This suggests you are doing an inplace distro transition. Is that the case? All rockstor rpms are build on and subsequently installed into their respective distros prior to release and for testing channel are at least tested through initial setup screen and through to dashboard and update screen. And given each rpm is build ‘natively’ there can be subtle differences. So if you did a transition the rpm re-install may not have enforced all file changes. I have as a result of the above build procedure the following:
However that was updated post the rpm build/install but pretty sure it was build and freshly installed on a 20200413 TW version I think.
and if you want to use the same admin user again, as the above will initiate a fresh initial setup screen, you will also need to:
userdel old-admin-user
That way the setup screen won’t complain about that user already existing on the system.
Then visit the Web-UI and do a fresh setup sequence.
All of the above assumes no prior source builds which should also be wiped in they exist. Just in case.
That is obviously a full config reset but if you have been doing live distro migrations then it’s probably for the best as you then guarantee a complete set of naively build support files. The above procedure has just worked on my freshly (yesterday) zypper dup 'ed 20200417 install using the indicated latest published testing rpm for Tumbleweed.
See how that goes. Otherwise some pointers/investigation at your end is a possible next step as I don’t see the same behaviour here.
Tried, no improvement. Seems that something got wrong with the self generated SSL and that was the root-cause.
I have installed tumbleweed from scratch and it’s working now
Yes, Leap 15.1 -> Leap 15.2 Beta (no issues) -> Tumbleweed latest snapshot.
During the upgrade I have changed the Rockstor repo from /leap/15.2/ to /tumbleweed/ and during the upgrade there was 1 package from Rockstor, so it worked.
Also on nginx.conf you need to remove “SSL on” and add SSL on listen 443 default_server, something like “listen 443 default_server ssl;” ( /opt/rockstor/etc/nginx/nginx.conf )
tail -f supervisord_data-collector_stderr.log
from .exceptions import (
File “/opt/rockstor/eggs/gevent-1.1.2-py2.7-linux-x86_64.egg/gevent/builtins.py”, line 93, in import
result = _import(*args, **kwargs)
File “/usr/lib/python2.7/site-packages/urllib3/exceptions.py”, line 2, in
from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
File “/opt/rockstor/eggs/gevent-1.1.2-py2.7-linux-x86_64.egg/gevent/builtins.py”, line 93, in import
result = _import(*args, **kwargs)
File “/usr/lib/python2.7/site-packages/urllib3/packages/init.py”, line 3, in
from . import ssl_match_hostname
ImportError: cannot import name ssl_match_hostname
tail -f gunicorn.log
import urllib3
File “/usr/lib/python2.7/site-packages/urllib3/init.py”, line 7, in
from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url
File “/usr/lib/python2.7/site-packages/urllib3/connectionpool.py”, line 11, in
from .exceptions import (
File “/usr/lib/python2.7/site-packages/urllib3/exceptions.py”, line 2, in
from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
File “/usr/lib/python2.7/site-packages/urllib3/packages/init.py”, line 3, in
from . import ssl_match_hostname
ImportError: cannot import name ssl_match_hostname
Hope that helps.
