Either I am losing my mind or ‘somehow’ VTd is NOT working properly in Rockstor-3.8-10. In 3.8-7 works fine. What is going on here. Same vSphere 6.0 U1 env from last time I was active (rockstor as NAS appliance VM w/ LSI2008 controller passed through, 4 100GB ent HGST SLC sas ssd’s hanging off.
Thought I’d let rockstor bake a bit before I tried it again, figured the new release would introduce new functionality, not break it
Color me perplexed/depressed, any ideas?
VERY reproducable and I double/triple checked I AM setting and it IS applying the memory reservation for the VM (requirement when passing through HBA w/ VTd in vSphere). Shell of VM is CentOS7 64-bit…IDENTICAL build process for each working/non-working stg appliance VM.
EDIT: Testing 3.8-9 now, will report back shortly w/ results.
NOT working in release 3.8-9 either…BOOO
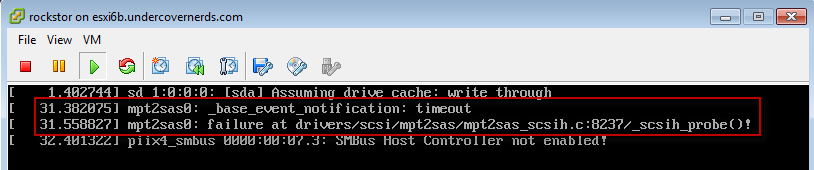
