I started to migrate data from my old disks to new ones. Both disks are mounted via rockstor.
I use the “mv” command on the CLI to move the data to actuall disk/pool as root.
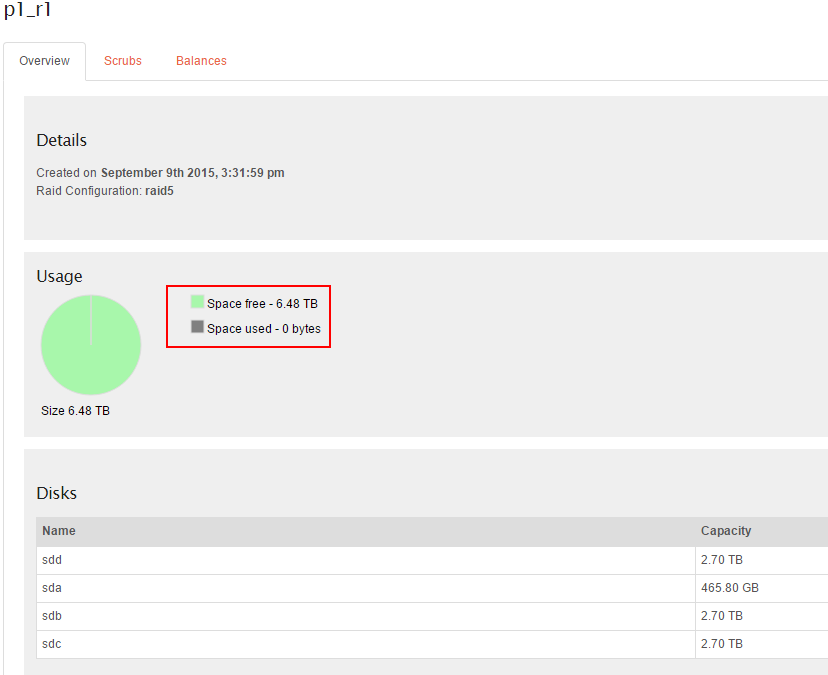