P.S. Why certbot is not integrated by default to generate a cert for the SSL in case that a valid domain is used? There can be something like:
if domain resolv to ip then use certbot to generate ssl for nginx
else use rockstor default ssl
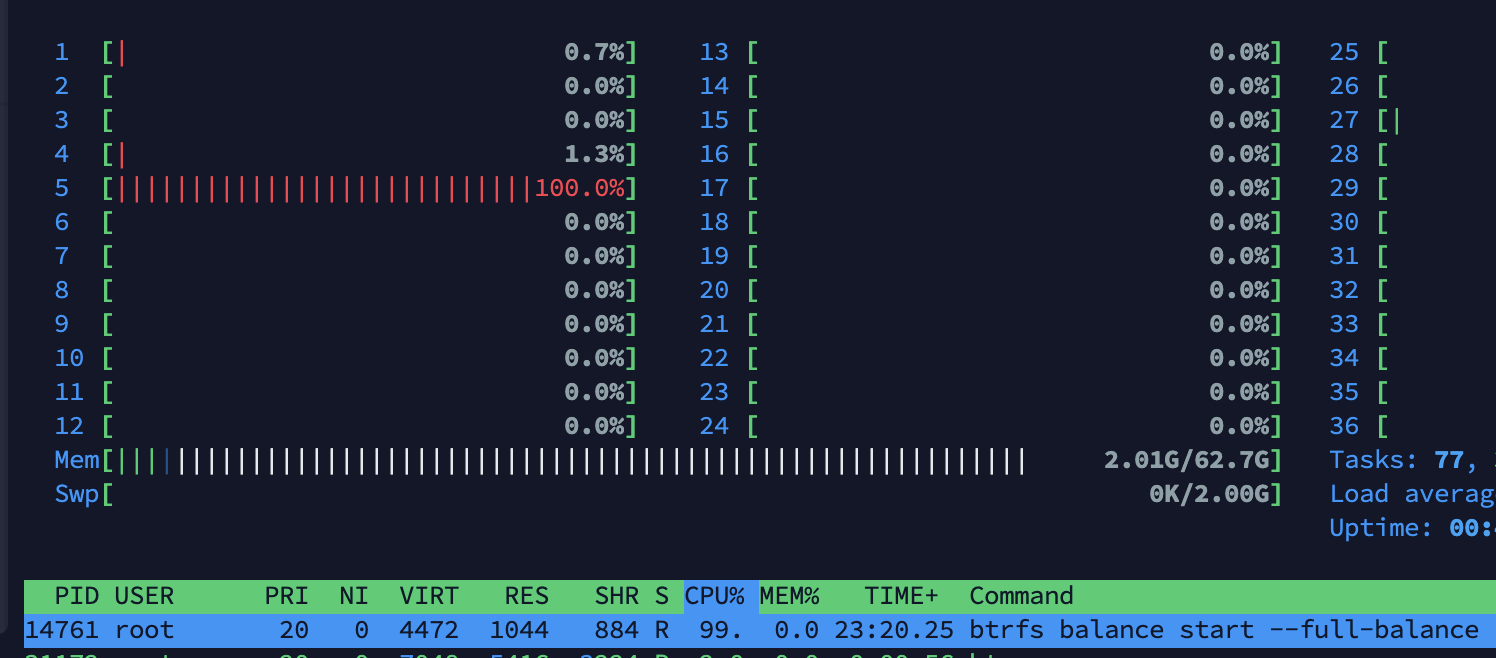
I’m playing with balance to check the performance. One interesting thing is that is using 100% CPU for only one CPU.
Does btrfs know about multi-thread? Or it’s something that I need to activate?
That’s a tricky one. I’d first like to establish an opt-in utility for lets encrypt because as always there are ‘details’. Take a look at the following issue we have open for this
and that’s just the lets encrypt part:
And of course not all lets encrypt mechanisms are available to all folks, hence my gravitating towards a dedicated port 80 solution in that thread.
Pull requests are always welcome if there are any takers on this. And of course it would be great to have this, but for many folks it’s just not going to work unless they also have port forwarding enabled (in on a private network) or can only use DNS auth or whatever. So maybe this is something folks could discuss in a dedicated thread, using that issue as a base for where we are up to. And yes, once we have an established robust system we can maybe effectively intergrate it but I don’t quite see it being that easy just yet. Too many variables and the like and folks need to be able to get into their fresh install as soon and as easily as possible. If you fancy starting a thread with some ideas and link to that GitHub issue we can see if their is interest/takers on getting this sorted.
In parts very much so, in others very much not so. And remember you are also using the youngest variant via the parity raids. It’s actually quite a mix from what little I’ve heard of the architecute at this level. Again these architectural questions are better asked of the btrfs-linux mailing list, or of other btrfs specialised mailing lists / forums. The Rockstor dev team is very much a user of this software, we don’t as-yet have capability to contribute back to it. Although I’ve made a trivial doc contribution (not yet merged) and I believe a forum member has had a successful doc pr merged and Suman made some contributions to the wiki. But nothing on the programming front that I know of. It’s super highly specialised, and entirely (usually) non trivial.
