Restart worked to resolve the new Share issue, however I needed to run /opt/rockstor/bin/initrock to get the Web GUI back and now most of the share’s are not mounted
My initial though is that you may just not have enough memory for what you are trying to do here. Are you also running any rock-ons and if so which ones?
From your other recent post on the great hacker build you did you state 2GB of RAM.
If you are also using all of the indicated drives in that build 6 * 3 TB, then you are asking 2GB of 64 bit ram to manage 18 TB’s of storage and to run Rockstor’s Django instance simultaneously. The ZFS folks, our nearest filesystem parallel having check summing, snapshots, and being of a copy-on-write nature, often state a rule of thumb to be 1 GB RAM per TB of storage. I don’t think we quite need that generally but there are issues with more extreme memory use on the generally not recommenced for production parity raid levels of btrfs; ie btrfs raid 5/6. Although this often doesn’t show itself until you come to do a pool repair or balance. I don’t remember you stating which raid level your using on this machine.
Re:
and the fact that a subsequent re-boot, partially relieved the situation very much point to a ram starvation also.
And take care to use a fast enough system drive, as we discussed in our PM chat. Very important for Rockstor or any general purpose enterprise linux based variant that is not read only root.
The following:
May well also be related to memory starvation but could also be caused by time-outs during the execution of the initrock during boot due to a slow system drive. So there’s a couple of things to look to.
I updated my build post and indicated I configured as RAID 10.
Currently, My Dashboard indicates 55% Ram in use, 28% cache and 16% Free.
Before the update to the latest version, the version from the ISO appeared to be mostly stable. However I had noticed that SAMBA was not stable after a couple of days. (Can’t use network shares)
Now with the updates, it appears to be more critical for the OS Storage to be more responsive.
Is there an easy way to migrate from USB to SSD? Can I just clone the drives across?
I’ll be needing to use a PCIe dual SATA card to add this option and I have not used it to boot the system before.
I’ve restarted, working again, I didn’t need to run the command /opt/rockstor/bin/initrock manually this time.
I have two of these xw4600 boxes of different generations (visa / 7). The (7) had problems running Windows and I’ve just worked out it was the SATA Controller.
Hence thinking what would be best use of hardware as I have one PCIe SATA Controller;
*Upgrade Rockstor with SATA controller + system drive that is not USB (+ maybe RAM & CPU) but in turn making the other box unable to be used (no RAM).
OR
*Have a Win 7–>10 PC using SATA controller but only 2GB RAM DDR2. (Uage another OS storage solution for RockStor like USB2.0 to SATA adaptor with Laptop HDD with Similar USB2.0 Performance.)
Definitely, the ISO version was at least a generation or two back and did nothing or near nothing to report pool health and nothing to assist with pool repair. The newer code does quite a lot more and initially was fairly inefficient, during the transition period of adding these capabilities but it now much better than it was. There are some performance issues still but the are relatively insignificant when using anything like a fast USB and are just fine with hdd/ssd.
On a fast enough system drive that no Web-UI time outs will occur as a result of waiting for the drive, an install will take an insignificant amount of time with regard to image and restoring, and should end up being less complicated. So I’d suggest a config backup, download that config backup and then reinstall on the new system disk and import your pool. Then restore the config. It doesn’t do all things but it does do quite a few things. See the following doc sections:
Configuration Backup and Restore: http://rockstor.com/docs/config_backup/config_backup.html
and
Reinstalling Rockstor: http://rockstor.com/docs/reinstall/reinstall.html#
But definitely try a faster system disk than you apparently slow USB key as you are having a lot of ‘random’ issues that could be at least in part down to this. See how you get on and let us know how your experiment go.
This simply means that btrfs had to wait for something for more than 120 seconds which is not expected on adequate hardware.
This is normal. A drive removal is a form of balance that sets the target size of the to-be-removed drive as zero. Hence info is read from that drive but not, generally, written. And over time the read info is re-located on one of the other drives until no info is left where upon it is not longer part of the drive. Rockstor referes to this as an ‘internal’ balance and it currently doesn’t show up in command line balance status so we infer it’s state by watch drives uses stats and report as best we can within the Web-UI.
