@deigo Hello again, and thanks for copying this to the forum from the support email.
Re:
Well done.
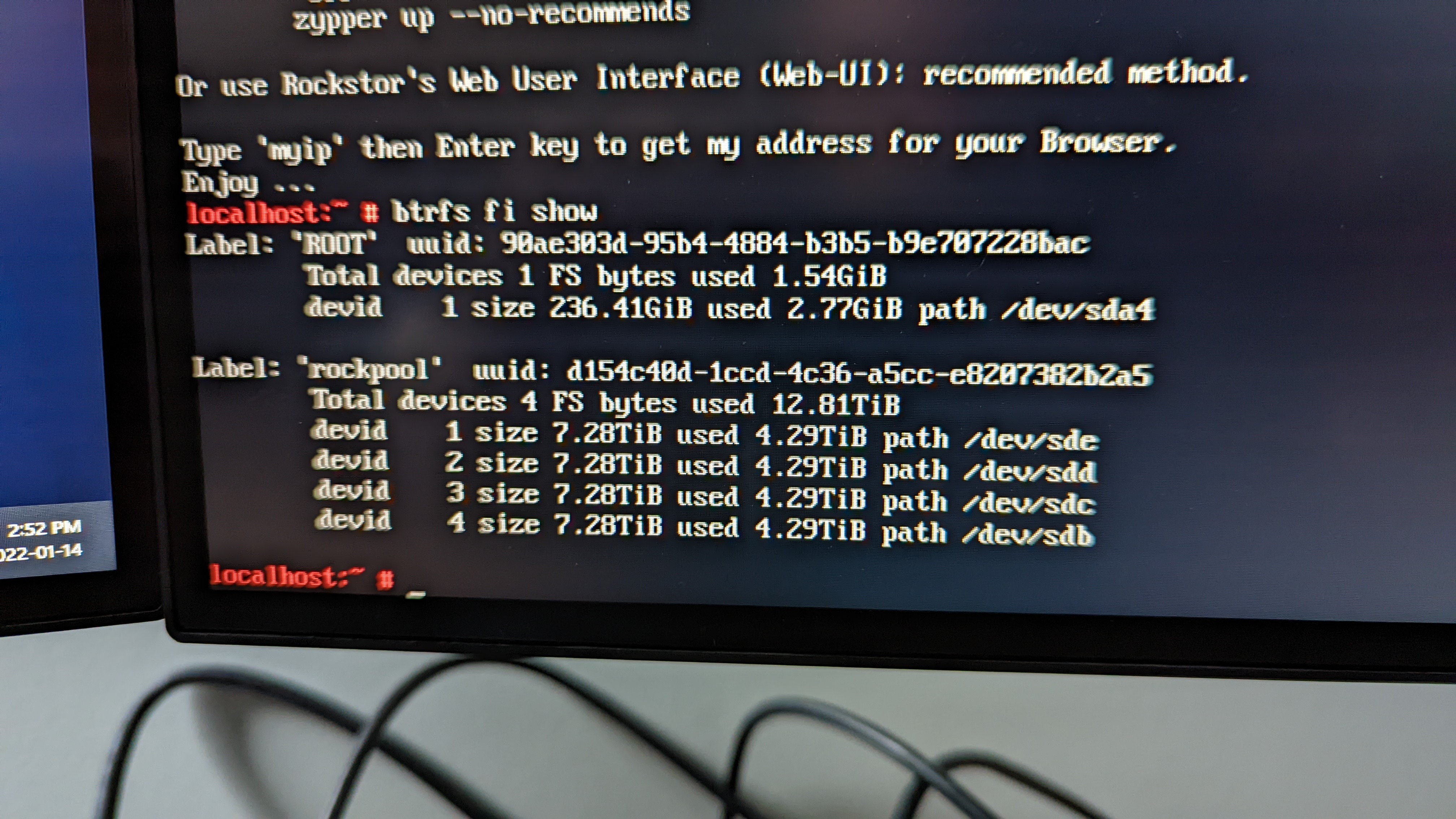
Yes, in our openSUSE Leap 15.3 upstream they have enforced read-only for the parity raid levels of 5 and 6. They are a lot younger than the other raid levels and have not been recommended for production yet. We have this as a warning in our docs and on the later Web-UI. That is why we see the message you have pictured above:
… btrfs: cannot remount RW, RAID56 is supported read-only, load module with allow_unsupported=1
Great. Yes for others reading the root pass is set during the install at the following stage within the installer:
https://rockstor.com/docs/installation/installer-howto.html#enter-desired-root-user-password
Yes, well done. There is often important info on the console. Also note that you can see such messages from within the Log Manager in Rockstor’s Web-UI. Also note the following command:
journalctl
and if you use a " -f" after it you can see live output. Definitely worth looking up if you are interested in such things.