Out of curiously why are you doing a balance prior to returning the pool to a healthy state, i.e. non degraded mount. Or is the ‘balance’ you are referencing here an ‘internal’ one initiated by a missing device delete command? When the pool is mounted degraded it is non representative of it’s usually state: that of not being mounted degraded. So best to get it mounting regularly before you do anything else. How many missing devices does this pool now have?
Shame about all those unused cpu cores, alas the future is as-yet not here apparently. Do keep us posted as this is turning into quite a journel. And does your use case, post restoring this pool, allow for say a raid10 migration as that, along with some of the usual tweaks, ie quotas off, noatime, & space_cache=v2. Looks to be the best all round performer. But only has a single drive redundancy unfortunately. Otherwise it’s using something like emerging mix of parity raid for data and c2/c3 for data. Not within Rockstor’s capability yet and still also too young for my liking but still. Another note on the performance front is some more recent tweaks where you can have metadata favour non rotational drives. But again not yet released but looking promising. Can’t find the linux-btrfs mailing list entry for it currently. However as we are now moving to an upstream supported kernel these goodies should trickly down to us as and when.
Also have you take a look at the default performance comparisons of the btrfs raid levels done earlier this year as part of an article by Phronix: https://www.phoronix.com/scan.php?page=article&item=linux55-ssd-raid&num=1 Might be interesting given your trials. All apples and oranges with the other file systems listed as they are using mdraid but interesting to see the difference across the btrfs raid levels for each type of load. Plus they are all ssd drives so not representative of spinning rust. so theirs that.
“Btrfs was tested with its native RAID capabilities while the other file-systems were using MD RAID. Each file-system was run with its default mount options.”
Popping in here given this thread has quite a few performance related elements now.
I think for start this can be a checkbox that can only be activated if your hostname is getting resolved to your IP. I know that it will not be for everyone, but at least for those with public IP’s.
Then It can evolve to have a mDNS mechanism behind with a port forwarding etc.
It’s just an idea to make it more fancy
I have subscribed to btrfs-linux and asked the question there
Remember that I read something similar a few years ago, but seems that this one is updated. I’ll give it a go, thanks
Currently, I’m trying to understand if going to ceph will be a solution going forward for my raid6 system. As of now I only have two storage devices, not sure if that makes sense but I’m seeing that it’s very flexible (that’s why I have started with BTRFS over ZFS) you can add/remove any HDD, add another one with another size, etc… as ZFS it’s quite hard to manage. If you get stuck for example with 60 old HDD’s in one vdev you cannot upgrade them to newer HDD’s with a bigger capacity etc. BTRFS was exactly what I was looking for for my needs and performance is great except when you have an HDD failure and troubleshooting becomes a hobby
Yes the cluster file systems are very interesting, and particularly nice of large file systems requiring varying/flexible levels of redundancy. I have ambitions to integrate an easy Web-UI initiated Gluster/GlusterFS system (https://www.gluster.org/) within Rockstor as I like the idea of each ‘node’ still be independently a file system where you can still read files ‘regular like’. This I had planned could be run either intra-rockstor across multiple pools within a single Rockstor instance, or for the more discerning redundancy lovers across Rockstor instances, i.e. inter-rockstor. Our existing replication system already has some inter instance communication so we may be able to build on that to aid auto-config of such a thing. And Samba apparently has the capability to work with Gluster to pick from available noted to effectively do fail over capabilities or allow for ‘downing’ an entire Rockstor Gluster node for maintenance/upgrade etc. But alas I have my hands quite full with our distro migration and then our technical debt. But it’s definitely something I’ve been looking into and fancy seeing to fruition during my maintainership of Rockstor. And I really like what I’ve seen of Gluster so far. Plus it seems a natural extension to the redundant storage problem.