Hence the following warning preceeding this mechanism from within the Web-UI, assuming you instigated this process from within the Web-UI:
Added in Stable Channel release 3.9.2-49 release Sep 2019:
And given you have reported indicators of hardware ‘hangs’, and major slow downs even when you were not performing a major Pool operation, i.e.:
And the unspecified S.M.A.R.T error of course.
And are also using an overly slow system disk, you are likely to have a rough ride of this.
I suggest you refrain from refreshing the Web-UI and leave the pool re-shape to it’s thing and give it plenty of time to finish before again trying to re-examine things. This situation would be much improved , but not completely removed, by not using a slow system disk.
Also please note that your comment here:
is not my reading of for example:
and:
It does seem now that you do have a number of hardware related issues simultaneously affecting your system so let us know how things pan out.
Incidentally, as a result of your feedback and the misunderstanding that is evident: that one can use a regular (read slow) USB key but it’s just not recommended; I have created the following doc issue:
I’ve suggested there the following additional note be added:
Rockstor cannot work reliable when installed on regular USB keys. Only fast variants, or preferably HDD, SSD class devices, are appropriate.
I’ve also been pondering how we can surface some kind of speed test, I know a recent SBC distro has recently done such a thing, where folks are alerted to them using an inappropriate boot device. In their case it was lower class sdcards I believe. I was thinking of something that simply parsed systemd bootup speeds or the like. Might also help to show up failing system disks as sometimes they just slow down drastically but don’t quite yet trigger such things as your 120 seconds issue within btrfs. Anyway we can update the docs as a first step. And once our openSUSE move is over and done with, look to adding this system boot speed test, or the like.
May I state that the USB 2.0 port has a maximum of 40MB/s of performance.
The USB 3.0 pen drive I used exceeds this speed rating of 40MB/s in tests I had performed prior using it.
I did not extend this test how it would perform from running an OS from it (Random I/O).
" if USB key use only fast variants (16GB+ SSD recommended)."
Assuming I used a SSD via a USB 2.0 port, it will not work faster than the 40MB/s. But there has not been any speed rating to indicate this, just that it should fast. You indicated to be that there is a plan to run a speed test in the future installer with OpenSUSE.
Perhaps decide if 40MB/s is suitiable or not and document it according.
I do plan to change the OS drive when I get time, I now have concerns if the USB 2.0 port is going to give me similar performance limitations. i.e. using a laptop hard drive via the USB 2.0 port.
If the “Balance” is to remove a faulty drive, I don’t understand why it would use it.
It is possible that using it is the source of the array to slow down operations.
If so, consider an option to mark a drive as bad (not to be read from) and fix up the array from the other good drives considering I’m using RAID 10 configuration.
The drive with SMART errors is 3TB and assuming about 100MB/s the full drive should be access over a 8.5 hour period. The drives are faster than this speed on the specification sheet. The Balance operation is still progressing without a progress update about 4 days later.
Overall, I just don’t understand why drives not in the same pool as the operating system affect the operating system performance. (Tehnically I’m not even using the same interface as the drives USB vs SATA).
Looking at “top” load average is typically under 10, I have 70MiB RAM Free, 65MiB Swap used.
the main commands running are: gunicorn & btrfs-trans+ & btrfs (but not all the time) Of 332 tasks about 1-4 are active (Including top) and the rest are sleeping most of the time.
Is there like a Feature table comparison of CentOS vs OpenSUSE to understand the progress of the transition. Would I be better off adopting OpenSUSE now instead of making the hardware change.
I’m afraid I can’t address all of these right now and many have answers already on the forum but lets get this USB key thing out of the way.