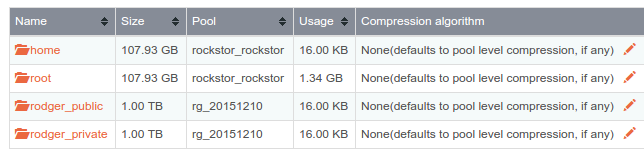
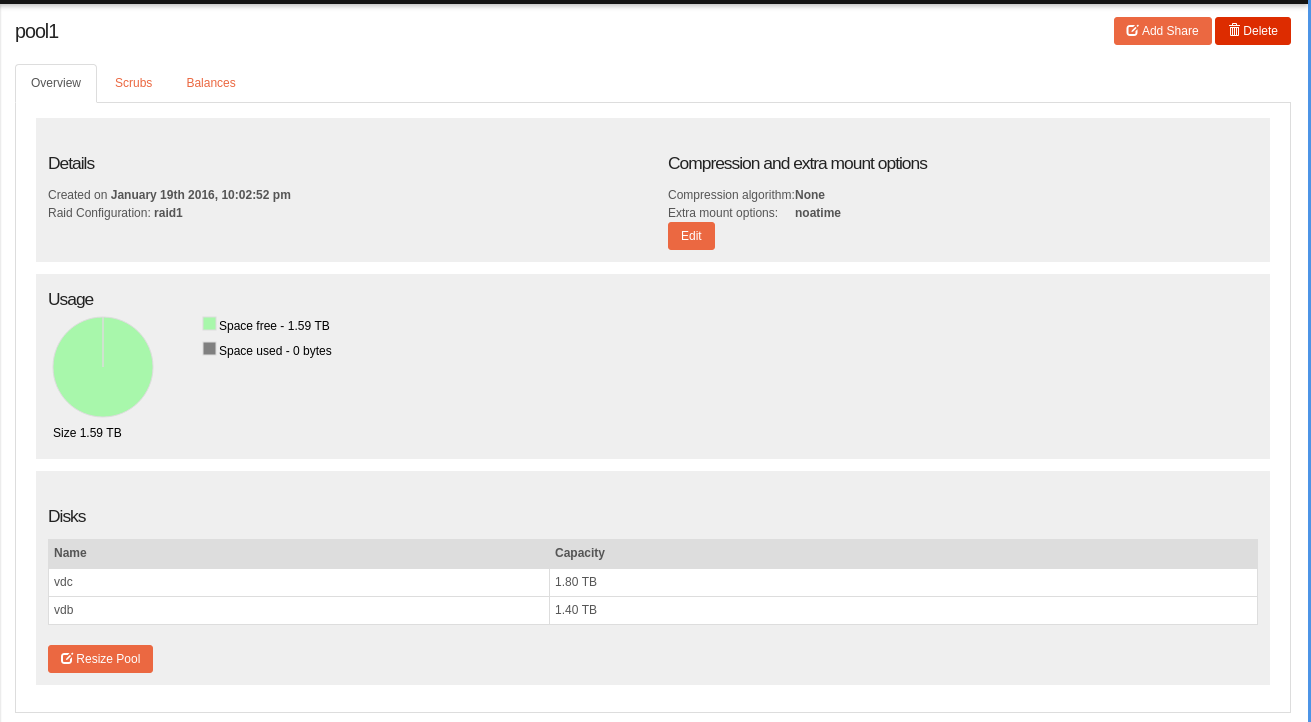
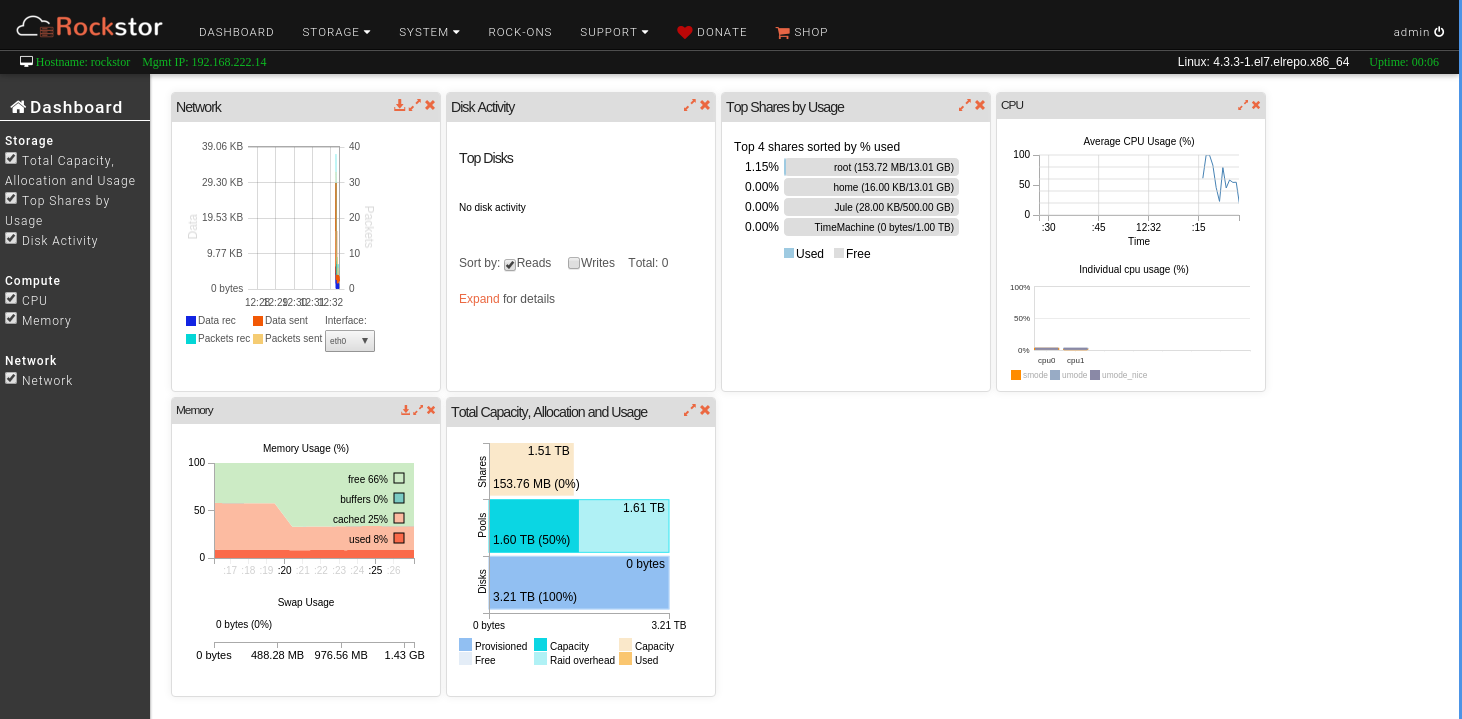
If I look onto the Web-UI the usage information still shows 0% used on the new pool and new shares the data is flowing into.