EDIT, my profuse apologies, forgot my own dang post and how I resolved this before when i hit this wall, critical to have HBA attached from the get-go/initial install otherwise mpt2sas throws a fit. Dunno why 3.8-7 plays nice w/out adding from initial install now for me but 3.8-9/3.8-10 does not work w/ VTd unless configed prior to first boot/install.
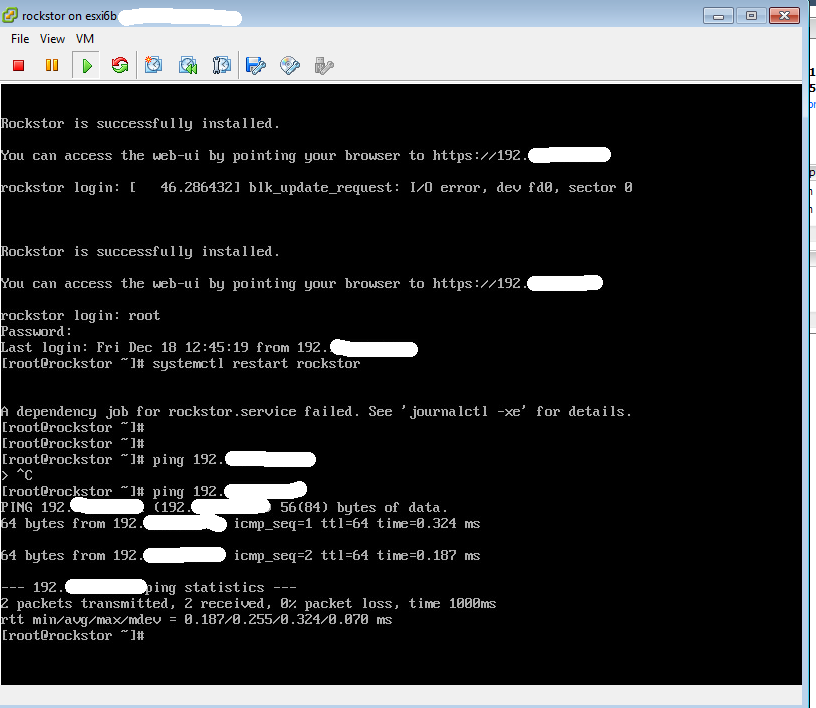
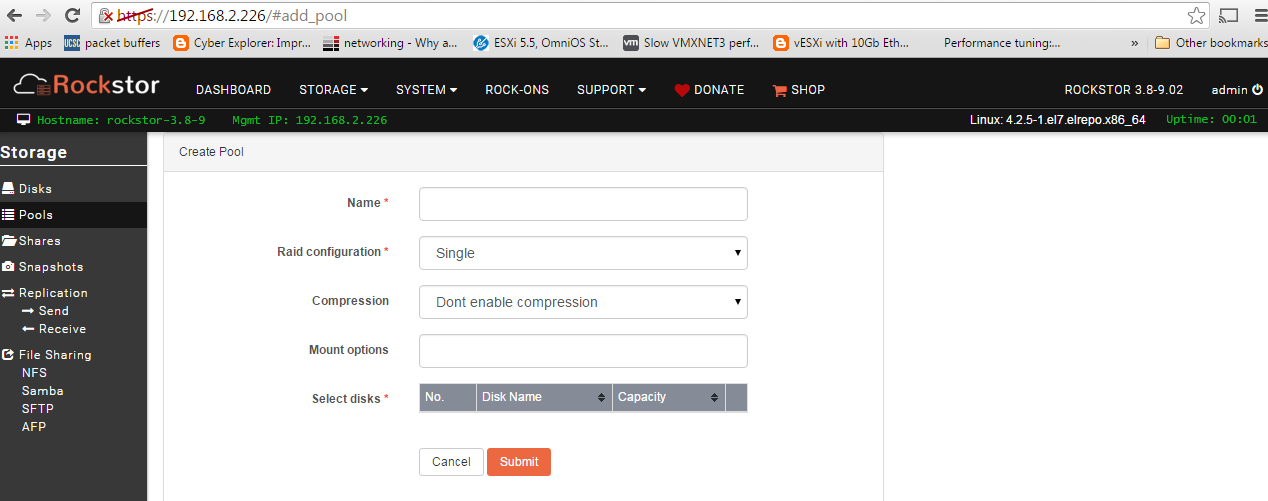
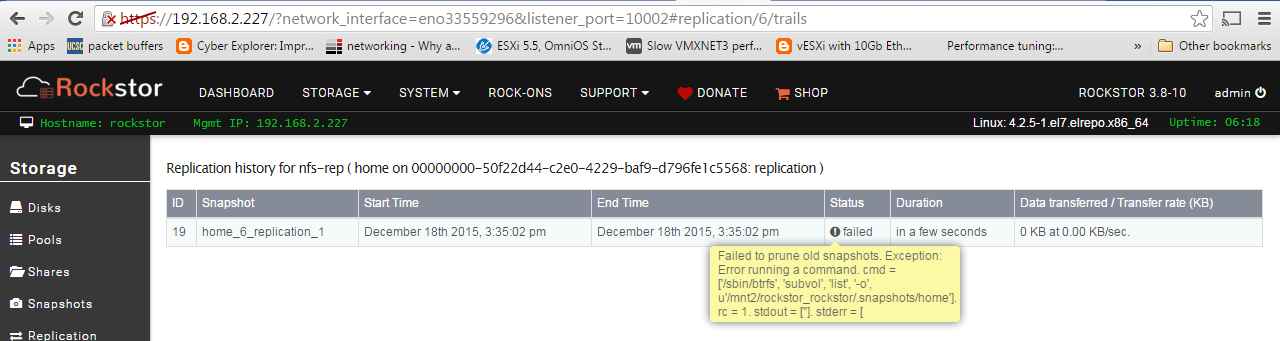
W/ Rockstor0-3.8-9 I get the following response, no mpt2sas erro on boot, sees disks in storage → disks, allows pool creation button to be clicked, does NOT allow pool creation to complete as it does not see disks in pool creation screen. (see screenies)
Would REALLY kindly appreciate some advise, still not there YET
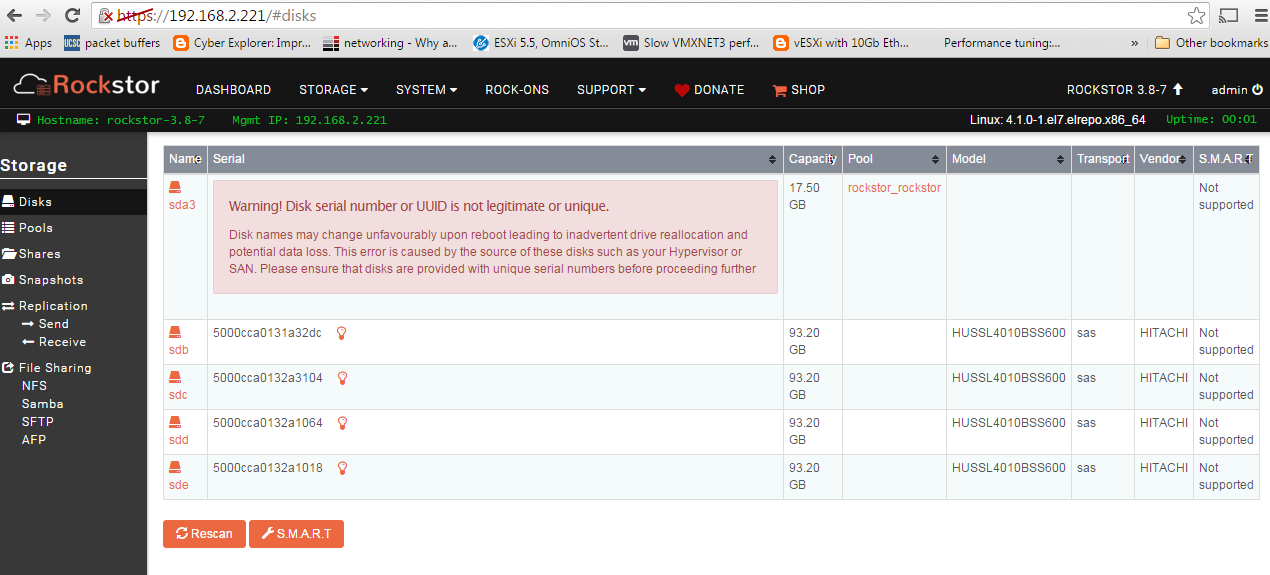
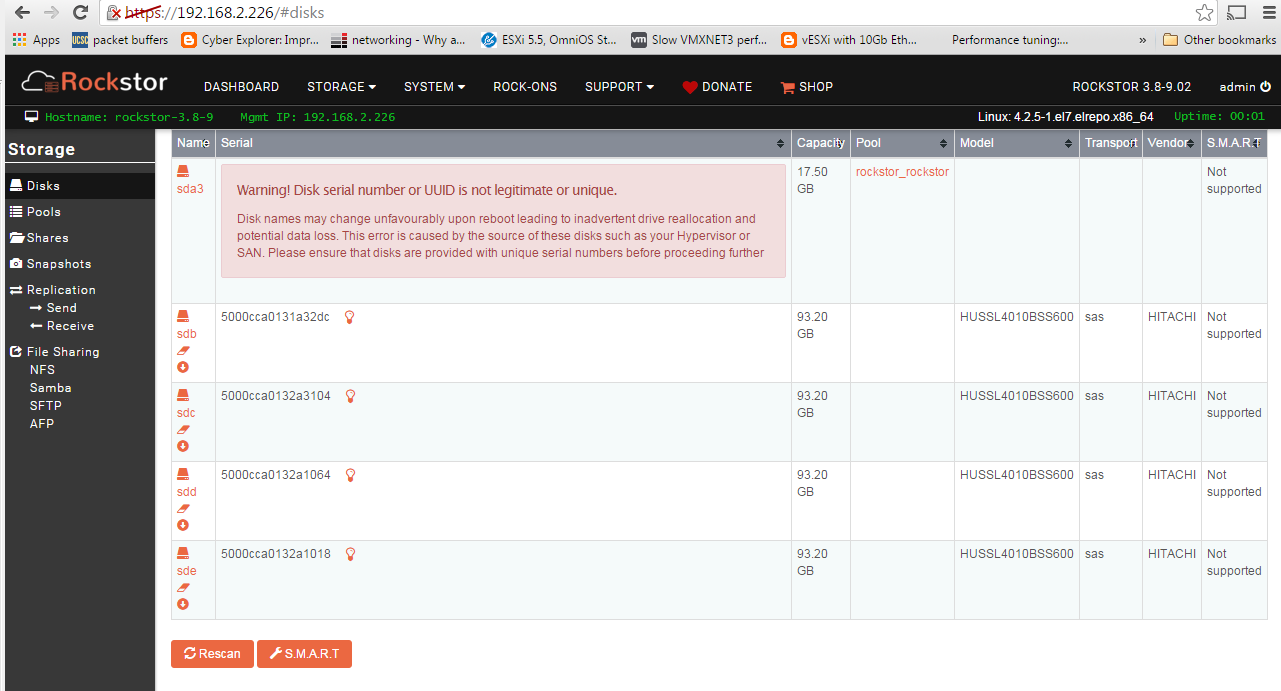
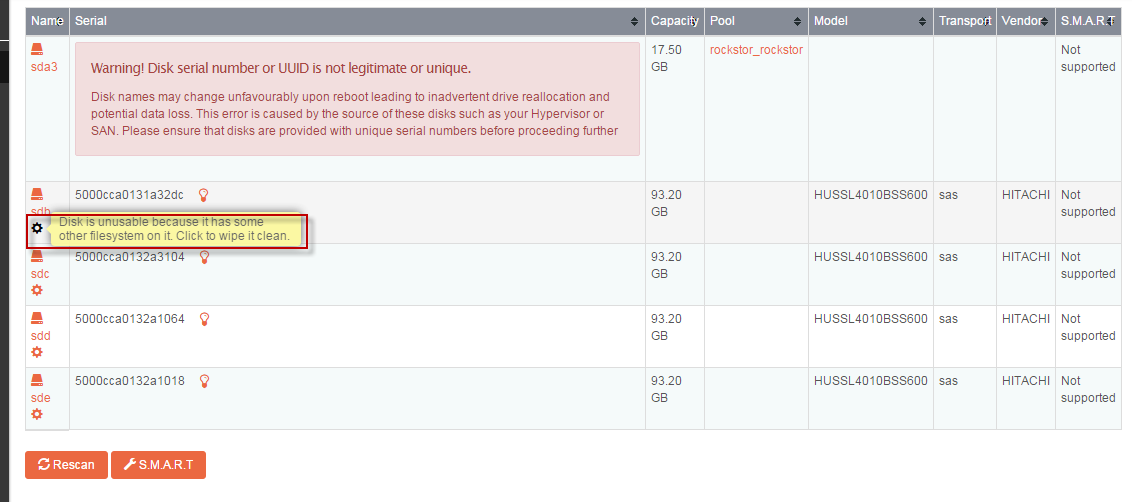