Have you seen this post:
quoting further down we have:
I’ll post again the speed tests run there, can you try yours out so we can get a feel for what we are after recommending here:
# SanDisk Extreme USB 3.0 32 GB
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 8.68624 s, 95.5 MB/s
0.00user 1.01system 0:08.68elapsed 11%CPU (0avgtext+0avgdata 2276maxresident)k
0inputs+1619968outputs (0major+114minor)pagefaults 0swaps
/dev/sdc:
Timing cached reads: 27596 MB in 1.99 seconds = 13875.22 MB/sec
Timing buffered disk reads: 790 MB in 3.00 seconds = 262.93 MB/sec
# SanDisk Extreme GO USB 3.1 64GB
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 5.24771 s, 158 MB/s
0.01user 0.39system 0:05.24elapsed 7%CPU (0avgtext+0avgdata 2048maxresident)k
0inputs+1619968outputs (0major+112minor)pagefaults 0swaps
sudo hdparm -Tt /dev/sdc
/dev/sdc:
Timing cached reads: 27664 MB in 1.99 seconds = 13912.05 MB/sec
Timing buffered disk reads: 610 MB in 3.01 seconds = 202.88 MB/sec
# SanDisk Ultra Fit (ID 0781:5583)
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 12.1263 s, 68.4 MB/s
0.00user 0.40system 0:12.12elapsed 3%CPU (0avgtext+0avgdata 2012maxresident)k
0inputs+1619968outputs (0major+109minor)pagefaults 0swaps
/dev/sdc:
Timing cached reads: 27760 MB in 1.99 seconds = 13958.43 MB/sec
Timing buffered disk reads: 418 MB in 3.00 seconds = 139.28 MB/sec
# IS917 innostor 16GB (USB 3.0) more ‘regular’ USB 3.0 key
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 35.1284 s, 23.6 MB/s
0.01user 0.38system 0:35.12elapsed 1%CPU (0avgtext+0avgdata 2144maxresident)k
0inputs+1619968outputs (0major+115minor)pagefaults 0swaps
/dev/sdc:
Timing cached reads: 26472 MB in 1.99 seconds = 13307.74 MB/sec
Timing buffered disk reads: 364 MB in 3.01 seconds = 120.96 MB/sec
# SanDisk Cruzer Fit 16GB (USB 2.0 I think) in USB 3.0 port:
# (ID 0781:5571)
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 150.716 s, 5.5 MB/s
0.00user 0.38system 2:30.71elapsed 0%CPU (0avgtext+0avgdata 2212maxresident)k
0inputs+1619968outputs (0major+113minor)pagefaults 0swaps
sudo hdparm -Tt /dev/sdc
/dev/sdc:
Timing cached reads: 26490 MB in 1.99 seconds = 13315.59 MB/sec
Timing buffered disk reads: 72 MB in 3.04 seconds = 23.70 MB/sec
# And for comparison:
# Crucial MX500 SSD in external Orico USB3.0 caddy.
# (ID 357d:7788 Sharkoon QuickPort XT)
sudo time dd if=Rockstor-3.9.1.iso of=/dev/sdc bs=64k
12656+0 records in
12656+0 records out
829423616 bytes (829 MB, 791 MiB) copied, 3.3814 s, 245 MB/s
0.00user 0.40system 0:03.38elapsed 12%CPU (0avgtext+0avgdata 2204maxresident)k
0inputs+1619968outputs (0major+113minor)pagefaults 0swaps
sudo hdparm -Tt /dev/sdc
/dev/sdc:
Timing cached reads: 26318 MB in 1.99 seconds = 13230.02 MB/sec
Timing buffered disk reads: 806 MB in 3.00 seconds = 268.31 MB/sec
Again quoting the summary of that post we have:
So if your could contribute your finding speed wise by the same measure we can start to establish a ressonable minimum. And as you see from that Dec 19 post the USB port is by far not the limiting factor with some USB2.0 keys, in a USB 3.0 port, managing only 5.5 MB/s write. Hence the recommendation.
An keeping your your USB2.0 port being a restriction for faster divices, that a very good point. Maybe we should add that to our recommendation. I see from:
Section 5.8.4 “Bulk Transfer Bus Access Constraints”
Table 5-10
We are talking, for the bus itself, as you say, 40 to 53 MB/s. But again if some keys are 1/10th of that then the key is still far more important. But 40 MB/s is still a little slow.
