Perhaps none of what this post was about matters. I thought OK I have enough info to know the Raid6 I am running should get the testing update path. So I tried that to see if I could get rockstor to tell me there is a problem with the not mounted pool that was not giving errors any longer. Started update and got.
Unable to check update due to a system error: (Error running a command. cmd = /usr/bin/rpm --import /opt/rockstor/conf/ROCKSTOR-GPG-KEY. rc = 1. stdout = [‘’]. stderr =
[“error: can’t create transaction lock on /usr/lib/sysimage/rpm/.rpm.lock (Resource temporarily unavailable)”, ‘error: /opt/rockstor/conf/ROCKSTOR-GPG-KEY: key 1 import failed.’, ‘’]).
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/storageadmin/views/command.py”, line 262, in post
return Response(rockstor_pkg_update_check(subscription=subo))
File “/opt/rockstor/src/rockstor/system/pkg_mgmt.py”, line 323, in rockstor_pkg_update_check
switch_repo(subscription)
File “/opt/rockstor/src/rockstor/system/pkg_mgmt.py”, line 241, in switch_repo
run_command([RPM, “–import”, rock_pub_key_file], log=True)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 227, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/bin/rpm --import /opt/rockstor/conf/ROCKSTOR-GPG-KEY. rc = 1. stdout = [‘’]. stderr =
[“error: can’t create transaction lock on /usr/lib/sysimage/rpm/.rpm.lock (Resource temporarily unavailable)”, ‘error: /opt/rockstor/conf/ROCKSTOR-GPG-KEY: key 1 import failed.’, ‘’]
So fun, Now what? No gui options return anything resembling the option chosen. LOL fml
Old heading.
How to mount pool, locate failing drive, replace it and upgrade another drive
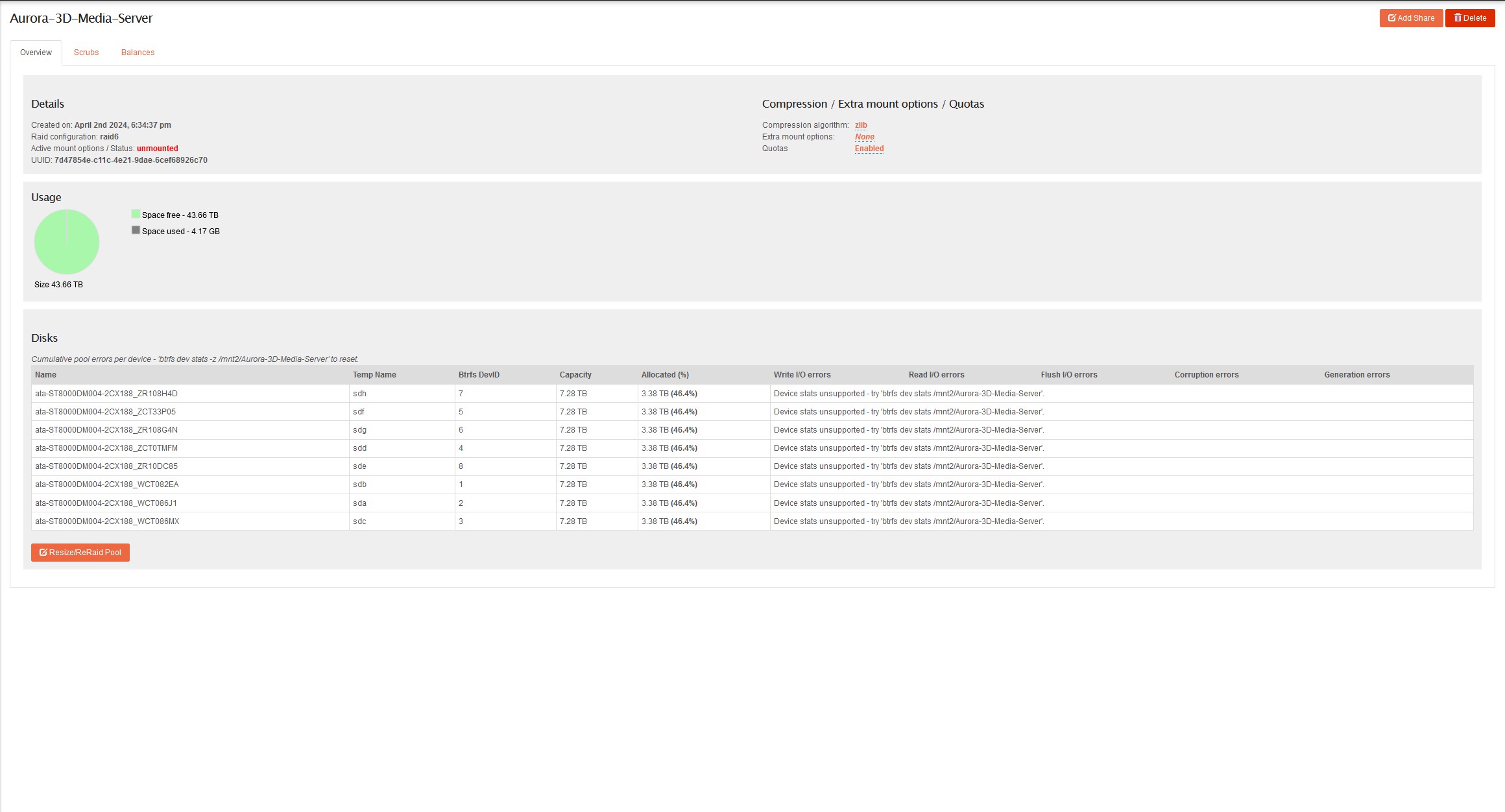
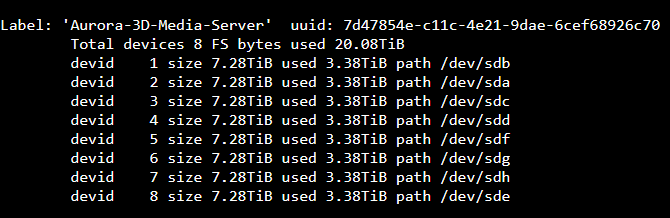
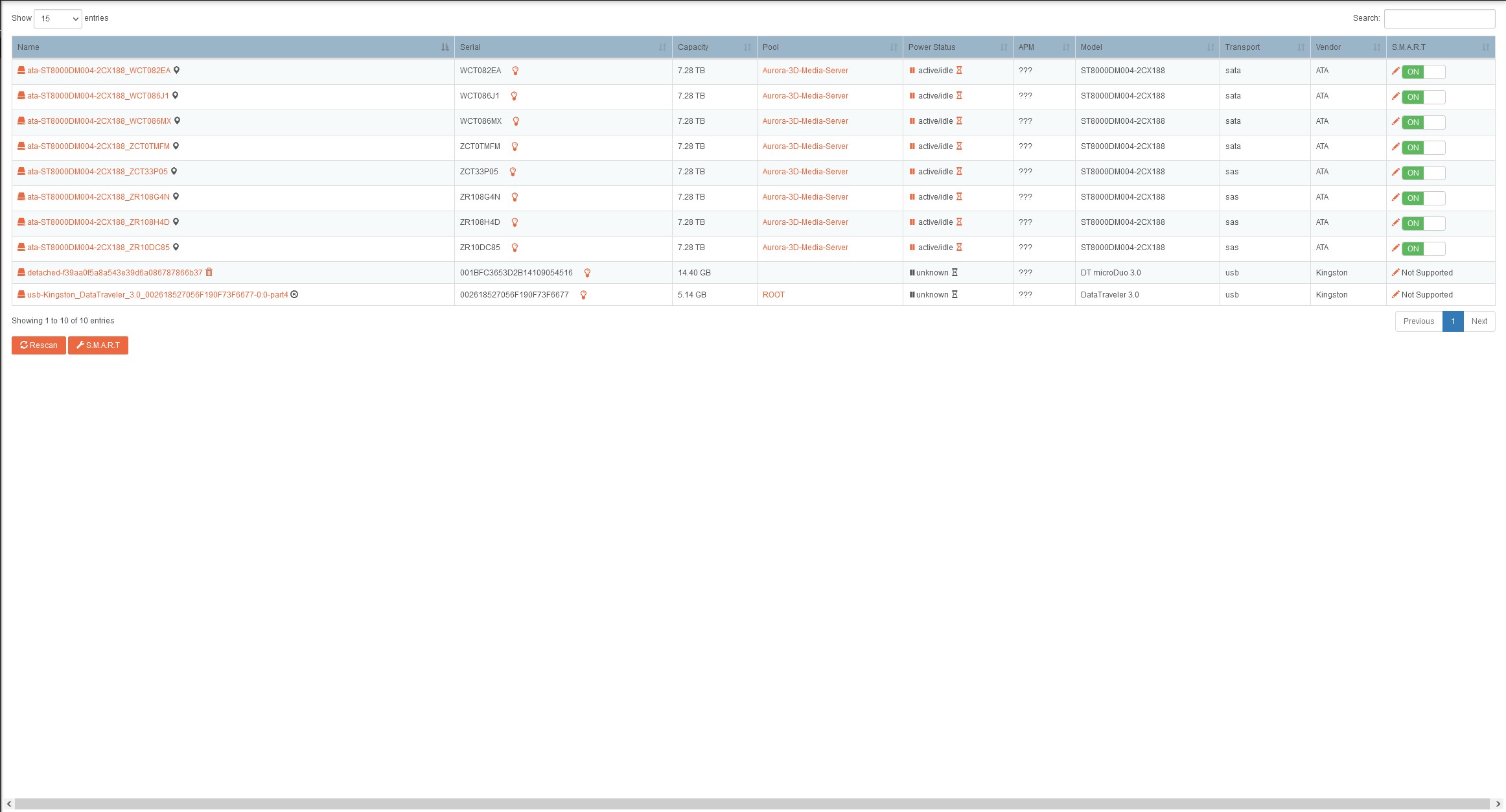
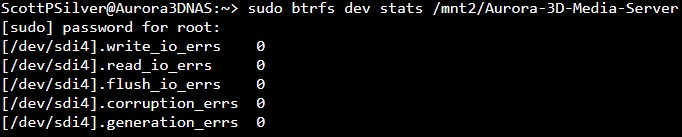
Hello and thanks for being willing to teach a young dog new tricks. Replacement disk is slow-boating to Alaska along with two others to upgrade working drives. I have been searching and reading like a mad man but most of what I find is old, or written by folks that know more of the basics so nothing is elaborated on. First off Is there a recent guide I can follow to locate the bad disk and remove/replace it and I just haven’t found it?. My pool has enough space to operate without this disk and with the comments in quite a few posts, it sounds like I can just pull the disk and resilver or re-balance without a replacement, no? I would love to remove it now in order to bring it back online and add in the new one’s when they arrive. Thanks again and looking forward to figuring this OS out. I am missing the degraded pool warnings thus all the neat features I am reading about are not revealing themselves so I guess I am stuck searching for now.
System:
Current Mobo: GIGABYTE GA-78LMT-USB3 R2 AMD 760G USB 3.1 HDMI Micro ATX Motherboard
Current CPU: AMD CPU FX Series FX-4100 Quad Core CPU 3.6GHz Socket AM3+
Current Memory: Team Group TED38G1600C11BK 32GB 8GB x 4 DDR3 1600mhz Kit
Power Supply: Unable to locate purchase online. EVGA 500W
System drive: Kingston data Travler DT50 16GB
Storage drives: Seagate Barracuda Compute Model# ST8000DM004 8TB 5400rpm x 8
Case: GIGABYTE 3D AURORA GZ-FSCA1-ANB Black Aluminum ATX Full Tower
Rockstor Setup: Linux: 6.5.1-lp154.2.gc181e32-default Opted for Raid 6 I have chosen an update path of test as I am running Raid6 I have started a stable updates sub to support the cause.