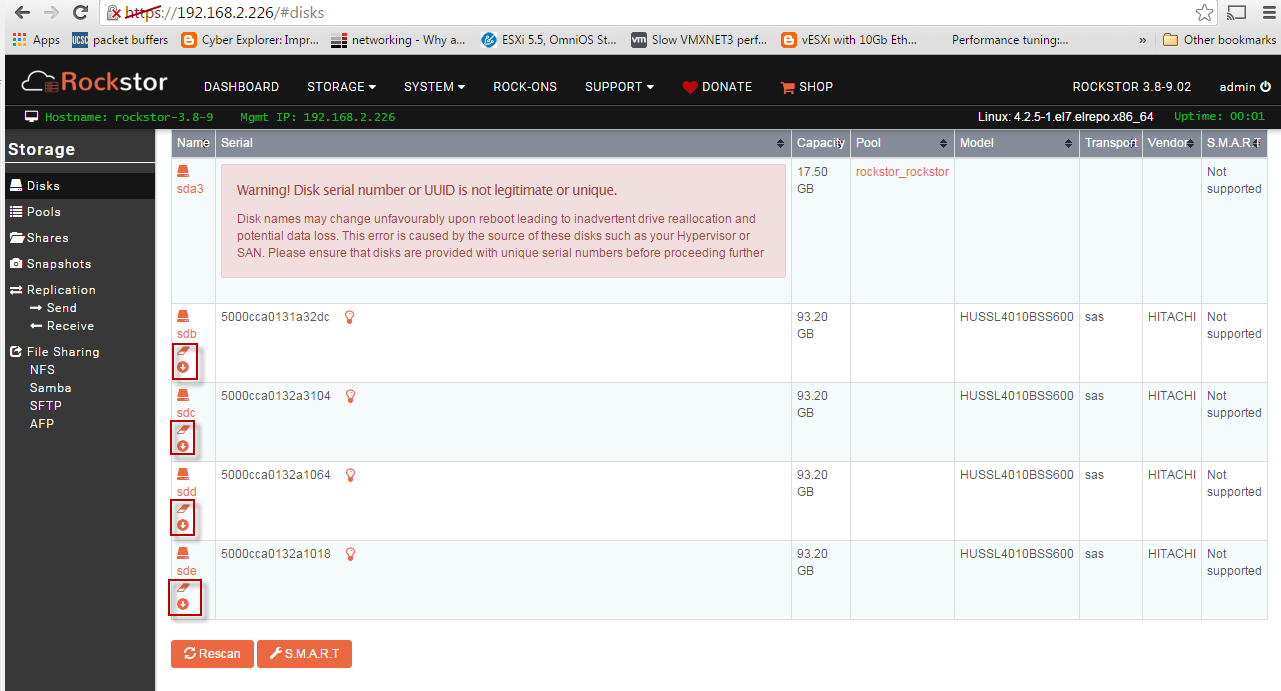
@whitey Sorry for the slow response and your frustration but I think the reason your drives are not showing up as options in pool creation is due to them already having a file system on. It’s kind of a play it safe approach. I see from the image (thanks for the images by the way this really helps) that there are little rubbers and arrows by the drives these are best explained in the docs and may well have been added since you last used Rockstor; not sure. Anyway, they offer the option to either import (the little arrow) if btrfs or wipefs (the rubber) the drives so that they might be used by Rockstor.
The documentation sections that covers this better is the Pools section “Creating a Pool” and it in turn links to the “Data Import” section that specifically details the rubber and import icons.
Hope that helps with at least that bit of your many frustrations.