Is this in purpose? I have already migrated 2,5TB of data.
after a reboot I can see the usage on the share but the pool still says 0% usage.
also the information in the Web-UI
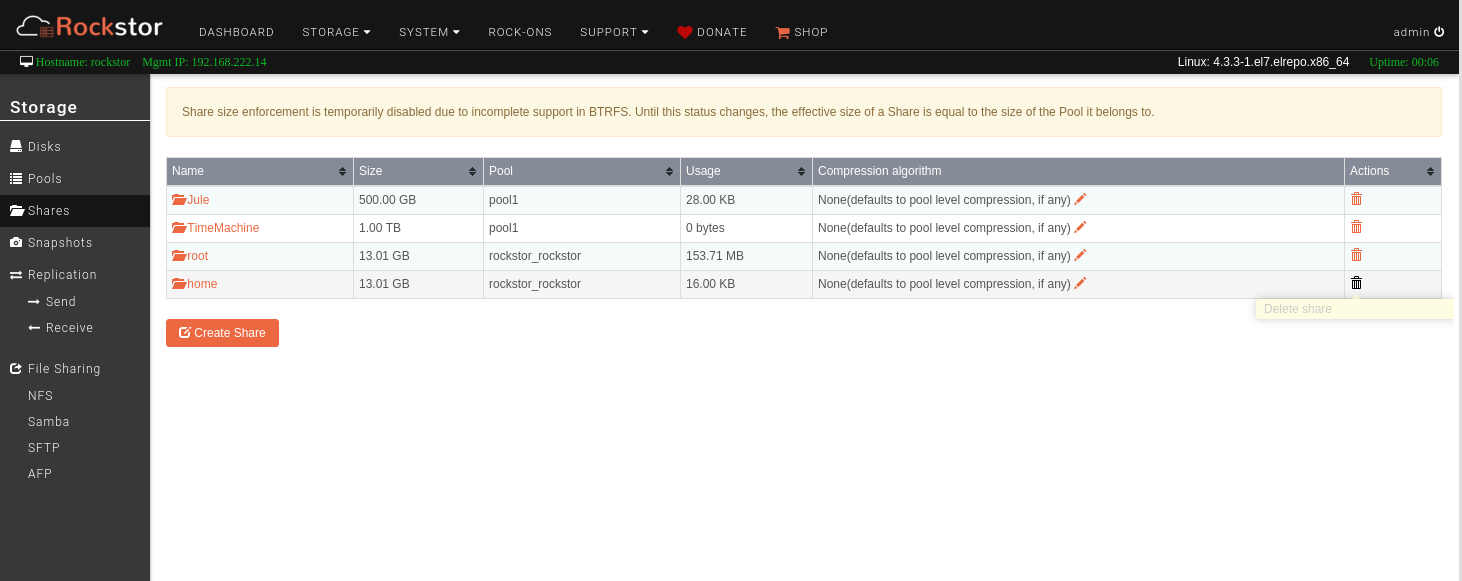
Share size enforcement is temporarily disabled due to incomplete support in BTRFS. Until this status changes, the effective size of a Share is equal to the size of the Pool it belongs to.
is not correct, I created a pool with one disk and the share had 2.5TB, I added 2 new disks to get around 5TB. copying data to the share stopped at 2.5TB with the message
rsync: writefd_unbuffered failed to write 4 bytes to socket [sender]: Broken pipe (32)
rsync: write failed on “/mnt2/p1_r1/temp_old_disk/data/OS/Linux/ubuntu-14.10-desktop-amd64.iso”: No space left on device (28)
rsync error: error in file IO (code 11) at receiver.c(322) [receiver=3.0.9]
rsync: connection unexpectedly closed (67 bytes received so far) [sender]
rsync error: error in rsync protocol data stream (code 12) at io.c(605) [sender=3.0.9]
which for me, indicates the somehow the share size enforcement is not really the pool size
I changed the share size to 5TB and voila, the copy process worked again
your pool seems unbalanced, i would check that regardless of other things.
my last point of knowledge is from 3.8-3 regarding this, at this time the values in the “share” tab were more or less current, might need a reboot. but the pool values always showed 0 bytes. For myself the share values were current when i last checked them a few days ago.