Forgot about Gluster, I remember I played with this one in 2010 but this is just a brick over existing FS if I’m remembering you cannot have RAW r/w on the HDD with it to create a cluster raid as ceph? Or they evolved? I’ll check it to see what’s new. Last time it was something extremely easy to deploy, 2-3 command lines
New update.
Waited to have more updates on tumbleweed and I have tried again the device delete missing yesterday. I have the same situation, is taking ages and r/w performance is ~95% degraded.
Going forward I think have 3 options (all of them implies migrating the data over and destroy the pool and I already have new 7 x 16TB shiny new HDD’s to start with):
Create small BTRFS Raid5 pools (4-5 HDD’s per pool) or Create Raid5: 7 x 8TB, Raid5: 7 x 8TB, Raid5: 5x14TB, Raid5: 7 x 16TB (just to have small pools to recover faster and to not have my entire storage degraded. Then make a union pool with BeeGFS (Gluster is way to slow with parallel tasks; MergerFS - never tested). I don’t know if I’ll take more risks with BTRFS, to be honest
Same scenario as above but with ZFS. ZFS already has a union pool feature or I’ll add on top the BeeGFS just to be able to expand in the future with another enclosure.
LizardFS v3.12 with EC8:2 (MooseFS Pro will be a better choice but it’s way too expensive for my needs) or Ceph v15.2.1 with EC8:2.
Pros:
BTRFS: flexibility to increase the pool with higher disks. I don’t need to replace all of them in a pool. In theory, faster pool recovery after the device is replaced (in theory ). Last but not least: the awesome Rockstor team members
ZFS: Stability. Everything works as intended.
LizardFS (free, high performance, easy to maintain); MooseFS (active dev, better performance, supported over time); Ceph (active development, lots of documentation and use cases, good performance).
Cons:
BTRFS: the current issue that I have
ZFS: in order to migrate to bigger drivers I need to upgrade all of them in one of my created pool before growing the disk space. This will take a higher investment and longer time to rebuild the pool 5-7 times. Also the risk of rebuilding over and over with a raid5 . If I’ll go with a larger raid6 then the HDD upgrade will take longer and it will be more and more expensive.
LizardFS dead development; MooseFS crazy expensive; Ceph high requirements to have top performance (RAM for storage; desktop CPU to keep the CephFS performance up as is running on a single-thread).
I know I’m going a little off topic but I’d appreciate if you guys can add some wisdom based on your sysadmin/storage experience that you have
I’ll answer to my question maybe others will find this info interesting
The way forward:
OS: OpenSUSE Leap 15.1 or 15.2 with Rockstor on top
OS Raid1 2 x SSD’s with BTRFS.
Erasure coding 8:2 with LizardFS.
Metadata on BTRFS Raid1 (2 x NVMe’s)
Every HDD will be created as individual FS with BTRFS and on top LizardFS will handle the chunks.
TL;DR you are not getting rid of me yet, I’ll stick around for a while
After performing some tests on VM’s seems that LizardFS offer the same read speed as BTRFS Raid6. Tested also BeeGFS but it’s slower than BTRFS Raid6/LizardFS (~20-25%). My first concern of using fuse as mount-point but seems that they adopted fuse3 and nfs-ganesha so it’s good to go
@shocker Thanks for the update. This all seems rather level ladened.
I’m afraid I have nothing to contribute on the LizardFS front knowledge wise.
But re:
What type of Raid1 is this. The openSUSE btrfs root doesn’t yet support mutiple devices on the btrfs front. And neither does Rockstor. But in time they both should.
You may have already done all your research but have you considered a lower layer to gain performance, given that was one of your main problems. I.e. bcache under btrfs. Rockstor should recognise this arrangement, given the udev caveat below, but there is no Web-UI to set it up. See the following for some details on this:
Not sure if the udev rules there are necessary anymore as haven’t tired bcache on openSUSE but Rockstor depends on the structure of the names created in those udev rules so you may have to enforce/replace them if openSUSE has it’s own and they work differently.
Does introduce single point of failure but you still have a single CPU / PSU / memory bank presumably. And bcache can be turned to passthrough (essentially off) mode. Or can be tweaked. So I had meant to mention this as an additional performance tweak possibility. I.e. a top quality nvme as the cache device.