N.B. You would also be best advised to heed the Warning re Disk serial in the Disk section on your sda device as this will aid in a smoother experience. Rockstor uses serial numbers on devices to uniquely identify them and without these serial numbers it’s impossible to track devices as they move around. Just make sure sda has a unique serial number and this shouldn’t then appear.
Funny about your own post on the VTd issue.
With regard to your mpt2sas probe issue I really don’t know, but there are plans to upgrade the kernel again soon so here’s hoping it has more steps forward than back on this one.
Hope this counts at least in part as a tip / trick / insight.
@whitey There are also several relevant sub-sections in the docs under the Disks section, ie Existing whole disk BTRFS, Partitioned disks, Wiping a Partitioned Disk.
I think there are plans in the future to link to relevant doc section from relevant UI sections which would be nice, it will hopefully increase the discover-ability aspect of doc sections as well.
This is beyond frustrating, so I clear the drives using ‘dd if=/dev/zero of=/dev/sda’ /b/c/d (down the line in another Linux box as this one cannot see them even w/ fdisk. Attach up to 3.8-9 rockstor appliance and STILL does not see disks, attach to 3.8-7 and BAM, works immediately!
OK, may be time for me to back away from teh ledge nad let her bake another 6 months
Then the rockstor 3.8-10 GUI gave me an option to wipe disks. What does this cmd initiate? btrfs cmds or std Linux filesystem wipe/clean disks cmds, if so what are they? I found another screenshot of who knows what release of rockstor w/ unknown buttons I must have not seen before. Any idea what they are?
Not getting mpt2sas errors anymore on boot either…that was just weird.