I’m seeing the same issue with the testing virtual machine I just setup. Usage wasn’t updated on the web UI, until I rebooted. But after deleting a few big files the UI again didn’t reflect that change.
Are we the only ones seeing this? Could running rockstor on ‘real’ hardware make a difference?
I am running this on real hardware and it makes no difference, had hasn’t really changed.
Some information is still missing, or not getting updated correctly.
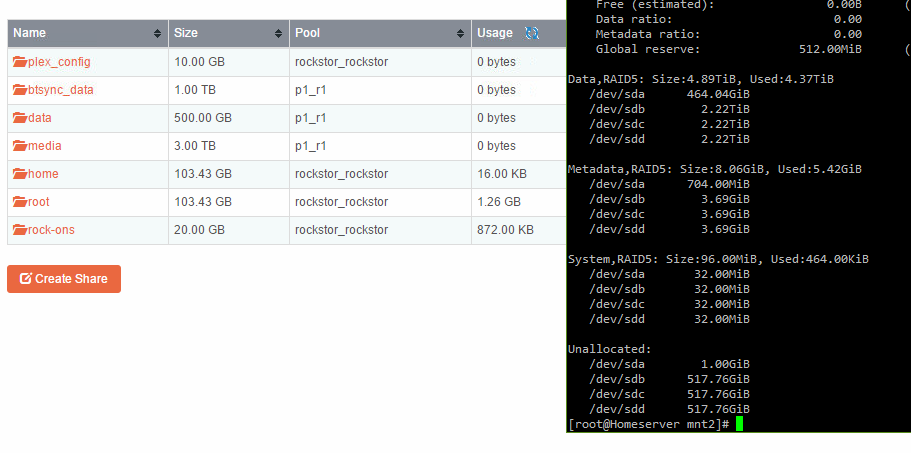
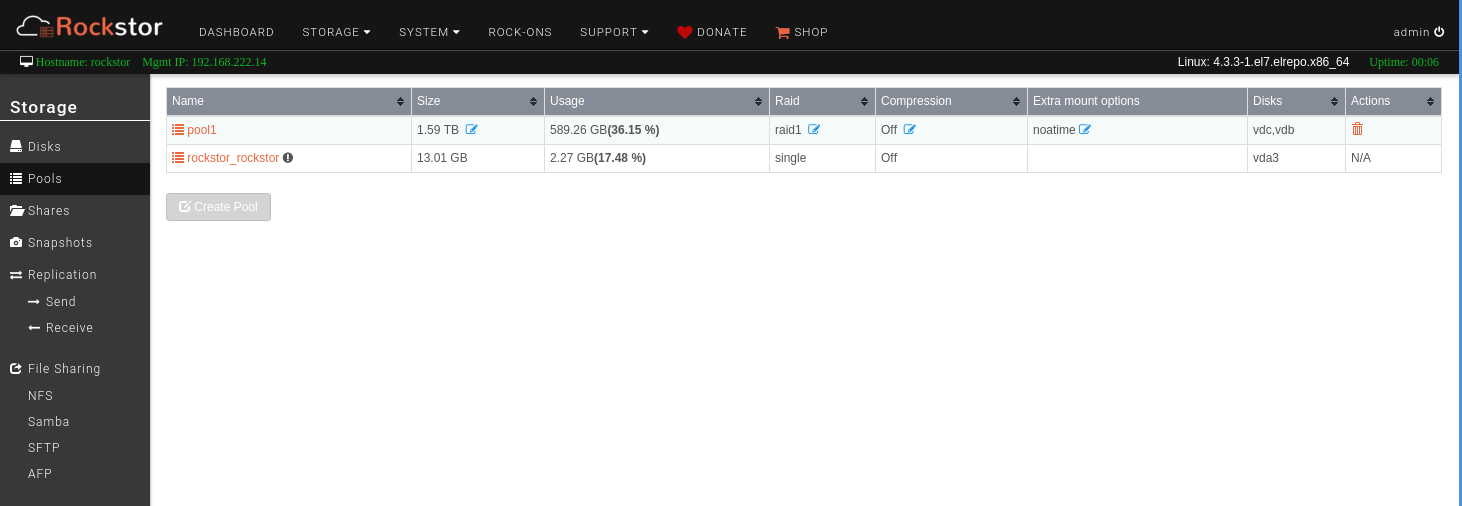
In my case I assume the RAID5 could be the issue, also CLI is not reporting RAID5 usage correctly.
