@phillxnet Hello, and thanks for your assistance, again. Concurrent development and support are hard to balance, so kudos to you and the rest of the Rockstor team. I am a member a a 5 person analytics team, so I can relate. Hopefully I can give enough information to help you or other forum members point me in the right direction here.
You are correct, I did have a suspected failing system disk. I replaced the system disk, and upgraded the processor in my NAS box before adding the 4th disk to my RAID0 pool. I realize that RAID0 is much less safe than RAID1, and my intent was to move to RAID1 now that I have enough storage capacity to trade for redundancy. These Hitachi drives are NAS rated, and my home NAS is put through very light workloads, so I would be surprised if I was suffering a disk failure in the Pool.
When I installed the new system disk, I did a fresh install from ISO. However, when I enabled stable updates and got up to the most recent release, I started having the same symptoms as before: very slow response and GET/POST errors in the UI when loading any page or performing any operation. I can try to update again, but I wanted to get the appliance back up and running before dealing with the update issues. After a reinstall I was able to get backups completed from all of my devices, so now I am in the process of expanding the Pool and moving to RAID1. Do you still recommend updating Rockstor before anything else?
Here is some output to chew on:
[root@rockstor ~]# btrfs dev stats /mnt2/homeshare
[/dev/sda].write_io_errs 0
[/dev/sda].read_io_errs 0
[/dev/sda].flush_io_errs 0
[/dev/sda].corruption_errs 0
[/dev/sda].generation_errs 0
[/dev/sdb].write_io_errs 0
[/dev/sdb].read_io_errs 0
[/dev/sdb].flush_io_errs 0
[/dev/sdb].corruption_errs 0
[/dev/sdb].generation_errs 0
[/dev/sdc].write_io_errs 0
[/dev/sdc].read_io_errs 0
[/dev/sdc].flush_io_errs 0
[/dev/sdc].corruption_errs 0
[/dev/sdc].generation_errs 0
[/dev/sdd].write_io_errs 0
[/dev/sdd].read_io_errs 0
[/dev/sdd].flush_io_errs 0
[/dev/sdd].corruption_errs 0
[/dev/sdd].generation_errs 0
[root@rockstor ~]# ls -la /dev/disk/by-id
total 0
drwxr-xr-x 2 root root 280 Nov 17 16:55 .
drwxr-xr-x 6 root root 120 Nov 17 16:55 …
lrwxrwxrwx 1 root root 9 Nov 17 16:55 ata-Hitachi_HUA723020ALA641_YFGRZTHA -> …/…/sda
lrwxrwxrwx 1 root root 9 Nov 17 16:55 ata-Hitachi_HUA723020ALA641_YGG3KZEA -> …/…/sdc
lrwxrwxrwx 1 root root 9 Nov 17 16:55 ata-Hitachi_HUA723020ALA641_YGHH5YGA -> …/…/sdb
lrwxrwxrwx 1 root root 9 Nov 17 16:55 ata-Hitachi_HUA723020ALA641_YGJ0DGSA -> …/…/sdd
lrwxrwxrwx 1 root root 9 Nov 17 16:55 ata-Maxtor_6L160P0_L327KL3G -> …/…/sde
lrwxrwxrwx 1 root root 10 Nov 17 16:55 ata-Maxtor_6L160P0_L327KL3G-part1 -> …/…/sde1
lrwxrwxrwx 1 root root 10 Nov 17 16:55 ata-Maxtor_6L160P0_L327KL3G-part2 -> …/…/sde2
lrwxrwxrwx 1 root root 10 Nov 17 16:55 ata-Maxtor_6L160P0_L327KL3G-part3 -> …/…/sde3