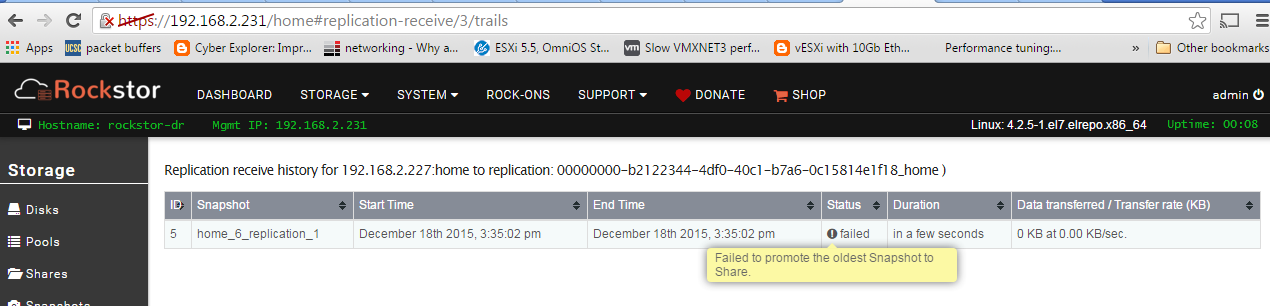
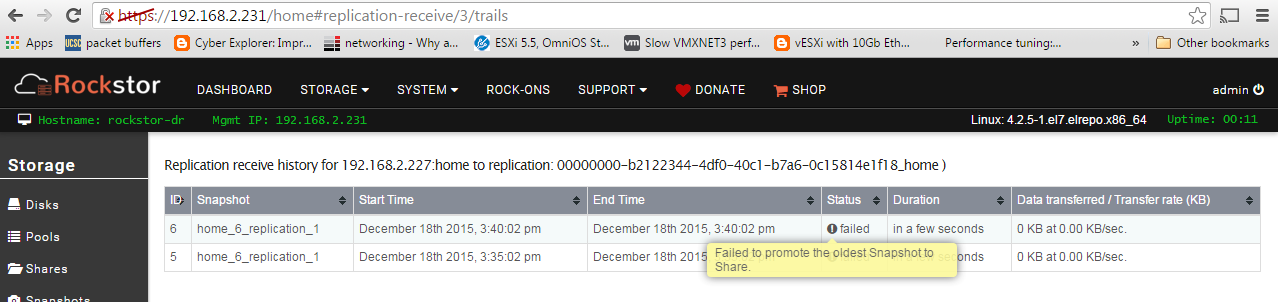
I am now able to snapshot and clone and re-share out that clone and mount up to vSP{here ESXi hosts (something I was unable to do w/ 3.8-7) and have replication jobs setup (appliances added to each other both ways) but rep is failing. Any idea why or the trick to get rep working beteween two rockstor appliances?
Still dunno what that Warning: UUID not legit/unique msg is, these run on vSphere 6.0U1 infra and I have tried placing rockstor stg appliance on both my vSAN datastore as well as an OmniOS backed NFS datastore, same result/complaint, any idea how to alleviate/get rid of this error/anomaly?
Is this the snapshot promotion issue, says prune but I saw a previous forum post w/ similar issues? I SWEAR I DID NOT allow either appliance to update so if it was working on ship-date should be still. Took no more upstream appliance updates or manual yum updates.