Same here, on real hardware. I am changing raidlevels around quite a bit for migration/testing purposes. Doesn’t seem to work in single/raid0/raid1 either.
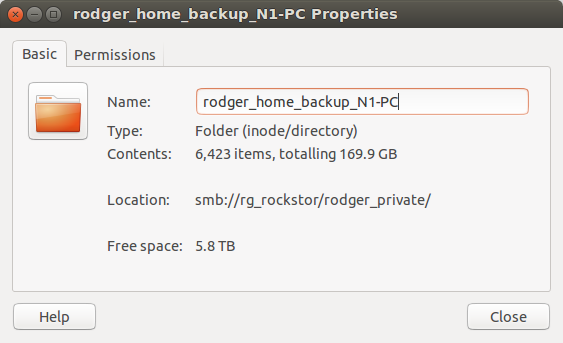
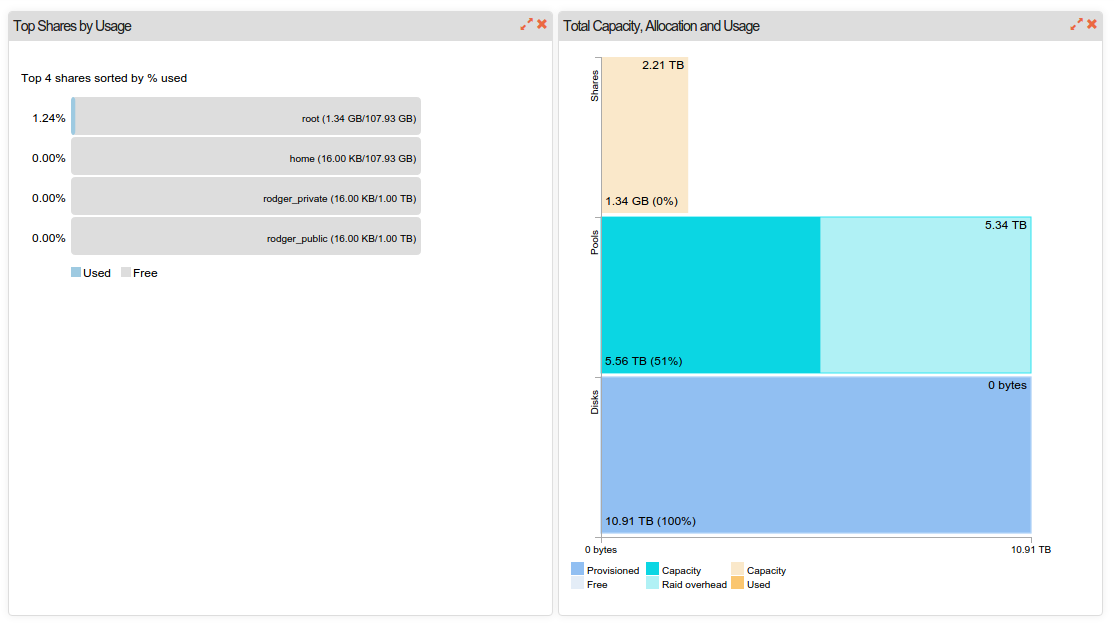
I recently set up my (real hardware) machine with RAID 10, four 3 TB disks for almost 6 TB available space. I just loaded a backup onto a 1 TB share, and even though 170 GB is shown there from my PC (Ubuntu), none of the Dashboard data reflected the used space. This is one of two 1 TB shares I made so far, and they both show “16.00 KB”, as does home. root shows 1.34 GB. I’m still basically a Linux newbie, converted about 34 months ago, so my command line knowledge is limited… It appears that the machine is working but the web ui is not reporting my usage correctly.