So lets add your current device spec (model name) and the same speed tests to that table and we can start to build up an example of keys speeds that are good and less good, and of course bad. I did those tests and posted the results as a way of trying to establish what we are looking for and so if you also post yours we can see if the USB 2.0 port is actually the bottleneck in your case.
Btrfs takes a lot more ‘work’ than the vast majority of other file-systems as it is generally doing a great deal more. This ‘balance’ operation is a generic term and means the pool is re-organising in a fairly major way. And with atomic disk every constituting a number of reads and writes things can take time. It’s a cost of the flexibility. Plus there is no magic here. Also note that not everything shows in top. If a system is irq saturated it’s going to be harder to see that. But I’m no expert but there may be some on the forum that can explain this in more informed detail. But needless to say, one drive on a system can very much affect the rest of the system. Try running a drive with irq / dma issue and see your entire system drop to a crawl. Maybe you have such a drive in your system. But yes the btrfs subsystem, especially in the ‘olden days’ of our CentOS variant, is pretty slow. And yes the btrfs subsystem of our openSUSE variant is significantly faster, which bring me to the following:
Not really as we are attempting to fix all that is reported. But in short almost everything works currently but it’s still buggy. But then so is our CentOS offering. Our main concern though is to arrive at what we are loosely referencing as ‘feature parity or near enough’. And to that end we intend to be ‘there’ in a few weeks time. Hopefully in time for the release of our intended Leap 15.2 final release target. That Leap version is currently at RC stage as of a few days ago.
So if you fancy trying stuff out and reporting in as much detail as you can then it can only help. We are currently in the second release of what we are calling our beta stage of the Built on openSUSE testing channel:
as of 2 days ago.
Lets see some speed tests from that key, but remember the dd test will of course wipe it. But would be good to have an indicator of what speed it was actually capable of in comparison to the others tested there, and to compare it to the USB 2.0 max payload bandwidth of course. Will likely help for us to set our recommended minimum advised speed.
Hope that helps. And I apologise for not answering all of your questions but it may be that you attract others attention / knowledge in this area as we do have quite a few folks on the forum how are way more up on hardware than myself. I’m more jack of a few trades really and rely on contributions from specialists as we go along. But your point on the USB 2.0 limit is definitely an interesting one. Lets see your actual bandwidth results before we right off USB2.0 for the system disk as it’s still very common place on many machines. But we do run a full postgresql database (Django) for our Web-UI functions.
From the discussion above I ran through a few tests with what I have and Posted it as a new thread.
I’m happy to gain some feedback if I had done the tests in the wrong way or not.
From what I’m gathering from your comment above and my test that I have linked to below is that USB 2.0 Interface is not suitiable for Rockstor OS Drive.
As for comparison to the tests above, the Sequential Writing test is the best comparison (Difference being the payload being written, 791MB vs 200MB in my tests.);
The decision I made to use the Drive that I had, was before I had read up on all support topics or had gotten use to using Rockstor. I’d make a different decision going ahead now.
I have concerns as HDD speeds can be very variable also.
I got Fed up waiting over 4 days since I started the drive removal process.
I shutdown the system, the web GUI was unresponsive, so I did this on the local console.
I pull the drive with the SMART errors out, ran tests on the USB Drive (other post).
I also swapped the SATA connections so that I don’t use the eSATA port on the remaining 5 drives. (I think this has helped also).
When I put the system back together without the faulty drive, BTRFS Raid 10 was unable to mount.
This I don’t understand at all ! This is the entire point of RAID 10, is to allow a drive failure and continue operating…
I re-connected the Drive with SMART Errors. I started a BTRFS drive removal.