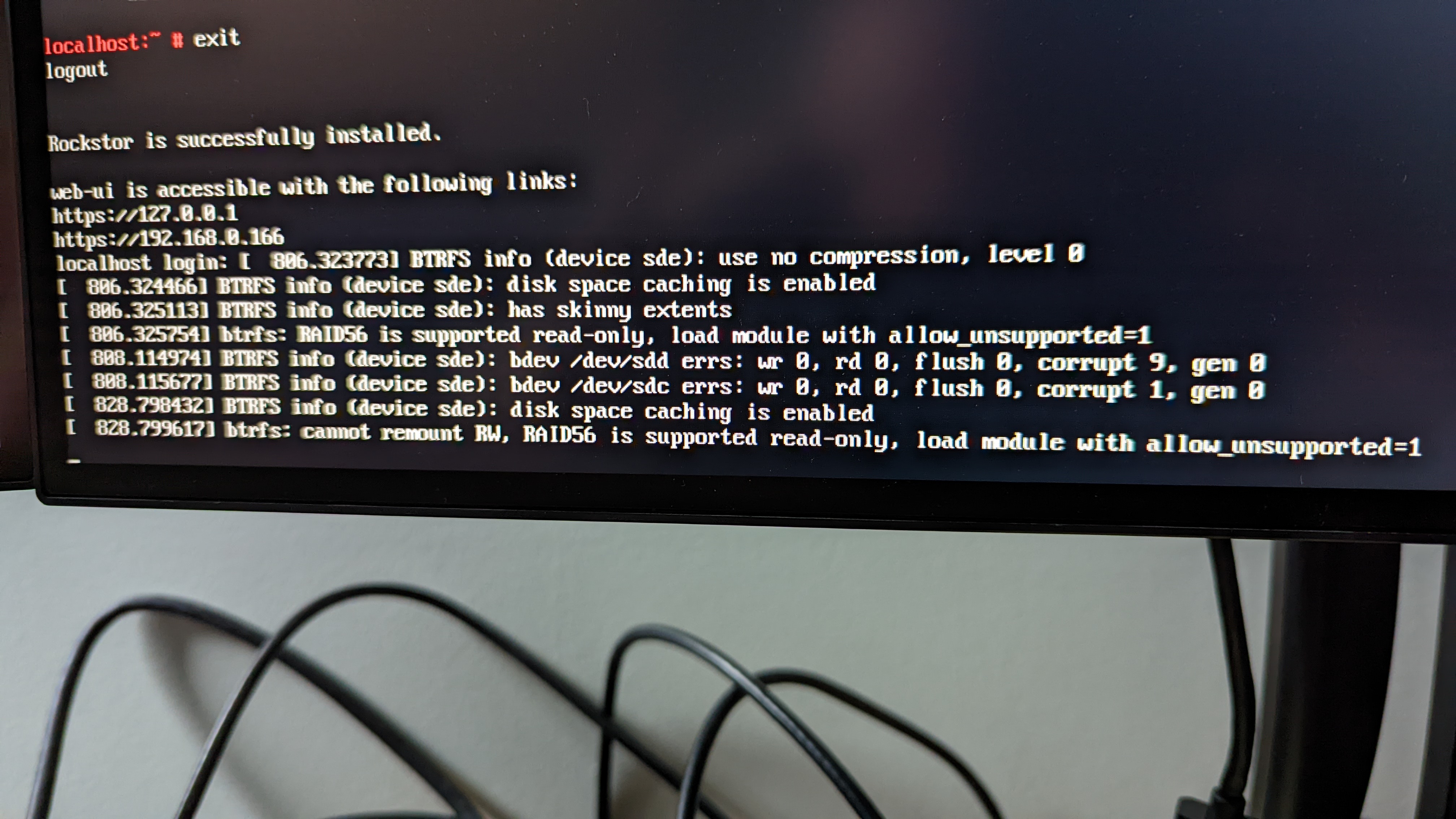
I’m a little surprise it was the same error. And we may be able to get a read-only import by first disabling quotas on this pool via the command line, but we also have the following issues here:
… BTRFS info (device sde): bdev /dev/sdd errs: rw 0, rd 0, flush 0, corrupt 9, gen0
… BTRFS info (device sde): bdev /dev/sdc errs: wr 0, rd 0, flush 0, corrupt 1, gen0
In this report we see how btrfs uses any one of the pool (read btrfs volume) members to reference the whole pool: in this case it’s using device member sde).
But we then have 2 reports of 2 different device member having experienced corruption.
/dev/sdd corrupt 9
/dev/sdc corrupt 1
This is not a good show and unless you have two fault drives we should find the cause.
I would suggest that you ensure your systems memory is good. That can cause corruption.
Take a look at memtest86+ or one of it’s off shoots for this, as anything more we do with this pool or system is at risk if the system memory is fault which is what I suspect here.
The following doc section has a section on testing memory:
Pre-Install Best Practice (PBP) : Pre-Install Best Practice (PBP) — Rockstor documentation
and more specifically the first subsection:
Memory Test (memtest86+) : Pre-Install Best Practice (PBP) — Rockstor documentation
For the next thing we need to do to get you up and running we must first ensure you system memory is good. So you must first do one or ideally two or more complete memory tests using memtest86+ or an offshoot that you can boot from. Our old install has this build in so you can use it from there. Just be sure not to re-install of course.
Let us know how you get on with that as if 2 Pool members have proven corruption it does suggest you memory is faulty. That means anything else we do could make things worse. So check this and if you are lucky/unlucky, depending on how you look at it, you may just be able to remove half the memory and be left with a solid system.
Also be sure to re-seat all sata connections etc as that can lead to similar issues but that would also likely show up in some of the read and write stats.
For now you existing data can rest where it is, but make sure you memory tests good before proceeding as that’s important for our next and likely last step in getting you going again.
Hope that helps and let us know how you get no.