Just wanted to add that I too am seeing this issue. Did an install over a month ago and have yet to see the web gui display any storage usage change despite having several hundred GB of data now residing on my Rockstor hardware. Hoping to get this resolved at some point! Thanks!
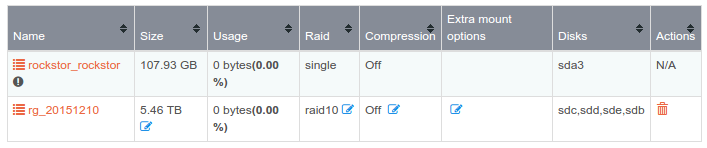
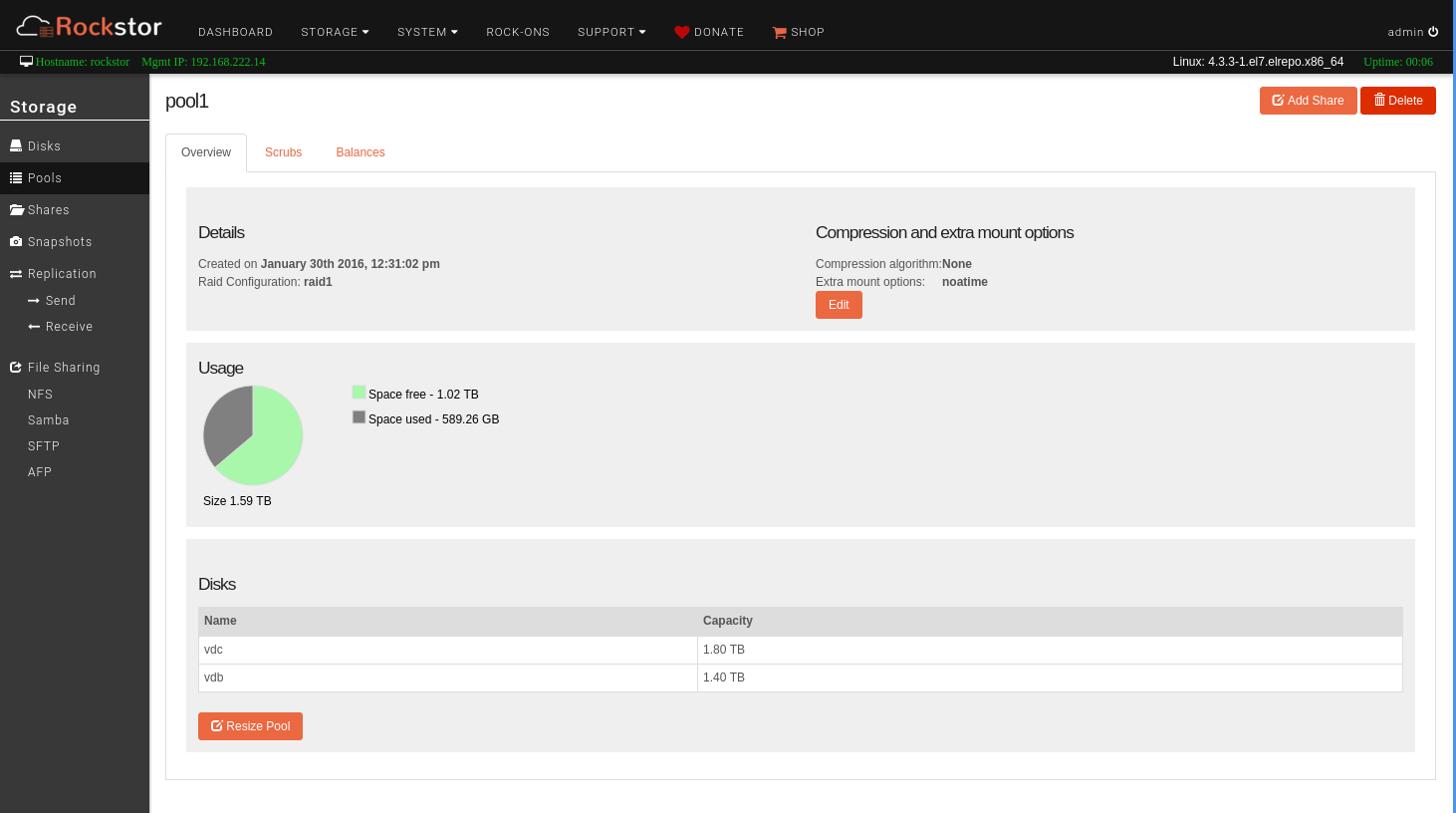
Same here. I have a pool of 1.5 TB, using it for an AFP share with Time Machine backups of two Macs. The Pool shows 0 Bytes usage. Real usage is around 600 GB.