On the btrfs dev list there looks to be tweaks comming where one can specify metadata to be stored on non rotational devices, if available, within the pool. So we should keep an eye on that feature if it ends up being standard. Most likely then a mount option.
Good to hear
Do you fancy giving a quick description of LizardFS. Sound like a GlusterFS type thing. And in which case might be worth doing your same tests with a modern GlusterFS as that appealed to me more as a cluster filesystem that still had a real filesystem underneath, unlike Ceph. Plus its got a pretty long history now. Are you after further redundancy that btrfs raid6 can give, hence btrfs raid1/raid10 single disk failure not matching your requirements.
Oh and have you checked your existing disks and the new ones as not being ‘secret’ DM-SMR drives. If your existing ones are then that would explain some of your performance issues. I believe no Seagate NAS drivers were but some WD and Toshiba were selling DM-SMR as NAS which is just no good at all. Just another thought as it was recent news.
Anyway just though I’d say about the bcache option really as it’s been in the kernel for years and is very well respected. And you main issues seemed to be performance related.
Do keep us updated on your adventures, I’m sure many folks here will be interested.
During the OpenSUSE installation, you can choose to have a Raid1 on BTRFS and set / as a mount point. I do have another tiny SSD 120GB HDD for the boot and swap.
Never tried this in the VM, but I’ll give it a go.
Most of my concerns, to be honest, are regarding the scalability and ability to control the IO during rebuild to not affect the performance.
I was referring to LizardFS metadata. Basically it’s one binary file that sits in a folder and this needs to be accessed quite fast. Also, most of the ongoing operations are sitting on RAM.
Tested Gluster but with multiple file operations is quite slow. The best alternative of GlusterFS is BeeGFS.
I had two options:
Go with ZFS Raid and add on top a “unifying fs” like Gluster (in this case was BeeGFS) or find a solution with erasure coding and get rid of the raid.
Big players here with erasure coding are CephFS, LizardFS, MooseFS, and RozoFS.
Erasure coding ( Erasure code - Wikipedia ):
Everything that you write is divided into chunks and you have replication for the chunks on the HDD. Let’s say you choose to have 3 chunks with 1 replication, this will be something similar to Raid5 but distributed across the servers. If you choose to have 3 chunks with 2 replications then this is similar to Raid6. For example with LizardFS you can go up to 32 chunk servers with 32 replications
LizardFS (Raid6) equivalent:
Let’s say you have 20 HDD’s. You can create a filesystem for every HDD (can be xfs, btrfs, zfs, etc) and you can mount every HDD to a mount point:
/mnt/hdd1, /mnt/hdd2, etc.
Create 5 chunk servers and in every chunk server, you can add 4 HDD’s.
Then LizardFS will distribute the chunks evenly on all the HDD’s in order to balance them and if you set parity 2 you will have the ability to lose two drives, similar to raid6.
What is nice about LizardFS
Gols: for example in your pool you might have a folder with an iso mirror. You can set that folder “iso” to be without parity and by this you can gain space. Also, you can set for folder pictures parity of 6 as this is critical for you, etc.
You can add and remove HDD’s as you like, doesn’t matter the speed, the size, etc. and also you can add one at a time.
Scale as much as you want
Crazy fast to implement/configure and also they have a nice GUI to monitor.
Cons
Slow/dead development. It seems that now they created a strategic partnership and the development is not on track.
Why LizardFS:
CephFS seems to be the best solution but you need lots of resources to implement a proper solution (1 GB ram for every 1TB storage, desktop pc with a high CPU for the FS, etc).
MooseFS is the best solution as of now, LizardFS is a fork of MooseFS but for erasure coding, they are asking lots of money. They are charging by TB. For my needs it will be way chipper to double to storage that I have and create a high availability cluster
RozoFS way to complicated to implement to maintain.
LizardFS opensource, free, fast, easy to maintain, the stable version is production-ready.