A side effect of my tests before the SWAP partition on the USB drive is no longer used. (This may have also improved some performance)
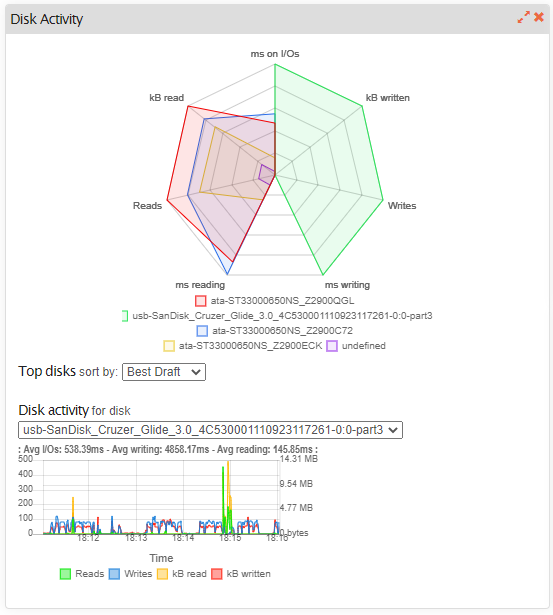
From what I can gather from this graphic is that the RAID-10 Array is reading to some buffer on the USB Drive and every now and again it is flushed to the new locations on the RAID-10 Array.
Over the past 3 hours, the storage used on the faulty drive has reduced by about 3GB, hence I estimate in 38 days I might be able to remove the drive from the BTRFS pool.
I can only assume that the past 4 days about 84GB was removed from the BTRFS pool on the Faulty drive, essentially not a huge improvment.
The main difference is that the Web GUI is mostly browsable now. (Rock-ons and SAMBA Shares don’t work in both cases.)
I’m attempting the OpenSUSE Leap 15.1-1 installation.
The hardware changes is that now I’m using an OCZ 120GB SSD for OS and its connected via the eSATA port.
The 3TB HDD Drive with S.M.A.R.T. Errors is connected via USB 2.0 SATA Adaptor.
I figured that even though I wanted a 6 bay array, a failing drive leaves me currently with 5 drives and I need the 6th connected or the array appears to fail to mount.
Ideally if BTRFS support has improved, removing the drive should occur quicker on OpenSUSE.
If it has not changed much, the facts the system drive is an SSD should at least progress it faster.
The CentOS is still intact on the USB Drive should I need to switch back…
If Server Transactional mode gets supported, it would ideally allow me to use a USB Drive for OS and get back to a SATA only 6-bay HDD array.
After verifying that the RAID 10 works with 1 drive connected via USB to SATA Adaptor in CentOS
I was unable to use the same configuration in OpenSUSE Leap, the USB attached Drive indicated as removed (Now thinking about it, it could have been the USB 2.0 Adaptor’s fault (as in it is not compatiable with OpenSUSE) ). I was still unable to mount the “degraded” array without this drive.
Also, using the eSATA port for the OCZ SSD did not boot by default in this HP, however I could Boot when selecting the boot drive (F9) to boot via HDD. (Not an Ideal solution.)
I was unable to fully boot using the USB 2.0 SATA Adaptor (Stalled before log-in prompt).
Now I have the OCZ SSD connected via a USB3.0 SATA Adaptor on the USB2.0 port.
The Rock-ons did not migrate and hence I needed to re-install them.
I created new Shares on the SSD Pool for all the Rock-ons and their configuration data.
The aim was to;
Allow SSD Speed of access to these Rock-ons (if I move to a SATA connected device)
Allow the HDDs to Spin Down and Save power when not in use
Give the Rock-on Share names that would group them for their purpose (i.e. RCKNS-Cnfg-Muximux)
I also needed to re-create the SAMBA Shares.
Now this is all working as it was before. I thought I would give this Drive removal process a go again.
I’ve started the process of removing the drive and I can see that there is activity of this occuring, however unlike before the Web UI is still responsive and I’m still able to use SAMBA Shares.
Also the drive removal process is occuring much faster than previously.
In the Past 30 mins the allocated capacity on the drive being removed has changed from 918GB --> 870GB. Hence the Drive should be removed in about 9 hours from now.
@b8two I can chip in here just quickly on this one:
Btrfs defaults to not mounting a Pool (Rockstor speak or Volume in btrfs speak) if it is what is know as degraded, i.e. has a member device missing. As from around mid 2019 Stable update channel versions of Rockstor attempt to guide you through such events and flag, in red in the header of all pages (added in mid 2018) that a pool has a missing device and indicate the specific pool that has a missing dev. The Pool details page then offers a “maintenance required” advice section which talks one through adding the required degraded mount option, after first advising a backup via a degraded ro option to play safe.