Rockstor is running in a VM under ProxMox 4.1. Passthrough of 2 harddisks (1.5 TB and 2.0 TB).
`[root@rockstor pool1]# btrfs fi show
Label: ‘rockstor_rockstor’ uuid: 74d34467-30b0-49ea-970a-52293a10aaf3
Total devices 1 FS bytes used 2.13GiB
devid 1 size 13.01GiB used 3.56GiB path /dev/vda3
Label: ‘pool1’ uuid: 2ba854cd-9412-437c-9e29-b590a53e0d67
Total devices 2 FS bytes used 577.17GiB
devid 1 size 1.36TiB used 581.06GiB path /dev/vdb
devid 2 size 1.82TiB used 581.06GiB path /dev/vdc
I’m running 4.3.3-1.el7.elrepo.x86_64
I also tried the other available kernel (I think it’s 4.2.5-something). That didn’t help. Showed the same wrong numbers, and on top of it Rockstor complained about my using an unsupported kernel.
What kernel are you running on?
This is not related to kernel version. I just fixed it yesterday and it will be released as part of the next testing update in a few hours from now. For more technical detail, you can look at commit messages in this pull request:
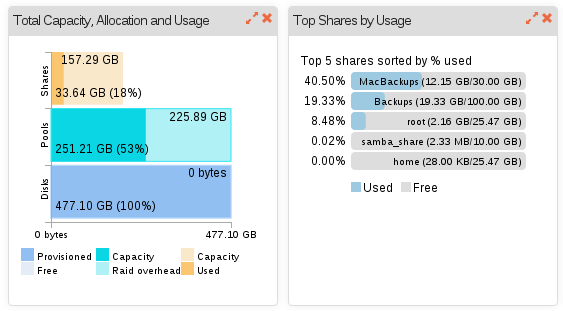
@rockstoruser Your readings do look a bit odd, specifically your root in the share summary screen shows only 153MB when it should be 1.3 to 2.2 GB ie look at @rgettler second screen grab and @herbert first screen grab.
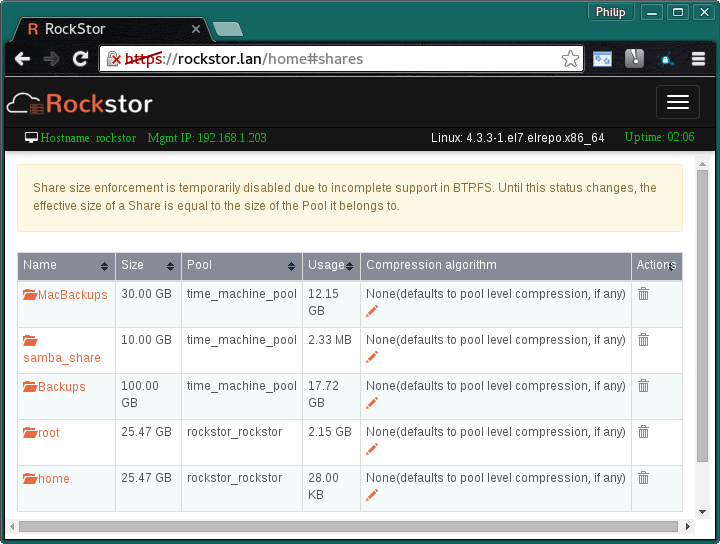
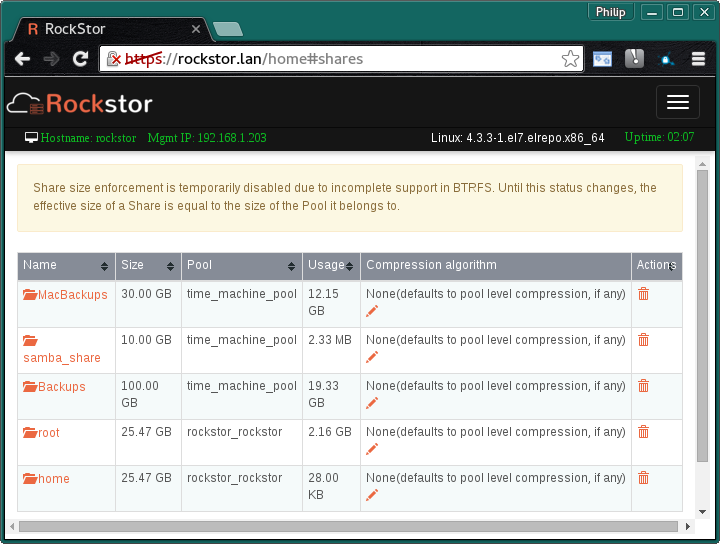
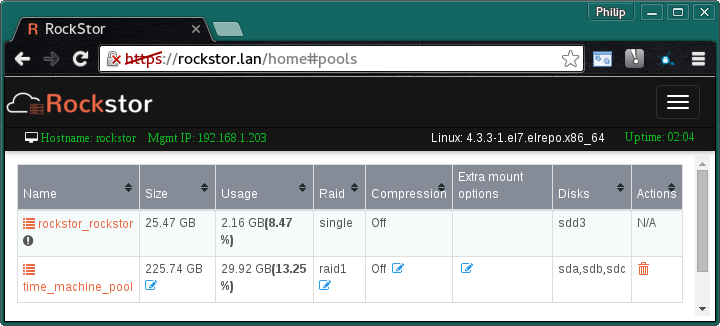
Did a little test here (version 3.8-11.03) and I’m afraid I can’t reproduce the findings of inaccurate space reporting, with the proviso that it was necessary to refresh the browser for this to be updated; including on the dashboard. And to continue the theme of this being a highly graphical thread I’ll post my findings in case I’ve missed something obvious.