There are also others but don’t fit for purpose
After spending months on reading about every solution invented till now and tested on VMs play with HDD loss scenarios etc. for what I need this will be the best scenario to go further.
Something is not clear and maybe someone can clarify. On Raid1 with BTRFS only data is replicated, right? Meaning that TBW will not be the same on both NVMEs to risk of losing both at the same time . I know that for sure with ZFS only data is replicated but with BTRFS I just assume, didn’t test yet.
Interesting, not yet. I have 14 x 8 TB HGST; 5 x 14 TB Toshiba. The newer ones are 7 x 16TB Seagate. I’ll check today, thanks for the tip.
If that is now a supported config that’s great. Had a quick look and there is mention of multi-dev / support arriving more recently. I’ll have more of a look when I’ve got more time. I have in mind some changes that should help Rockstor understand this arrangement too but the are going to take time unfortunately. Likely it will just look ‘confused’.
Thanks for the nice run down on LizardFS, if it is indeed returning to an active state and has some dedicated backing on the development side then maybe I should consider that instead of GlusterFS. Do let us know how this all goes.
Does sound like you are after a cluster filesystem. Which I think btrfs, if an underneath filesystem is required, is a nice choice given it’s check-summing/raid and what not.
Erasure code theory looks interesting, on just a quick look it’s like adjustable error correction/redundancy.
Nice.
Do keep us informed.
The opensource bit is a must for us to incorporate.
It depends, btrfs can have different raid levels for data and metadata. For instance some folks are using raid5/6 data and raid1/10 metadata to get around the current write/hole and to boost metadata performance. So you could have raid1 data and single metadata and then metadata would not be redundantly stored. But I believe the default is to have dup, metadata. Although it may be raid1. Rockstor plays with these a little to ease flexibility re adding removing drives but we definitely need to re-visit these, but the plan is to first expose the actual metadata level on the Web-UI first, then we can take tweaking them from there. As always, lots to do. But at the lowest level we already read all raid levels on every pool; data, metadata, system, reserve.
That’s not likely really. And they should both be used pretty evenly actually if on Raid1 as it currently uses a round robin approach I believe. Could even be odd/even on pid. Not that up on the lower levels though.
Something to be aware of is that on non rotational devices btrfs will default to using single metadata. Don’t do this, force otherwise. It’s a questionable default that is occasionally questioned on the btrfs mailing list. Something to do with ssds doing internal de-duplication internally so might as well not bother. I say to bother in this case. Again Rocktor enforces dup I think. Again would be nice to surface this. I think we will do that soon actually. Just got to get the ‘Built on openSUSE’ variant in Stable and out the door first.
I’m not so sure on that front, but only had a few years playing with ZFS as a user before my btrfs/Rockstor obsession
Thanks for taking the time again to share your reading up on all of this. I’ll try and take a look at LizardFS vs GlusterFS as would really like to offer an easy Web-UI intergrated setup within Rockstor to turn it into a Cluster capable storage system as the next logical step up in storage redundancy and serving larger file sets. My long term aim is to have an trivial cluster setup where on can down an entire Rockstor instance and replace it a-fresh and have it rejoin trivially to the cluster and be re-silvered auto style. That way folks can have multiple Rockstor instances serving a single cluster file system and gain major maintenance advantages.
Another very popular is Jerasure (this is most common with Ceph). I like Reed Solomon as they are keeping it simple and I the math behind
If you want an alternative to GlusterFS but way faster → BeeGFS (you cannot use it with BTRFS, but works great with ZFS).
If you need a very fast OS for small files (not my case) have a look at SeaWeedFS. But they don’t have erasure coding.
LizardFS can be a replacement for Raid5/6 from my point of view. You can achieve Raid5 with XOR and Raid6,7,8… with EC.
If you want to try it out, I’ve already built the RPM’s for Leap 15.2 for the stable version v3.12 what is nice on the v3.13 (RC2 for now) is that they are using fuse3 and you are gaining more 5-10% faster speed, at least on paper. With my tests the performance was the same, maybe with huge paralel files transfer it might make a difference.