See the following pull request from around that time which was instrumental in adding some of this stuff:
The images there show the “Maintenance required” section and the Disks (Some Missing) type indicators.
The header warning, again only in Stable updates on CentOS side, were added via the following issue:
In this respect, that of requiring intervention when degraded, btrfs is rather unusual but it’s the current default established by the developers and I think the idea is that in such a case one needs to make an informed decision as to what to do. So the filesystem / dev management / simply refuses to mount. But Rockstor’s Web-UI does, at least try to, guide one through this scenario.
Your probably right on that one. They can be somewhat tricky on occasions. Some will pass their own serial while others will pass non or the real drives serial.
See previous note re degraded mount option requirement.
I’ve seen similar fussy bios arrangements where a system will simply flat out refuse to boot a device auto but will if pointed. Recently when I last came across this I found that changing the order of the associated cards (in my case the problem device was an msata-to-pci adapter) within the pci bus (used a different pci slot) ended up allowing the problem device to boot auto just fine. Always worth trying a bios update in these circumstances. In my case it wasn’t possible as was no longer supported given it was an old machine.
Thanks again for sharing your experimental findings here. The drive removal issue has been a ‘heavy’ task for a long time now and I think we could help by offering say a read only option for example. But given we are now only just inheriting a new btrfs stack via our openSUSE move we just haven’t had the time to improve out side of things there.
The following is also on the road map:
But again, we need to offer an installer for the openSUSE Leap 15.2 variant first. Then we can get back to improving our own side of things as the btrfs stack, and it’s official upstream support, takes priority over everything we do and we have clearly failed in the past to maintain our own ‘picks’ of kernels: hence the openSUSE move.
Chuffed to see you are making progress and thanks again for sharing your findings. There are literally hundreds of backports to the openSUSE kernels on the btrfs side alone and given the have a load of btrfs developers ‘on staff’ they are really our best options to look after such things.
I say you let this current ‘internal’ balance play out as they are particularly tricky, hence the internal name given by Rockstor as they don’t even show up as balances via the balance status command. And do very much tend to drag a system down. Also, as they don’t show up via status command, are a tickly one for us to recognise and surface. They also run at a super high priority and will block many other system events if they are at all compromised themselves. Your reports have been very interesting.
As a side note, why did you choose Leap 15.1 and not Leap 15.2 RC for your experiments? The both have tones of btrfs backports but Leap 15.2 RC has a far newer base kernel and is our main focus for the pending re-launch.
Thanks again for sharing your finding. Much appreciated. Rockstor itself does still have some major usability issues but we are, if slowly, working our way through them. And an every more capable/robust base certainly helps in that.
That’s a bit more like it . There have been some major speed improvements in the btrfs stack of late as well, even enough to consider running quotas on larger pools. And we have some older tec of our own to tend to so we are just better at dealing with all this stuff, i.e. Python 3 async and Django channels 2 stuff should help us some. But bit by bit unfortunately and we of course want to keep serving a subscribers while making all these changes so it’s a tricky balance really.
Your notes about using OpenSUSE indicated that I could use 15.1.
I choose Leap 15.1 simply due to it being easy to find to download on their website.
(A link to follow from your wiki would help otherwise. Sorry if I missed it.)
I figured that the next release 15.2 would be an upgrade and not too far off from now.
I saw a Red warning about the degraded RAID but it was not clickable and not clear without reading documentation how to proceed.
Earlier in this thread the screenshot of the Completed screen of a resize / Change RAID level for Pool, indicating that it will take several hours to complete. May I suggest that notes like this should be displayed prior to committing to the action?
It also indicates that the progress of the drive removal will progressively reduce the Allocated space, perhaps the monitoring part of the “Balance” operation status could Map the current GB as 0% and as it aproaches 0GB it scales up to 100% completed.
Also there is no indication of when a operation ends (time stamp).