lrwxrwxrwx 1 root root 9 Nov 17 16:55 wwn-0x5000cca223ca73bf -> …/…/sda
lrwxrwxrwx 1 root root 9 Nov 17 16:55 wwn-0x5000cca224c1a09d -> …/…/sdc
lrwxrwxrwx 1 root root 9 Nov 17 16:55 wwn-0x5000cca224d4ff68 -> …/…/sdb
lrwxrwxrwx 1 root root 9 Nov 17 16:55 wwn-0x5000cca224dc5dd7 -> …/…/sdd
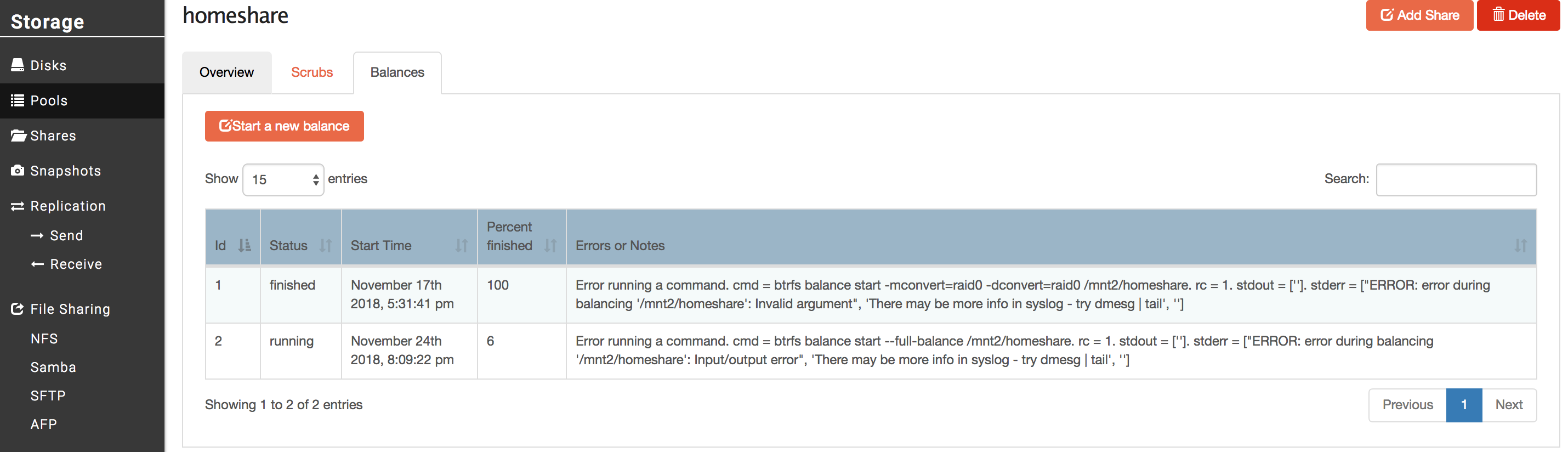
[root@rockstor ~]# btrfs balance status /mnt2/homeshare
Balance on ‘/mnt2/homeshare’ is running
85 out of about 890 chunks balanced (86 considered), 90% left
[root@rockstor ~]# btrfs fi show
Label: ‘rockstor_rockstor’ uuid: 3ee753c6-4ba9-4831-a0e2-05cbb009598a
Total devices 1 FS bytes used 2.60GiB
devid 1 size 144.43GiB used 5.04GiB path /dev/sde3
Label: ‘homeshare’ uuid: 67ca3f52-4b5a-4d7c-894f-8564066e9d4a
Total devices 4 FS bytes used 2.87TiB
devid 1 size 1.82TiB used 887.22GiB path /dev/sda
devid 2 size 1.82TiB used 887.22GiB path /dev/sdb
devid 3 size 1.82TiB used 887.22GiB path /dev/sdc
devid 4 size 1.82TiB used 287.50GiB path /dev/sdd
[root@rockstor ~]# btrfs fi usage /mnt2/homeshare
Overall:
Device size: 7.28TiB
Device allocated: 2.88TiB
Device unallocated: 4.40TiB
Device missing: 0.00B
Used: 2.87TiB
Free (estimated): 4.40TiB (min: 4.40TiB)
Data ratio: 1.00
Metadata ratio: 1.00
Global reserve: 512.00MiB (used: 8.09MiB)
Data,RAID0: Size:2.87TiB, Used:2.87TiB
/dev/sda 885.00GiB
/dev/sdb 885.00GiB
/dev/sdc 885.00GiB
/dev/sdd 287.00GiB
Metadata,RAID0: Size:7.06GiB, Used:5.88GiB
/dev/sda 2.19GiB
/dev/sdb 2.19GiB
/dev/sdc 2.19GiB
/dev/sdd 512.00MiB
System,RAID0: Size:96.00MiB, Used:208.00KiB
/dev/sda 32.00MiB
/dev/sdb 32.00MiB
/dev/sdc 32.00MiB
Unallocated:
/dev/sda 975.80GiB
/dev/sdb 975.80GiB
/dev/sdc 975.80GiB
/dev/sdd 1.54TiB
[root@rockstor ~]# btrfs dev usage /mnt2/homeshare
/dev/sda, ID: 1
Device size: 1.82TiB
Device slack: 0.00B
Data,RAID0: 598.00GiB
Data,RAID0: 287.00GiB
Metadata,RAID0: 1.69GiB
Metadata,RAID0: 512.00MiB
System,RAID0: 32.00MiB
Unallocated: 975.80GiB
/dev/sdb, ID: 2
Device size: 1.82TiB
Device slack: 0.00B
Data,RAID0: 598.00GiB
Data,RAID0: 287.00GiB
Metadata,RAID0: 1.69GiB
Metadata,RAID0: 512.00MiB
System,RAID0: 32.00MiB
Unallocated: 975.80GiB
/dev/sdc, ID: 3
Device size: 1.82TiB
Device slack: 0.00B
Data,RAID0: 598.00GiB
Data,RAID0: 287.00GiB
Metadata,RAID0: 1.69GiB
Metadata,RAID0: 512.00MiB
System,RAID0: 32.00MiB
Unallocated: 975.80GiB
/dev/sdd, ID: 4
Device size: 1.82TiB
Device slack: 0.00B
Data,RAID0: 287.00GiB
Metadata,RAID0: 512.00MiB
Unallocated: 1.54TiB
A couple of observations on the command line output above: 1) system datetime appears to be off…not sure how 2) all the disks seem to be error-free, so that is good 3) it appears the balance operation is ongoing and 10% complete.
Given these observations, should I just let it keep running and hope it completes successfully this time, or should I go ahead and try to get updated to the latest stable release and then complete the balance? Thanks in advance for any thoughts!