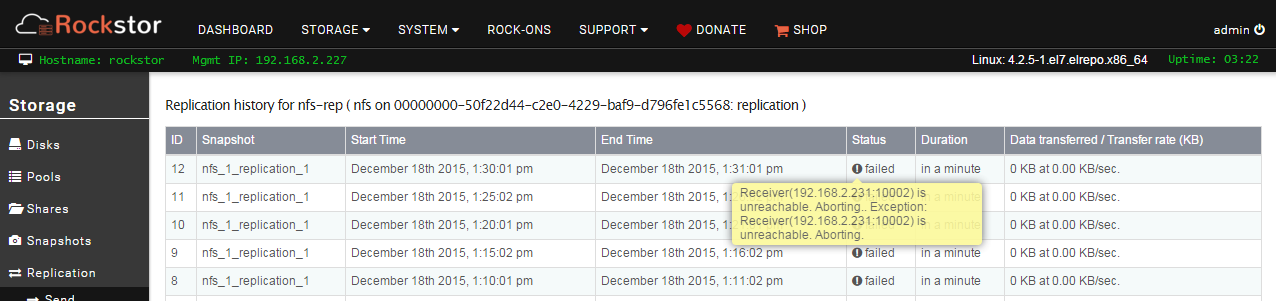
I DO however now see this, why would receiver be unreachable, no FW’s, same subnet, both interfaces I use are marked as I/O but I told rep to use that interface. See any issues w/ this or should I shut down the VM appliances and add a third interface or just let it failback/set to mgmt interfaces?
Think I figured out what I did wrong, had a second vnic on the appliances but told it to use mgmt IP…doh…Re-testing now, will report back shortly w/ success/failure findings.
EDIT: No luv, even tried to swap back to just letting rep go out over default mgmt interfaces.
@whitey Glad to see you’ve made some progress. Got to be quick so will have to be brief. Replication was working but we suspect that some recent upstream updates have upset things as they appeared shortly after the new replication stuff was put in. There is another thread which discusses recent problems in this area and mentions the same error at least at one end as you are getting.
If you refer back to an earlier post of mine in this thread there is an explanation of the Big Red serial warning that I highlighed with a “N.B.” Not being funny just brief (just give the drive a serial number) And in answer to another question of yours I believe the command used to wipe the drive is wipefs. Also in the same N.B. post there is reference to wiping the drives with the rubber icon.
Sorry got to dash now. Well done on persevering and sharing your findings. We are not there yet obviously but I am firmly of the opinion that things are moving in the right direction.
Note that if you have to go through all that badblocks business then things do seem a little strange with your drives.
Thx for the reply but BUMMER that the replication framework has experienced regression.
How long do you think it ‘may’ be before we see that resolved or a new release w/ validated working replication or the framework that replication relies upon to become more robust/resilient to code changes. Do we know what underlying code was affected btw yet? Kernle, btrfs, other interdependent filesystem tools essential to replication?
Blows my mind thta the 3.8-10 release w/ NO updates and no manual yum updates is not working if that one was a known/verified w/ replication working code drop Figure if I tell web UI NOT to update (even if you do it simply tells you you are running latest ver) that we would be good to go and just ‘revision lock’ it that was essentially until upstream issues are identified or resolved.
Oh and as a side note these drives are hitachi/hgst husslbss600’s, typically VERY good drives (ent class, RIDICULOUS PBW stats), had a mix of good/bad luck w/ these, the last three I got seemed to initially throw a fit and NOT wanna work in ANYTHING but an OmniOS stg appliance VM. Linux would throw a fit, FreeNAS would as well (STILL can’t use 3 of the 4 of those disks in FreeNAS as it complains abt being able to lay down a GPT partition/format device). I finally got some time to troubleshoot them and apparently bring them back to life/usable state and decide to run a badblocks pass several times just to make sure they were good. What wiped them or seemed to initially make them visible to my ubuntu LTS utility VM was the dd trick. Although it does seem some OS/stg appliance seem VERY picky w/ previous or unclean disks that may have been used elsewhere…even if you think you clean them it seems to me.
If there is a ‘works everytime w/out a doubt’ way or preferred method I’m all ears. If wipefs /dev/sd* then wipefs -a /dev/sd* works the easiest I can do that in the future.
At the end of the day I got em for $50 each for 100gb slc sas ssd so I ain’t complaining and badblocks comes back silky clean so I am not quite sure what to make of them all in all, seem to be crushing it for now I/O-wise and performing reliably for me (crosses fingers/knocks on wood), all lab/play stuff anyways, critical stuff is still on my tried and true ZFS nas boxes just yet…someday
@whitey, sorry been too busy fighting package dependency fires. Replication is fixed by just-released 3.8-10.02 udpate. Please see my comments here and here and proceed. It should work this time.