For my needs, I’ll just keep only 1 binary file inside the pool and that’s it.
Here I’m 100% sure as I’m already using this scenario on other servers for years. I can see that one HDD is on 4% health and another 7% for example. ZFS is not replicating 1:1 like mdadm or other software they are replicating data inside and it might differ.
Got quick access from one of my dumb servers ZFS raid 1 for OS:
Create a HA GUI (docker, kubernetes, proxmox, etc.)
Create a probe/monitoring script that is calling the master server to update about the system status and to deploy staff etc.
And the two scenarios:
If BTRFS will have production-ready for Raid56 you can go with BeeGFS (hopefully they will update for BTRFS support or you can add a BTRFS patch to show the inode allocation and not show 0 on BTRFS (it’s already available somewhere). Easy to implement, kernel-based (no fuse), awesome speed. I have already created a script to automatically deploy it on OpenSUSE for my testing, let me know if you need it. Then you just add pools to BeeGFS (similar to bricks on Gluster) to increase the size.
a) If you don’t want to use Raid5/6 with BTRFS than XOR/EC is the way forward (exactly what I’m doing right now). If you will go with LizardFS for XOR/EC then that will be crazy simple as the master/metadata server can sit with GUI and on each bare metal node, you can install the LizardFS chunk server and the Rockstor monitor script. Or you can let the flexibility for the users to scale it or add it along with other nodes. But a docker/kubernets deployment will be easier for the scalability and simplicity.
b) Dummy mode with SnapRAID and MergerFS.
SnapRAID is not a proper RAID solution, basically, you can have whatever filesystem created for every HDD, add content on it (you can even start with HDD’s already filled with data) and every file will be stored on a drive (not on multiple like Raid). Then it will create some parity drivers to recover data if a HDD is lost. With MergerFS on top, you can make the clustering thing and have everything on one big pool across your servers.
SnapRAID Pro
Can start with already filled HDD.
If you change your mind, you can uninstall and read the data directly on HDD.
Can use whatever FS you want: XFS, NTFS, BTRFS, ZFS, etc. it doesn’t matter as long as the data is accessible.
Parity of 1,2,3…6 drivers
Data integrity, scrubs, etc…
Electricity costs. If you are a small user and you need to read data from only one hdd, the others can idle.
SnapRAID Cons
Speed as the data is not replicated you will have the max speed as the driver speed where the data is stored.
Have a look here: SnapRAID
Let me know if you need extra help regarding a solution as I’m currently up to date with almost everything that is running on the market
Cheers.
UPDATE: Oh, and for most home users I think the key element will be scalability (not only cluster size). Everyone wants to keep the costs low and for example, if I have on my server 10 x 4TB HDD’s I would like to replace them with 10 x 16TB and not buy another enclosure. And If I cannot afford to buy 10 x 16TB on one order I can start with replacing only 1 x 4TB with 1x16TB and that’s it.
Something similar with unRAID but without the limitations (max 30HDDs, no data integrity check, OS on USB and if you lose the USB you need to replace the license and you can do this only once a year (I know, right? ), you cannot use if for free, etc) and I think this is where Rockstor can take the lead.
P.S. I’m not doing this migration for clustering, but with clustering and scalability in mind. I will currently deploy this on one server. Start as small as possible and you can grow as much as needed
Even that I destroyed my faulty raid6 now I switched to smaller pools of raid5 added on a GlusterFS.
Everything is restored and up and running. So far so good with GlusterFS v7 running only large files and I’ll share more about this after a month of tweaking and testing
 but this is just a brick over existing FS if I’m remembering you cannot have RAW r/w on the HDD with it to create a cluster raid as ceph? Or they evolved? I’ll check it to see what’s new. Last time it was something extremely easy to deploy, 2-3 command lines
but this is just a brick over existing FS if I’m remembering you cannot have RAW r/w on the HDD with it to create a cluster raid as ceph? Or they evolved? I’ll check it to see what’s new. Last time it was something extremely easy to deploy, 2-3 command lines 

 yey another one fixed!
yey another one fixed!