Test environment is pre and post a single OSX Time Machine backup (of about 1.5 GB new data). Same arrangement used to create the AFP docs page as it goes. Real HW with 3 160GB drives in a Raid1 pool.
Note that the MacBackups share is not used in this experiment.
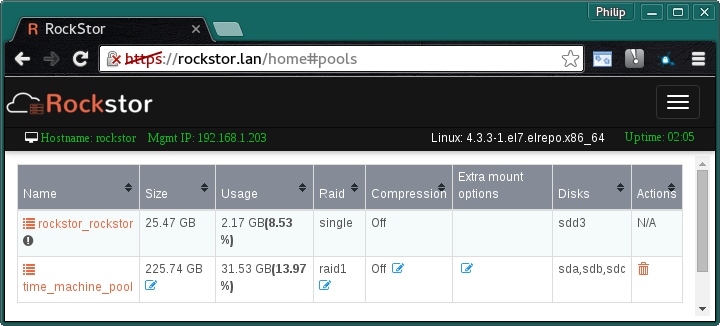
Notice the change in the Backups share on the time_machine_pool.
@rockstoruser, perhaps it was an issue of browser refresh? In case of Pool usage, it is updated instantly when the table is displayed. But for Share usage, it’s asynchronously updated by the backend. So as you revisit the Shares table(not even browser refresh), the usage should eventually(within, say 1-2 minutes) update. The reason why Share usage update is asynchronous is because there could be many many more Shares and it could take a long response time to update them synchronously whenever user visits the table. On the other hand, usually number of Pools is rather small on any system, so that tends to be pretty quick. Anyways, please report back your findings.
Even after waiting for hours, the share usage doesn’t change.
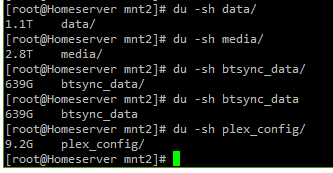
The TimeMachine backup is 587 G if I do a “du” on the command line. Still showing 0 Bytes used in the Web UI.
[root@rockstor mnt2]# du -hs TimeMachine/
587G TimeMachine/
[root@rockstor mnt2]#
Usage of the “root” share is also wrong in the WebUI. Maybe it’s easier to reinstall. What do you think?
Hello, I’m on 3.8-12.08 - just updated today and I’m seeing the same issue. My shares shows the right info, but my Pool shows nothing as being stored there.