And, thanks for detailed posts. Makes it so much better to help
Thanks for the hard work and updating me in this thread suman. I DO however seem to have a knack for making stuff go BOOM.
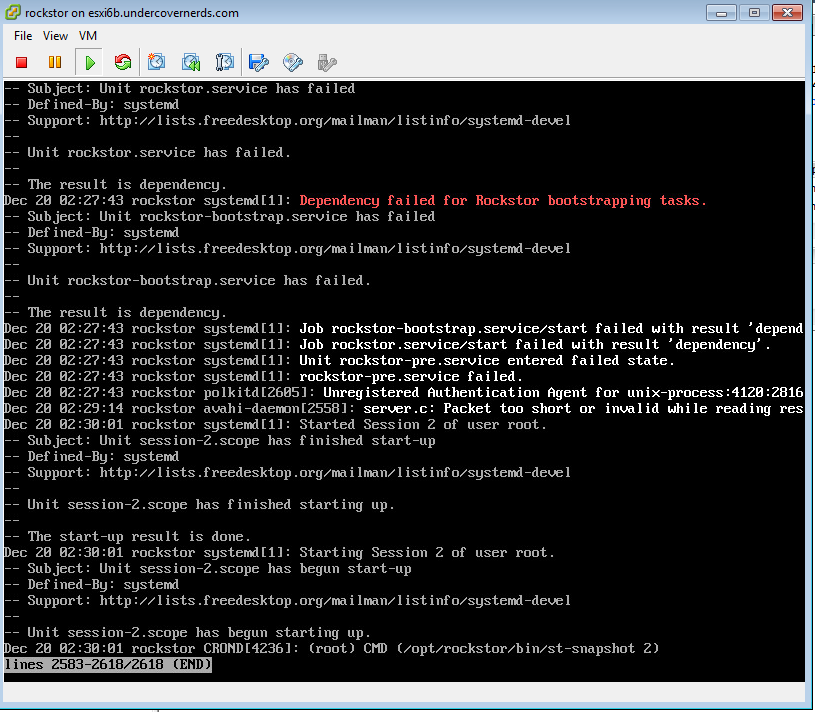
I updated my primary rockstor stg appliance to 3.8-10.02 successfully, rebooted, and now web int won’t load Tried systemctl restart rockstor only to receive these errors. My secondary stg appliance wont even update from 3.8-10 to 3.8-10.02. Must be a bad IT juju day.
@whitey Hello again. To clarify I take it the first two console screen grabs are from the ‘updated but then didn’t start’ machine while the third screen grab is from the Rockstor machine that failed to upgrade.
On the first machine that now has no Rockstor Web UI did you also have python-devel installed. If so
yum remove python-devel
It’s a long shot but just in case, this can block the python downgrade during boot.
What is the output from the following command on each of the machines ie the Python version number.
yum info installed python | grep Release
It should be:-
Release : 18.el7_1.1
If the python downgrade worked, if not then it will be the problematic 34 release. Internally during boot the following command is executed to perform the python downgrade if it finds the 34 release installed.
Well I can see that my rockstor appliances apparently DO not like to have dual interfaces. Had them playing nice, noticed interface forced me to set a DGW on the stg vlan on the second vnic but I didn’t want to as it is stubbed/isolated but I just slapped .1 in anyways to appease rockstor interface. After update and the other one which I have yet to update (you are right first two screenies are primary, third screenie is secondary) it just seems to have lost connectivity out to net, routing table looks fine to me, I added dgw on LAN int that should be able to get to internet/rockstor repo’s/etc. and it is now working so SOMETHING w/ that update borked up my interfaces.
LOL, never a dull day, anyways I think I need to go back to KISS principle for now, re-deploy both appliances, single interface, just bite bullet for now of running mgmt/data over one vnic/vlan, split it out later once I think everything else is solid and I reach replication bliss?
I’ll keep at it gents, you are both gentlemen and scholars! hah






 hahah
hahah