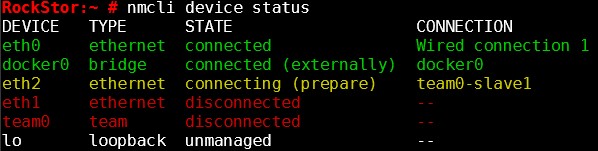
Brief description of the problem
Hi, I’m trying to get LACP working on my RockStor with a double ethernet ports card based on Intel V-226. Mind you, the ethernet connections work perfectly separately. Creating an 802.3ad bond works perfectly too.
When creating a team LACP connection, I get an error message copied below. I looked it up but couldn’t find anything I can comprehend to fix it myself. Does anyone understand what is going on?
Also, as a sidenote, there’s someone that had a similar problem to me but his solution was the updated RockStor 4.0.9 which fixed it. I run the 4.5.5.0 version already, and my switch supports LACP.
Detailed step by step instructions to reproduce the problem
In Network options, I click on “Add a connection”, then I create a “team” connection with the “LACP” option, using the two devices available as eth1 and eth2. I get the error whether I’ve activated an LACP aggregation on my switch or not.
Error Traceback provided on the Web-UI
Houston, we've had a problem.
Error running a command. cmd = /usr/bin/nmcli c up Team-slave-0. rc = 4. stdout = ['']. stderr = ['Error: Connection activation failed: A dependency of the connection failed', "Hint: use 'journalctl -xe NM_CONNECTION=b62782bc-ee55-429d-9165-fc3bd6495d84 + NM_DEVICE=eth1' to get more details.", '']
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/network.py”, line 342, in post
search_domains,
File “/opt/rockstor/src/rockstor/system/network.py”, line 405, in new_team_connection
new_member_helper(name, members, “team-slave”)
File “/opt/rockstor/src/rockstor/system/network.py”, line 373, in new_member_helper
run_command([NMCLI, “c”, “up”, mname])
File “/opt/rockstor/src/rockstor/system/osi.py”, line 227, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/bin/nmcli c up Team-slave-0. rc = 4. stdout = [‘’]. stderr = [‘Error: Connection activation failed: A dependency of the connection failed’, “Hint: use ‘journalctl -xe NM_CONNECTION=b62782bc-ee55-429d-9165-fc3bd6495d84 + NM_DEVICE=eth1’ to get more details.”, ‘’]