in this case (hence the 2 combined remount / mount options) to redefine the default, for that pool, to space_cache v2.
I believe the manual is out of date now and I also think what it is saying there is that v2 was introduced in the 4.5 kernel. Not that it was a different default.
Nice.
but not that you only want to use the space_cache=v2 in combination with clear_cache on the initial mount to change the default. On subsequent boots I’d only expect to see the space_cache=v2 and not the clear_cache. Sorry I haven’t played with this myself. So do keep an eye on how it presents itself. I’m assuming this is the same mount where you change the default and used both options. I’m assuming on subsequent boots we wont see the chear-cache options there.
Good news at last.
As for having Rockstor enable a non default mount options, I’m a little uncomfortable with this. I’d far rather stick to the file system defaults and they have not as yet made this then new default. But we could have a doc entry on how to do this. And add these ‘change pool default’ options to our Web-UI allowed mount options. That shouldn’t be too difficult. We could then instruct folks to add those 2 options, and I think we do a remount ourselves anyway. And then they could presumably just remove them again. Otherwise the clear_cache will end up wiping the cache on every boot which I think is a bad thing. But still adding and then removing via the Web-UI is far better, and a first step, than having to drop to cli and stopping all rockstor services etc. I’ll take a look soon hopefully as I’m hoping it may be an easy addition to our mount option filters. Haven’t added any of these for ages either: the last additions were:
And incidentally we have the following issue for the space_cache=v2 pool mount option:
Where I have now, in the latter, added this forum thread as a reference.
It will be very interesting to see how you get on with this. So do keep us informed. Hopefully it will speed up your disk removal when that time arrives again.
1 Like
I’ve been playing with balance as this process is easy to be stopped. I can see an increase of speed like 10-15% but I’m being subjective here as my official measuring tool is based on “feelings” . I still don’t think that’s enough.
New ideas:
-
I’ve been wondering if the cfq enablement will help or bfq is better? I don’t have experience with those
As of now I have: # cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none -
My FS usage is 97%, is this affecting the delete performance? Seen some recommendations for BTRFS that needs to be <90%. From what I know the way that BTFS works shouldn’t impact this and that was only the case for ZFS that needs to be less the 80% to not impact the write performance.
-
Seen that there are many many fixes on tumbleweed and also they run btrfs-progs 5.6. I’m planning to upgrade and try next week. Any hints for the rockstor repo’s and if I need to enable/disable something else?
Thanks
@shocker Hello again.
Re:
97% is way beyond safe I would say and yes 80% plus is where you need to start addressing space. Btrfs is similarly affected by lack of ‘breathing room’ as it’s easier and quicker to make a new chunk and populate it than to find every free block within existing chunks. That’s one of the benefits of a balance, that it can fee up new space rather than having to use all the little bits left over from partly used chunks. And each chunk is normally 1 GB. But then, as I understand it, a balance will start by trying to create new free chunks and shuffling blocks into that fresh chunk. I’m afraid I’m a little weak on knowledge at this level though.
Interesting. But bear in mind that the btrfs stuff in that kernel is less ‘curated’ so you will truely be on the cutting edge. But if that is what you need. Where as the openSUSE/SUSE team cherry pick more for the backports in the Leap releases. But as long as you understand that then great.
To your question re repos. It’s actually a little better on that front as it goes given that 15.2 is in beta and so no shells repo. Where as Tumbleweed is ‘ever prescent’ so you can use the ‘native’ repos. So really it’s just change to the testing repo for the rockstor rpm and use the tumbleweed repo for form obs for the shells. But do make sure to honour the priority on that shells repo, as there is more in there than just the shellinabox that we need as a dependency.
Shells repo:
has details for both the Leap15.1 (15.2 to be added when available) and already has the Tumbleweed shells repo adding commands.
Rockstor Testing repo (early-adopters/developers only)
has for some time had the Tumbleweed rpm repo info also as well as how to import the Rockstor key.
Note that I’ve now just updated the latter to include Leap15.2 beta repo instructions (bit late you you ![]() ) and our intention to use this for our next Stable release. I’ve also, hopefully, made it clearer and quicker to follow. Let me know if I’ve missed anything as you try it out.
) and our intention to use this for our next Stable release. I’ve also, hopefully, made it clearer and quicker to follow. Let me know if I’ve missed anything as you try it out.
So good luck but do remember that theTumbleweeds kernel is, as far as I’m aware, pretty much mainline with a few relatively minor openSUSE/SUSE patches to enable things like boot to snapshot so it is far less tested/curated than Leaps. But it ‘Newer Tec’ may be of use to you. Just remember that it is more common for corruption bugs to be released as at that age far fewer folks have actually run those kernels. However if you end up having to resource the btrfs-mailing list for your issues you will be in a far more advantageous position than if you are not running a cutting edge case. In that regard it’s a fantastic resource for us and enables those in need to run these very new kernels.
Thanks
I’ll use Tumbleweed just to try to recover. Afterwords I’ll give a fresh reinstall to Leap15.2.
As of now I do have a full backup, but unfortunately the recover will take a week due to the huge size of the backup.
I’ll try Tumbleweed with or without Rockstor as to be honest the only thing I’m using is a nfs server and that’s it
OK, keep us posted on any progress / performance reports.
Tumbleweed is now installed. Changed the repo for rockstor during installation but seems that is not working. Web gui is giving me Internal Server Error.
Also reinstalled rockstor just to ensure that everything is ok.
rockstor.log is blank.
supervisord.log:
2020-04-21 09:33:32,784 INFO spawned: ‘data-collector’ with pid 8036
2020-04-21 09:33:33,338 INFO success: ztask-daemon entered RUNNING state, process has stayed up for > than 2 seconds (startsecs)
2020-04-21 09:33:33,496 INFO exited: data-collector (exit status 1; not expected)
2020-04-21 09:33:35,500 INFO spawned: ‘data-collector’ with pid 8045
2020-04-21 09:33:36,186 INFO success: nginx entered RUNNING state, process has stayed up for > than 5 seconds (startsecs)
2020-04-21 09:33:36,186 INFO success: gunicorn entered RUNNING state, process has stayed up for > than 5 seconds (startsecs)
2020-04-21 09:33:36,213 INFO exited: data-collector (exit status 1; not expected)
2020-04-21 09:33:39,832 INFO spawned: ‘data-collector’ with pid 8054
2020-04-21 09:33:40,583 INFO exited: data-collector (exit status 1; not expected)
2020-04-21 09:33:41,585 INFO gave up: data-collector entered FATAL state, too many start retries too quickly